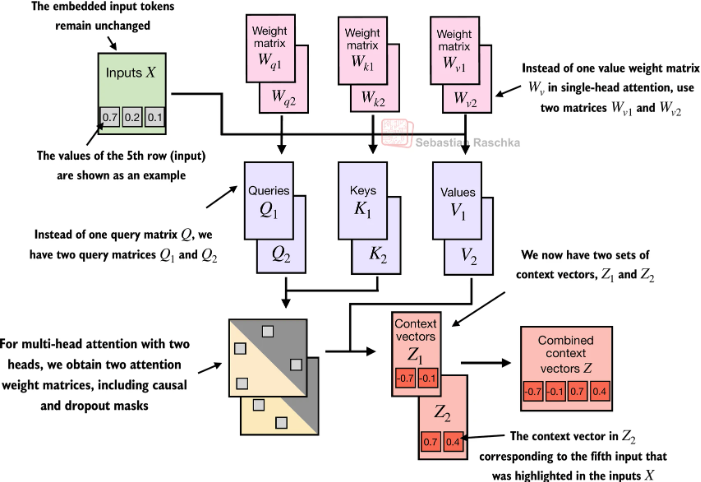
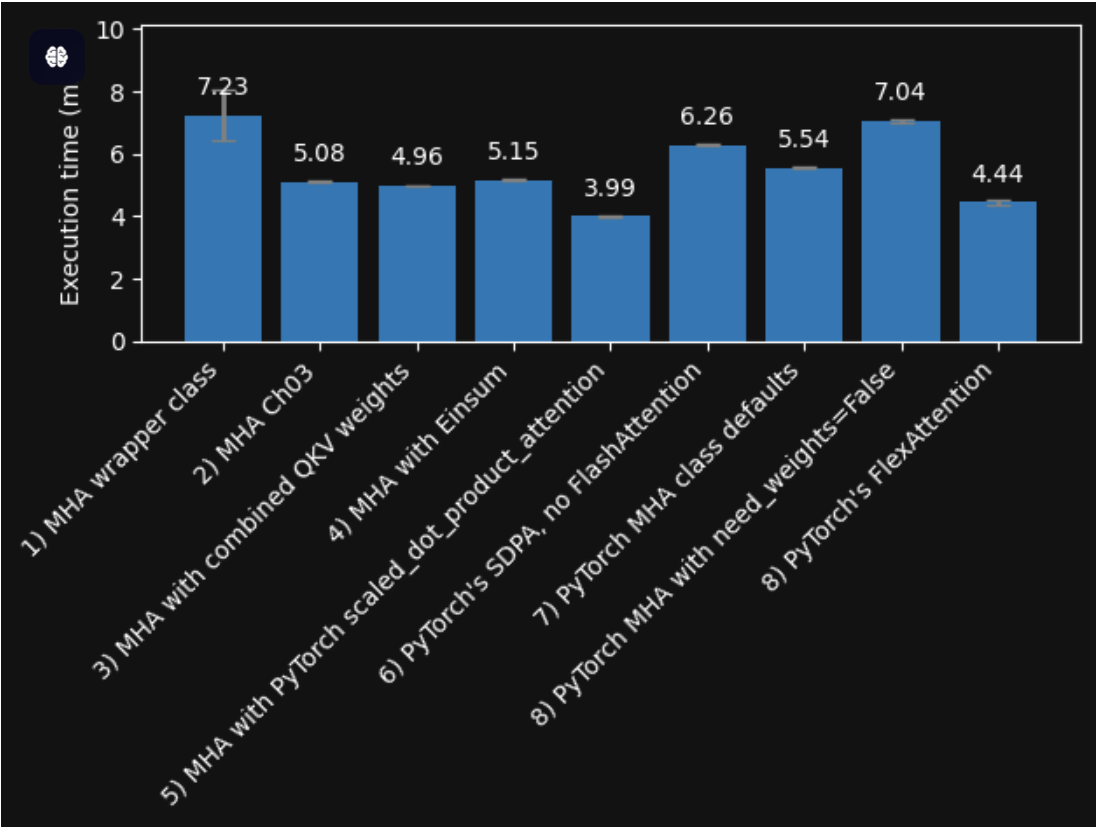
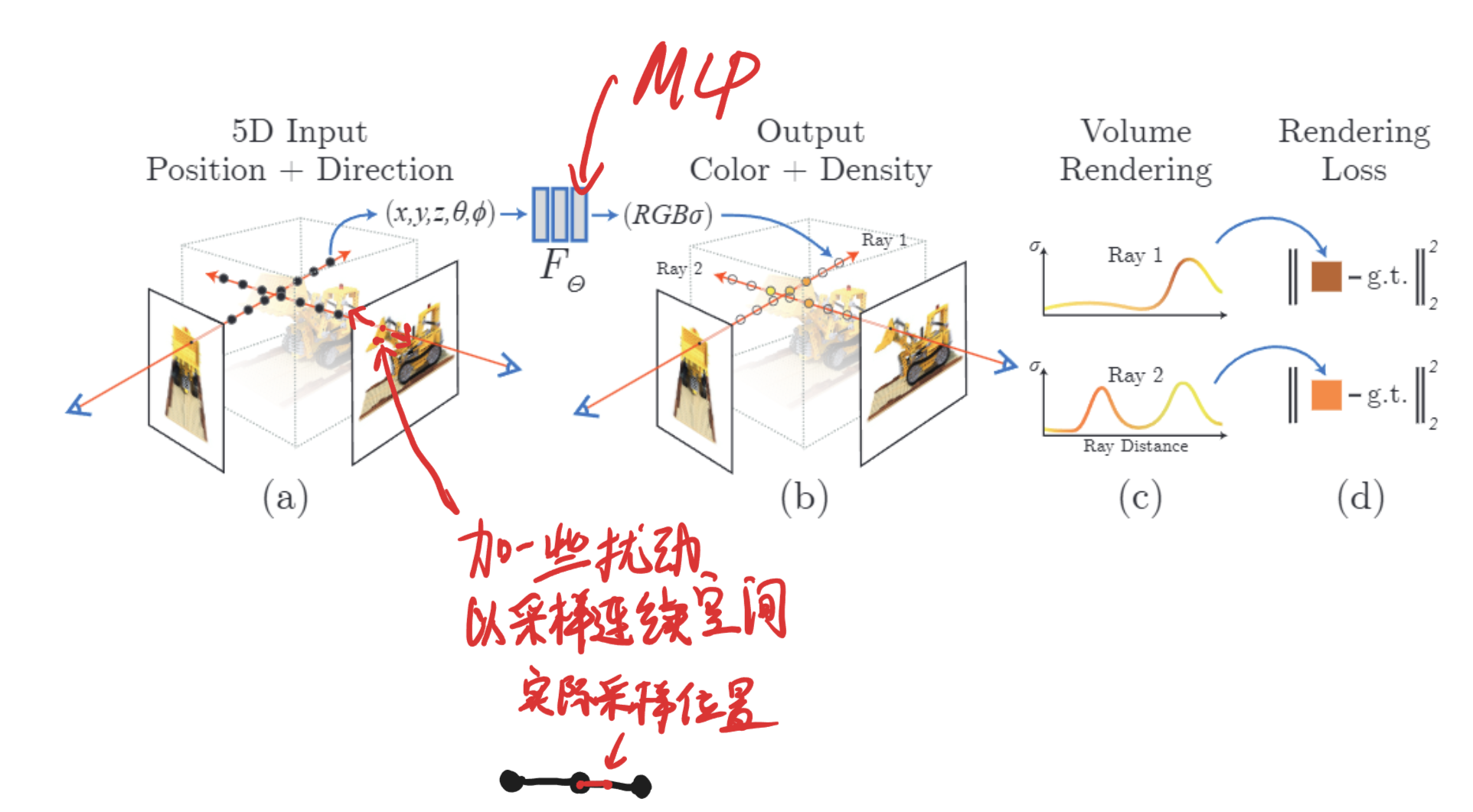
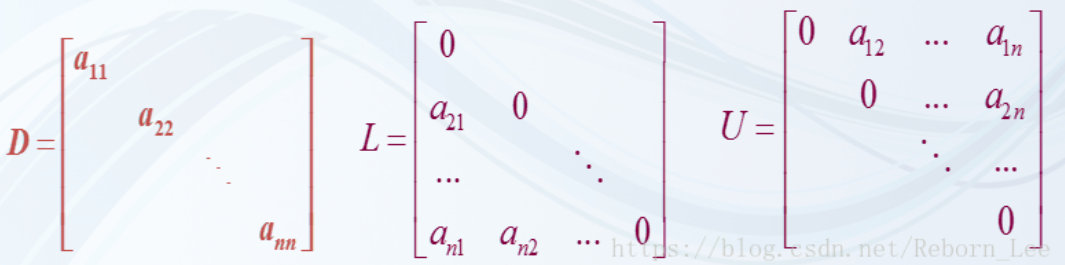
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
| class MHAEinsum(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert d_out % num_heads == 0, "d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads
self.W_query = nn.Parameter(torch.randn(d_out, d_in))
self.W_key = nn.Parameter(torch.randn(d_out, d_in))
self.W_value = nn.Parameter(torch.randn(d_out, d_in))
if qkv_bias:
self.bias_q = nn.Parameter(torch.zeros(d_out))
self.bias_k = nn.Parameter(torch.zeros(d_out))
self.bias_v = nn.Parameter(torch.zeros(d_out))
else:
self.register_parameter("bias_q", None)
self.register_parameter("bias_k", None)
self.register_parameter("bias_v", None)
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
self.register_buffer("mask", torch.triu(torch.ones(context_length, context_length), diagonal=1))
self.reset_parameters()
def reset_parameters(self):
nn.init.kaiming_uniform_(self.W_query, a=math.sqrt(5))
nn.init.kaiming_uniform_(self.W_key, a=math.sqrt(5))
nn.init.kaiming_uniform_(self.W_value, a=math.sqrt(5))
if self.bias_q is not None:
fan_in, _ = nn.init._calculate_fan_in_and_fan_out(self.W_query)
bound = 1 / math.sqrt(fan_in)
nn.init.uniform_(self.bias_q, -bound, bound)
nn.init.uniform_(self.bias_k, -bound, bound)
nn.init.uniform_(self.bias_v, -bound, bound)
def forward(self, x):
b, n, _ = x.shape
Q = torch.einsum("bnd,di->bni", x, self.W_query)
K = torch.einsum("bnd,di->bni", x, self.W_key)
V = torch.einsum("bnd,di->bni", x, self.W_value)
if self.bias_q is not None:
Q += self.bias_q
K += self.bias_k
V += self.bias_v
Q = Q.view(b, n, self.num_heads, self.head_dim).transpose(1, 2)
K = K.view(b, n, self.num_heads, self.head_dim).transpose(1, 2)
V = V.view(b, n, self.num_heads, self.head_dim).transpose(1, 2)
scores = torch.einsum("bhnd,bhmd->bhnm", Q, K) / (self.head_dim ** 0.5)
mask = self.mask[:n, :n].unsqueeze(0).unsqueeze(1).expand(b, self.num_heads, n, n)
scores = scores.masked_fill(mask.bool(), -torch.inf)
attn_weights = torch.softmax(scores, dim=-1)
attn_weights = self.dropout(attn_weights)
context_vec = torch.einsum("bhnm,bhmd->bhnd", attn_weights, V)
context_vec = context_vec.transpose(1, 2).reshape(b, n, self.d_out)
context_vec = self.out_proj(context_vec)
return context_vec
|