这篇博文将基于AWS服务构建日志分析解决方案,对EKK架构进行实践,参考文档。
Amazon Elasticsearch Service 是一项完全托管的服务,方便您部署、保护和运行大量 Elasticsearch 操作,且不用停机。该服务提供开源 Elasticsearch API、受托管的 Kibana 以及与 Logstash 和其他 AWS 服务的集成,支持您安全获取任何来源的数据,并开展实时搜索、分析和可视化。使用 Amazon Elasticsearch Service 时,您只需按实际用量付费,没有预付成本或使用要求。有了 Amazon Elasticsearch Service,您无需承担运营开销,便可获得所需的 ELK 堆栈
一个来自Eddie Xie关于Elasticsearch的系列教程:https://kalasearch.cn/blog/elasticsearch-tutorial/
Amazon Kinesis 可让您轻松收集、处理和分析实时流数据,以便您及时获得见解并对新信息快速做出响应。Amazon Kinesis 提供多种核心功能,可以经济高效地处理任意规模的流数据,同时具有很高的灵活性,让您可以选择最符合应用程序需求的工具。借助 Amazon Kinesis,您可以获取视频、音频、应用程序日志和网站点击流等实时数据,也可以获取用于机器学习、分析和其他应用程序的 IoT 遥测数据。借助 Amazon Kinesis,您可以即刻对收到的数据进行处理和分析并做出响应,无需等到收集完全部数据后才开始进行处理。
Kibana 是一种开源数据可视化和挖掘工具,可以用于日志和时间序列分析、应用程序监控和运营智能使用案例。它提供了强大且易用的功能,例如直方图、线形图、饼图、热图和内置的地理空间支持。此外,它还提供了与 Elasticsearch 的紧密集成,后者是一款流行的分析和搜索引擎,这使得 Kibana 成为了可视化 Elasticsearch 中存储数据的默认之选。
文档的架构图:
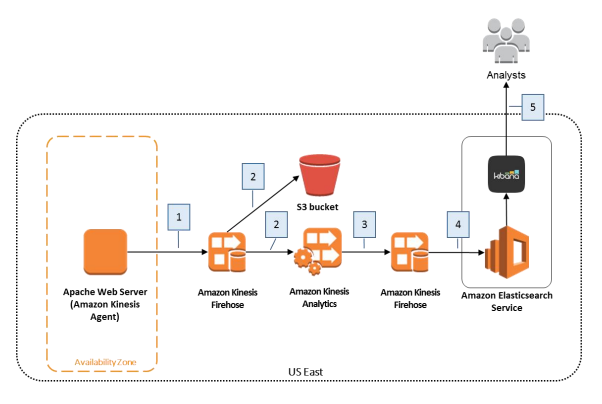
步骤:
创建一个EC2,使用免费的配置即可,有IAM role权限分配好role,没有也无所谓,AMI我选的是ubuntu 18.04。
创建第一个Amazon Kinesis Firehose Delivery Stream
- 名字为web-log-ingestion-stream
- destination为s3,桶名也可以为web-log-ingestion-stream
- prefix(可选)
- IAM role,选择Create/Update Existing IAM Role
- 跳出一个新面板
- IAM role name为 firehost_delivery_role
在EC2上安装Amazon Kinesis Agent
- 具体文档为https://docs.aws.amazon.com/zh_cn/firehose/latest/dev/writing-with-agents.html#download-install
- 使用github进行安装
git cloen https://github.com/awslabs/amazon-kinesis-agent.git cd amazon-kinesis-agentsudo ./setup --install
对于java版本问题解决见这篇博客
日志准备
- 使用github上的脚本
- 经过多次测试,为了保证实验进行必须使用无限日志生成的命令,即
python apache-fake-log-gen.py -n 0 -o LOG
配置Amazon Kinesis Agent
- 打开配置文件
vi /etc/aws-kinesis/agent.json - 模板如下,其中full-path-to-log-file修改为日志文件所在目录,name-of-delivery-stream修改为上述firehost名字
- 如果EC2没有配置IAM role,需要加入awsAccessKeyId和awsSecretAccessKey
- 注意修改部署的区域
- 如果不是apache logs需要把预处理部分dataProcessingOptions删除
- 打开配置文件
1 | { |
启动服务aws-kinesis-agent
- 启动命令
sudo service aws-kinesis-agent start - 状态查看
sudo service aws-kinesis-agent status - 系统启动时自动启动代理
sudo chkconfig aws-kinesis-agent on - 日志查看
cat /var/log/aws-kinesis-agent/aws-kinesis-agent.log - 此时应该可以在桶web-log-ingestion-stream中看到日志文件,或者在firehose的web-log-ingestion-stream流中监听到变化,如果有数据进入stream但是桶没有日志文件就是firehose的s3权限问题。
- 启动命令
创建Amazon Elasticsearch Service Domain
- 名字为web-log-summary
- 版本使用6.8,7.1会无效
- 使用测试或开发,不需要多个可用区
- EC2选择低配如m3.medium.elasticsearch即可
- 对于network可以选择public,因为VPC比较麻烦
- 但是对于access policy最好不要选择allow open access to the domain,可以选择allow or deny access to one or more AWS accounts or IAM users,然后填上自己的账号,为了可视化访问,填上Allow access to the domain from specific IP(s),填上自己的ip(可以从https://ipaddress.com/ip-lookup)查到。
创建第二个Amazon Kinesis Firehose Delivery Stream
- 名字为web-log-aggregated-data
- destination为Amazon Elasticsearch Service,选择上述创建的domain即web-log-summary
- index为request_data,type为requests
- 对于s3可以创建一个新桶,桶名也可以为web-log-aggregated-data
- 对于IAM role选择Create/Update Existing IAM Role,然后选择firehost_delivery_role并创建新policy
创建 Amazon Kinesis Analytics Application
名字为web-log-aggregation-tutorial
创建后选择Connect to a source,选择已有firehose delivery stream为weblog-ingestion-stream
- 可以看到类似的表
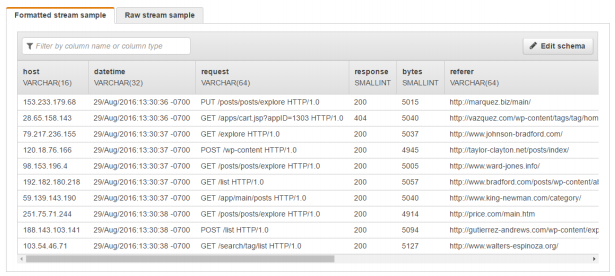
- 创建SQL分析数据
- 点击 Go to SQL editor,选择Yes, start application
- 等待一段时间后,一些样本数据会展现出来
- 在SQL编辑器中输入并点击Save and run SQL
1 | CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( |
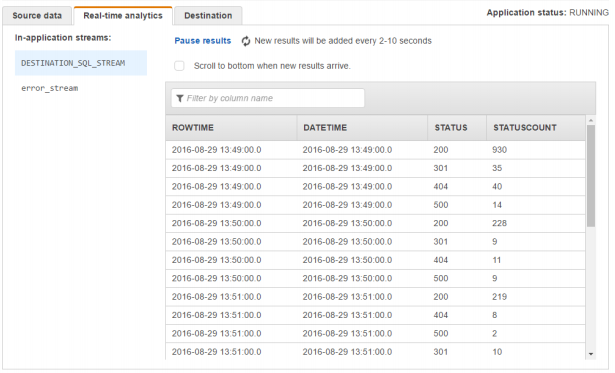
最后在Destination分页在 Select a stream中,选择web-log-aggregated-data,保存继续
- 数据可视化
- 在Amazon Elasticsearch Service Domain面板中选择web-log-summary,通过点击Kibana可以进入到该页面,如果不允许匿名访问就修改配置允许自己的IP以访问。
- 在Kibana面板的Managemant中找到Index Patterns,输入request_data,选择field为DATETIME,完成创建。
- 在Visualize中选择line chart,选择request_data,配置如下
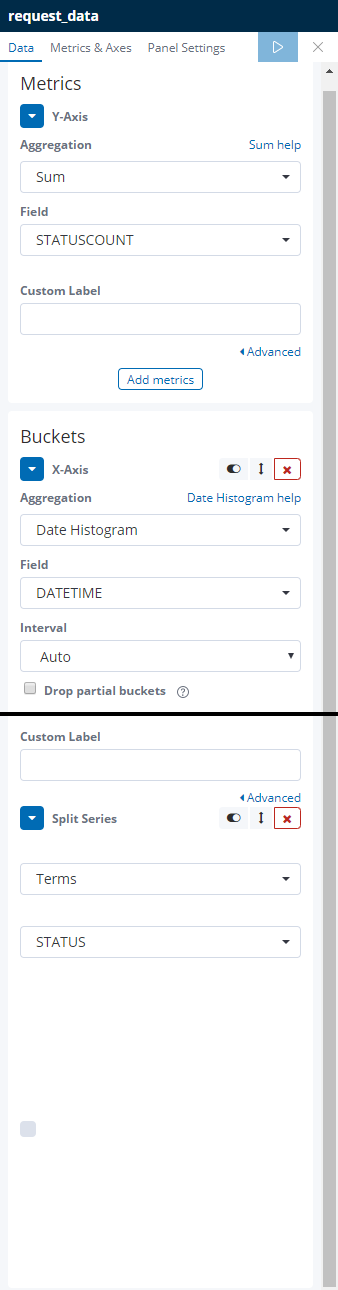
点击run的button即可看到效果图
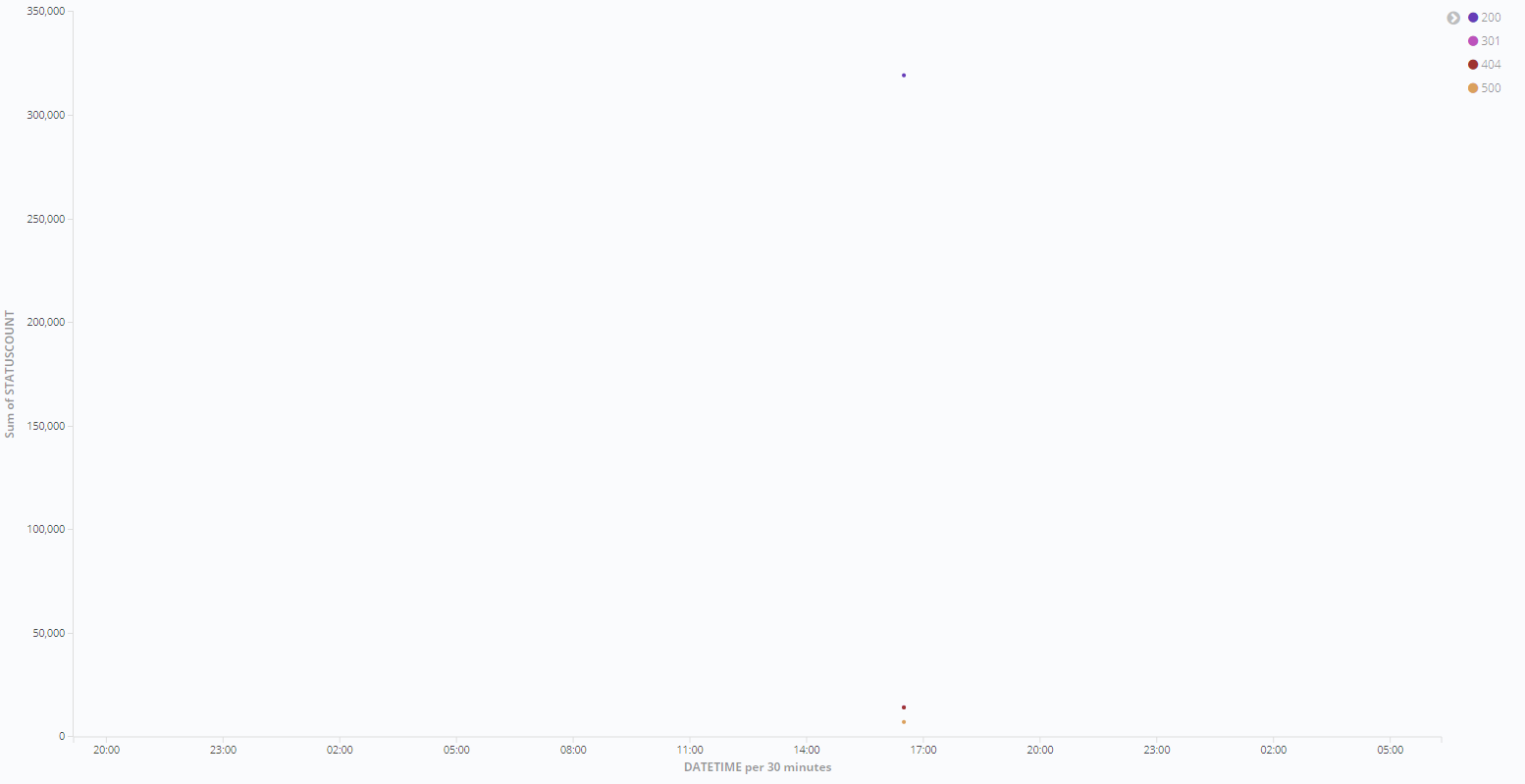
当然也可以进行其他可视化。
实现完….