这篇文章是我在网易云上学习吴恩达机器学习做的一些总结,虽然之前有学习过,但是感觉还是没有很好地吸收总结。另外有的不知道怎么组织语言的就参考了黄广海博士的翻译和笔记。
Resource
course:
网易云课堂:吴恩达机器学习
PPT:https://github.com/fengdu78/Coursera-ML-AndrewNg-Notes
概述
机器学习解决的问题?
不只是AI,也为其他计算机任务赋能,比如:
数据库挖掘:点击流数据,医疗记录,计算生物学,工程领域
简单编程无法完成的任务:自动驾驶,手写识别,自然语言处理,计算机视觉
- 自定义的任务:产品(Amazon,Netflix,iTunes Genius)推荐系统
- 理解人类的学习和了解大脑
机器学习的定义?
TomMitchell (1998) Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E. (一个程序被认为能从经验 E 中学习,解决任务 T,达到性能度量值P,当且仅当,有了经验 E 后,经过 P 评判,程序在处理 T 时的性能有所提升。)
符号表示
大写字母$A$:一般表示矩阵
小写字母$a$:一般表示向量,向量一般为列向量,故$\theta^{T}x$为标量
$x_i$:第i个样本
$x_i^{(j)}$:第i个样本的第j个特征
$\mathbb R$$^n$:n维向量
神经网络中:
$x^i$: 第i个训练样本
$z^{l}$: 第l层的Z值
$X^$: mini-batch gradient descent的抽样
线性回归
算法框架
Hypothesis、Parameters、Cost Function、Goal
给定假设函数与参数,构造损失函数进行优化
假设函数与损失函数的直观表示
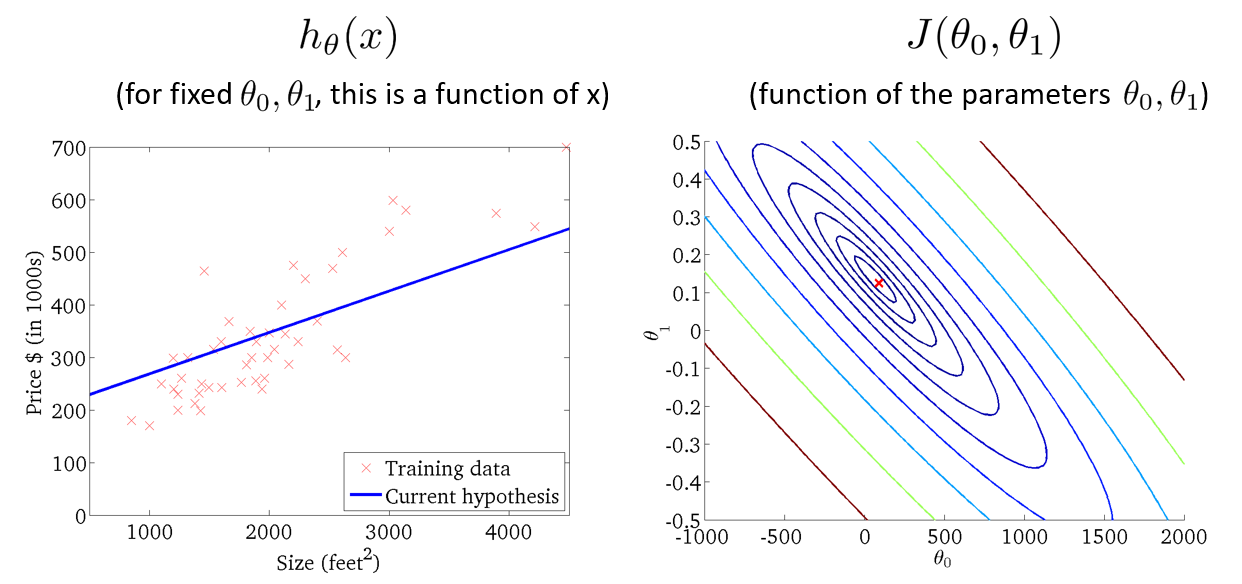
算法
(Batch)梯度下降法
算法描述

直观表现
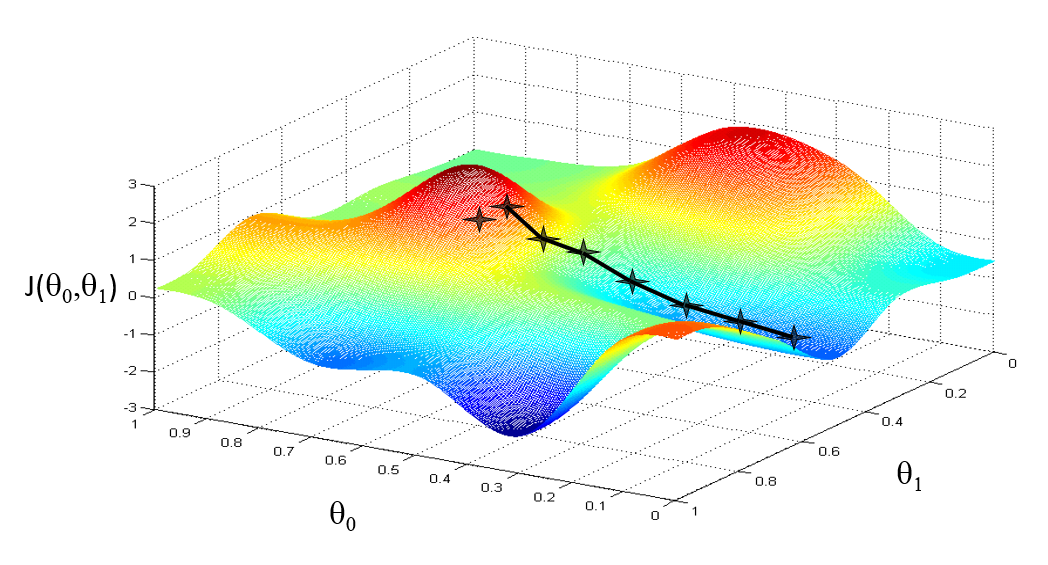
有点类似使用贪心算法下山
实现描述
- 关键:同步更新

几何意义
后一时刻的可以用$\theta$前一时刻的$\theta$进行递推

偏导数:斜率,作用是使参数朝着损失函数(局部/全局)最优解推进
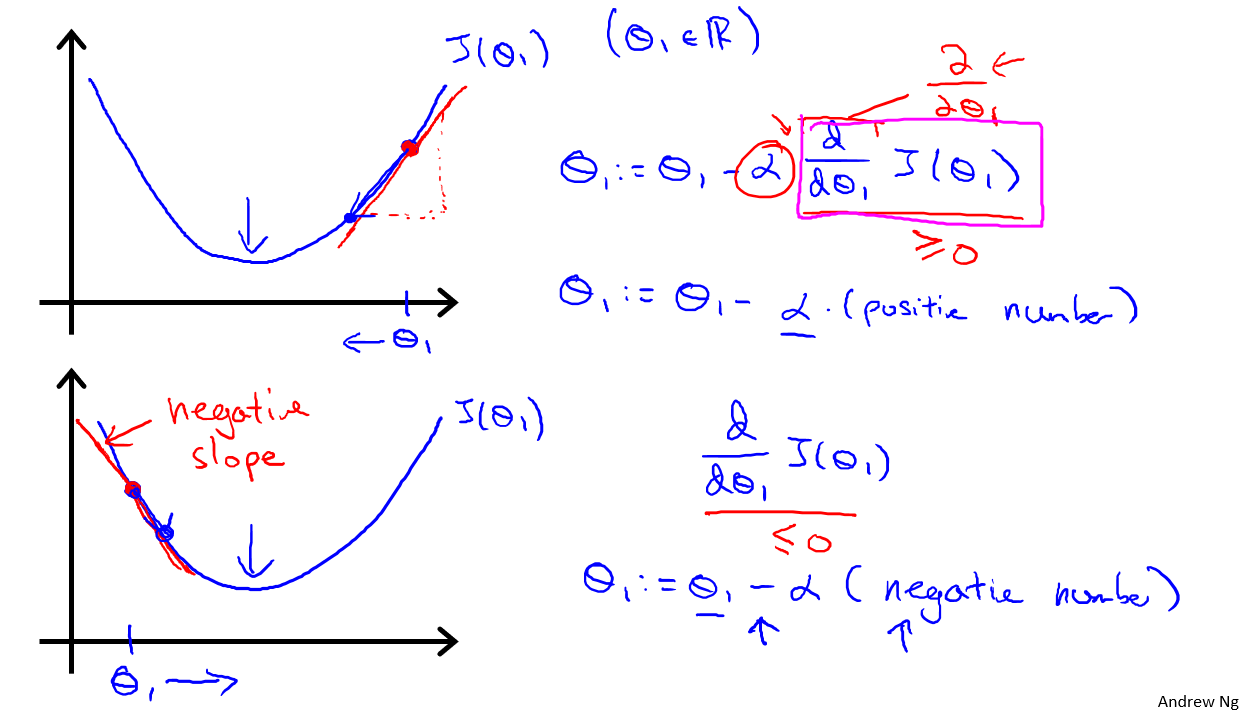
- 偏导数推导
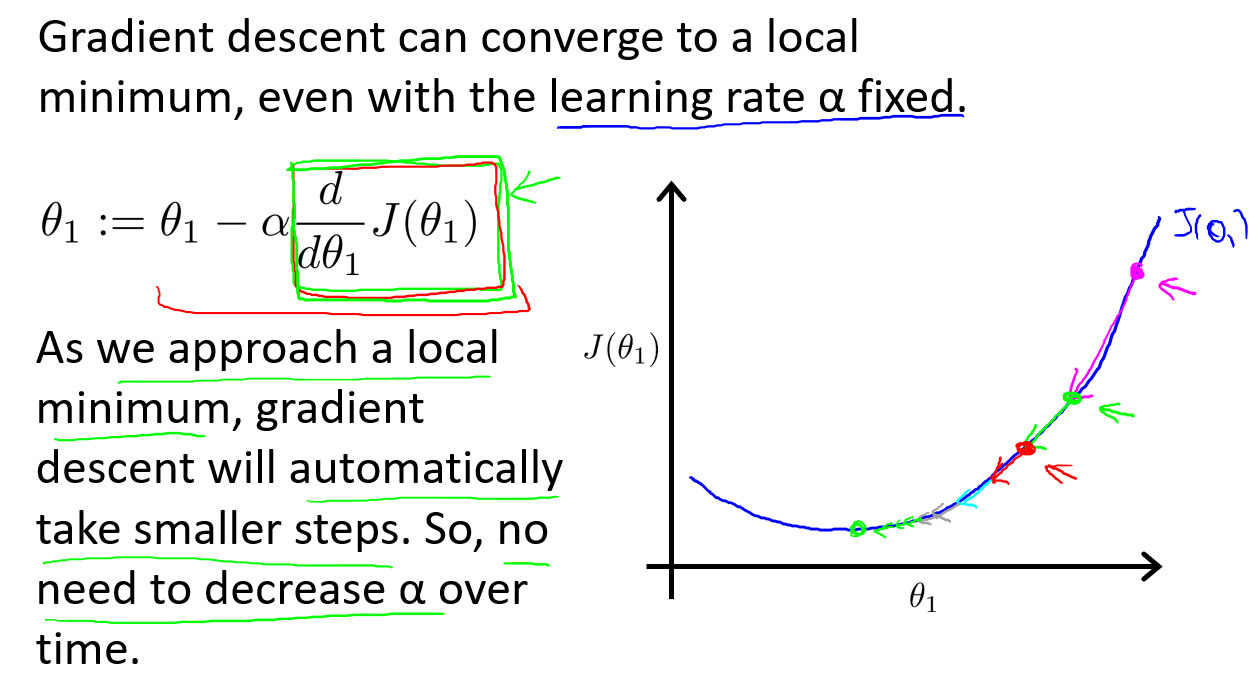
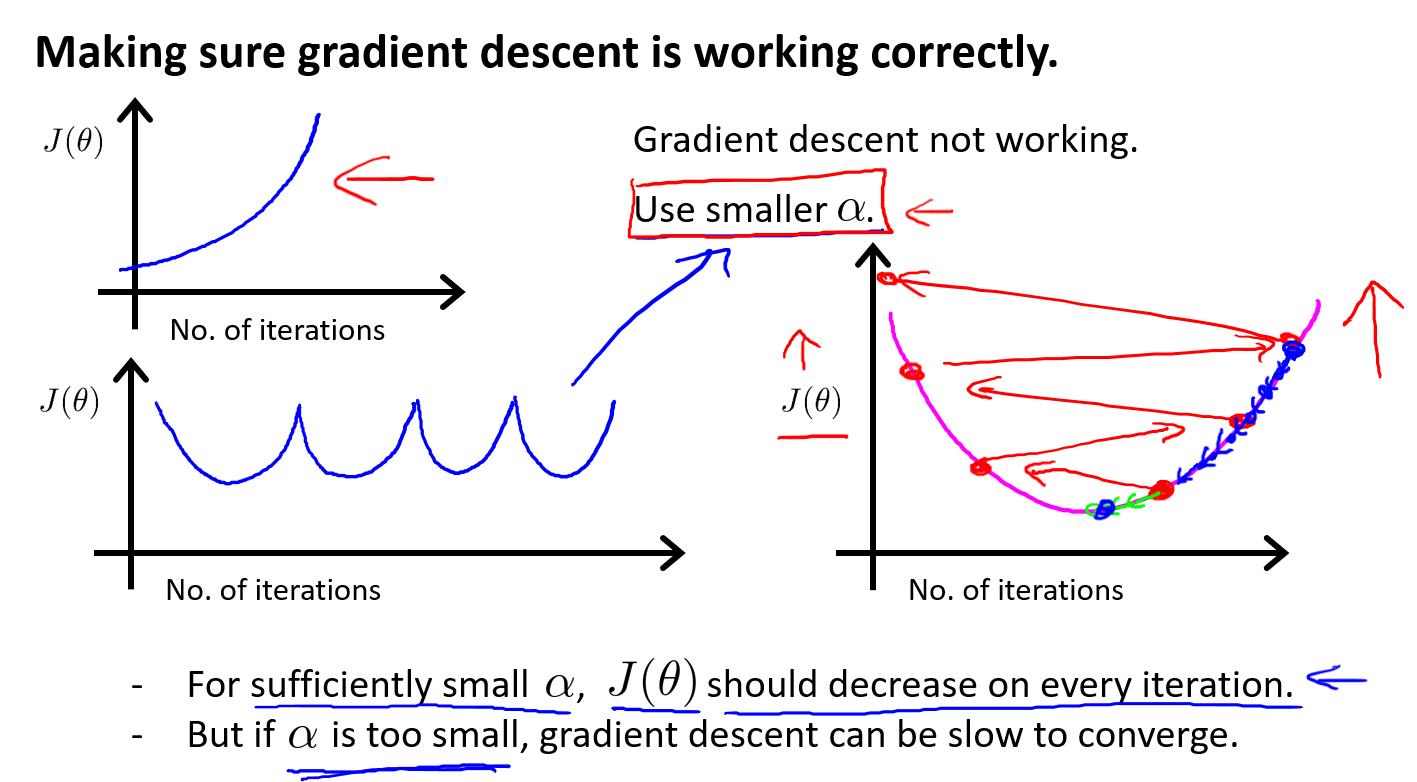
- 学习率:参数改变的幅度。太小,梯度下降速度慢;太大,收敛甚至发散
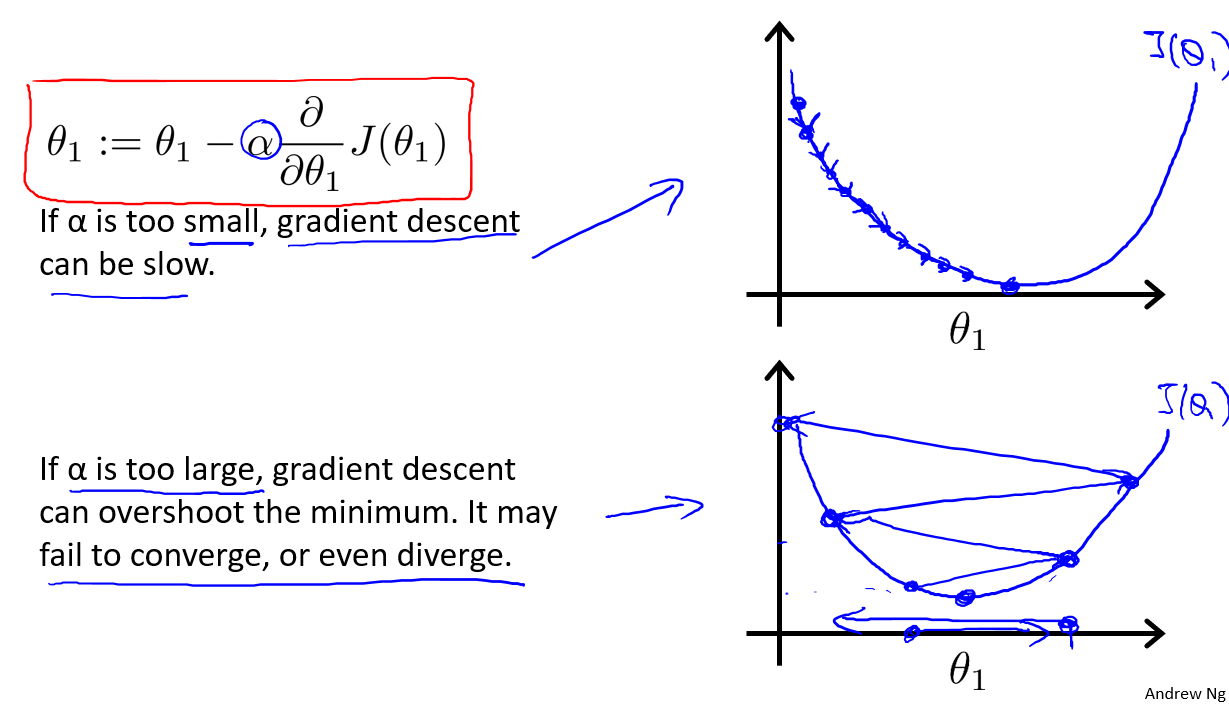
梯度下降法的问题
- 容易到达局部最优解
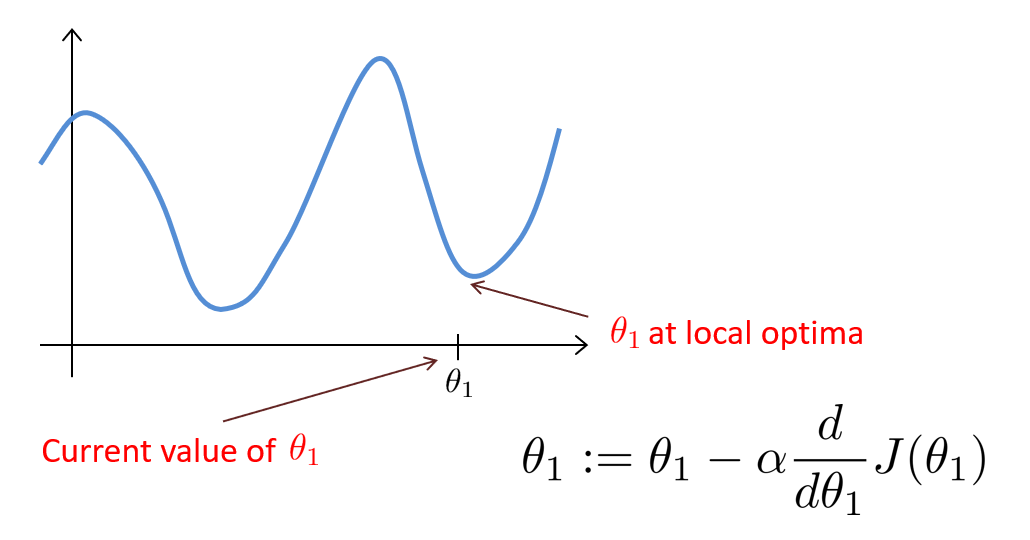
- 如果学习率不变,收敛速度将越来越慢
学习率太小:收敛太慢;学习率太大,可能不收敛甚至发散
“Batch”: 每次迭代需要遍历所有训练样本,若样本过大,速度会比较慢
梯度下降的技巧
加快梯度下降收敛
Feature Scaling
$x_i=\frac{x_i}{max-min}$
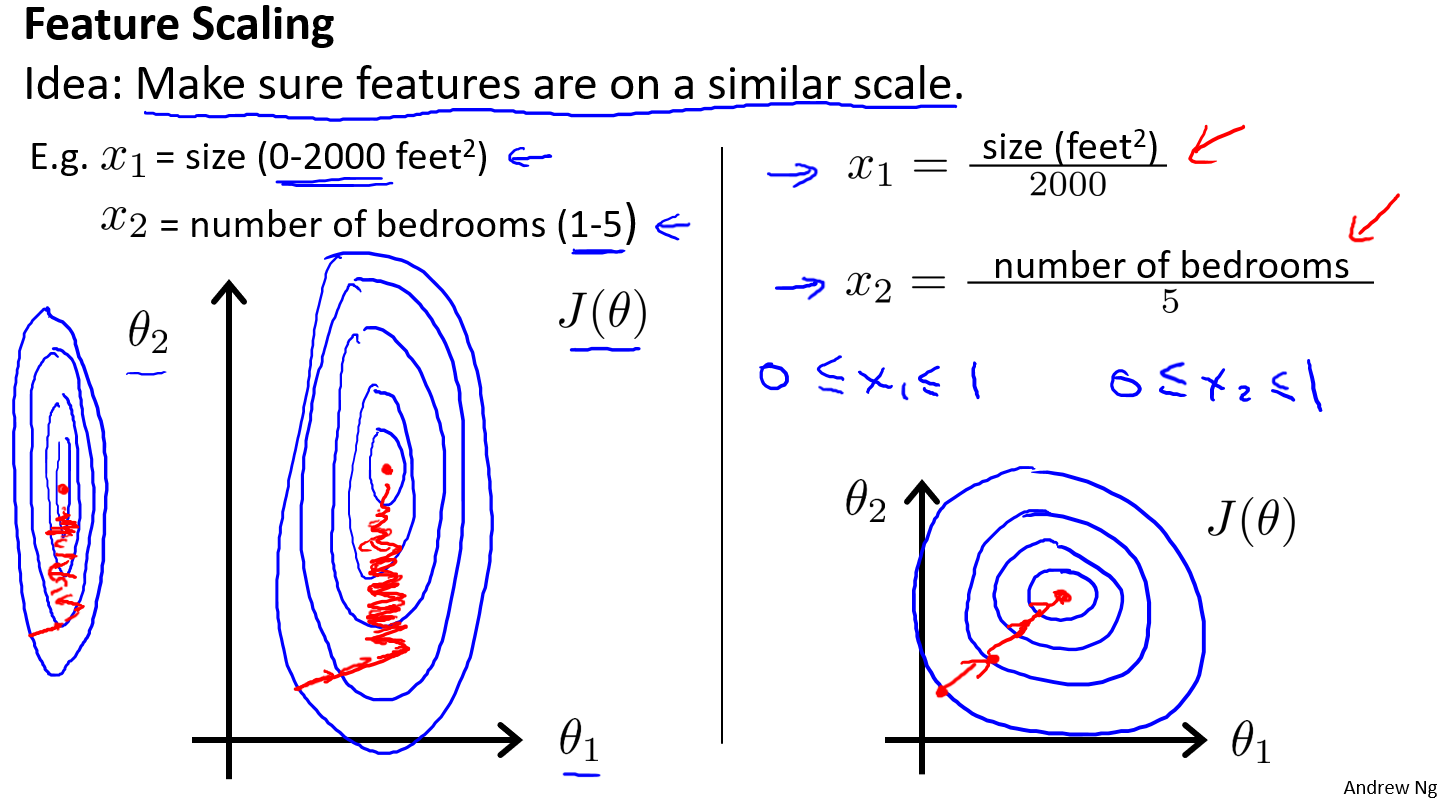
Mean normalization
$x_i=\frac{x_i-\bar{x}}{max-min}$

- 学习率的选择:每10倍或者每3倍进行改变,直到选择到一个不太大也不太小的学习率,能使函数收敛并且运行速度较快
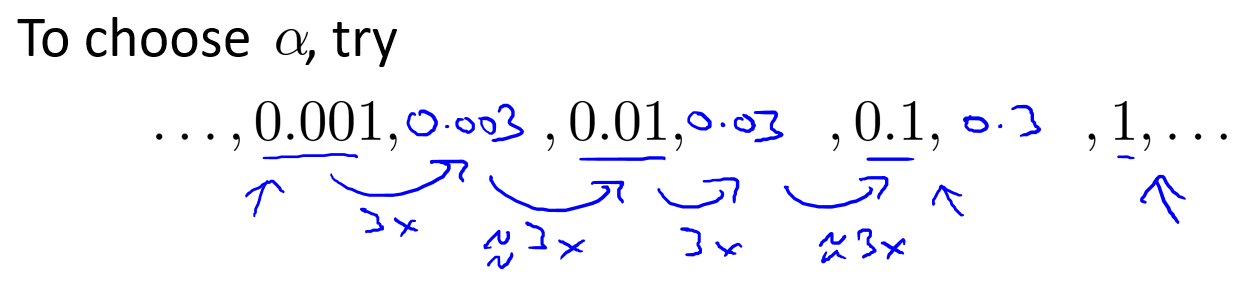
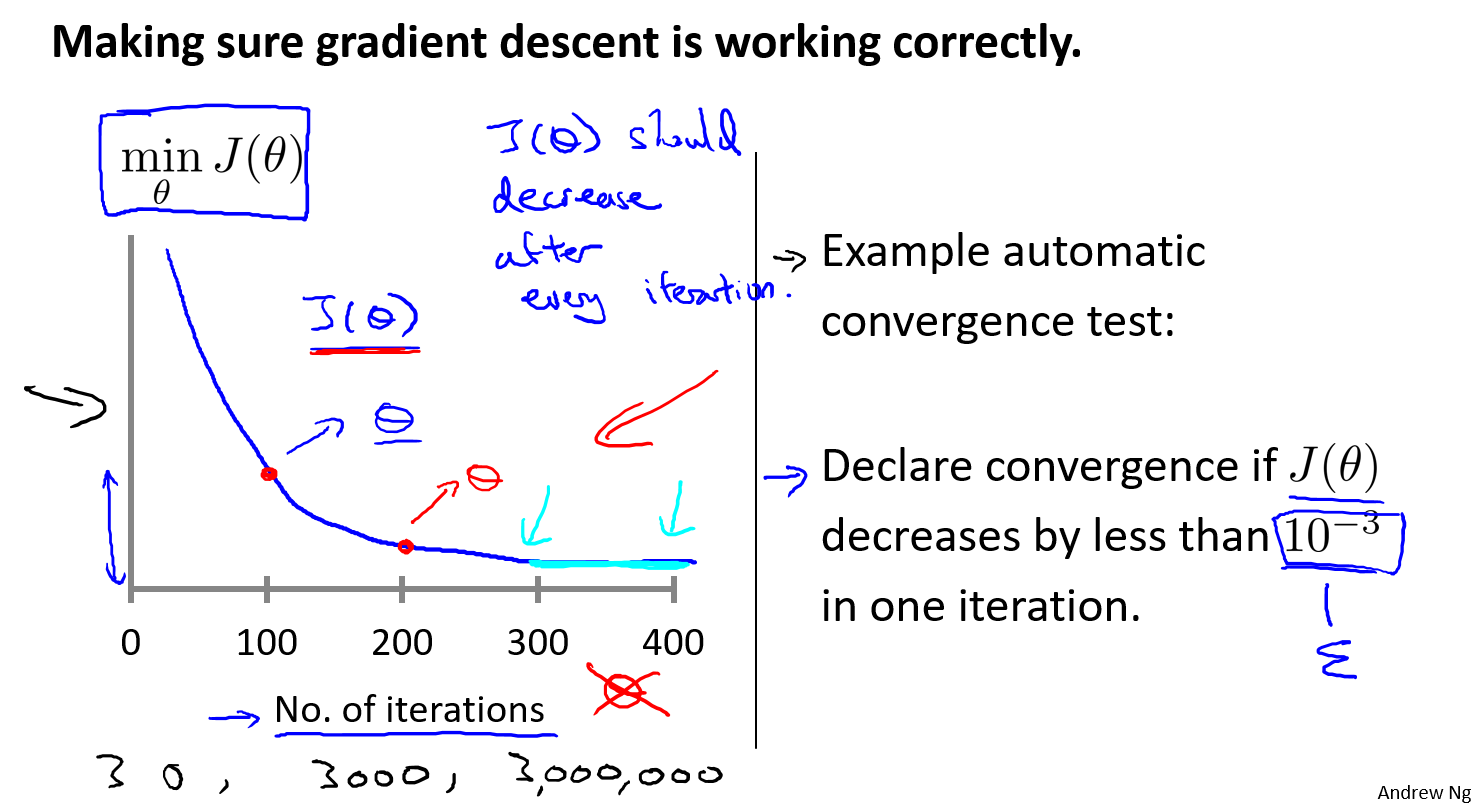
自动收敛检验,如果前后两次损失函数小于$\epsilon$则认为计算收敛
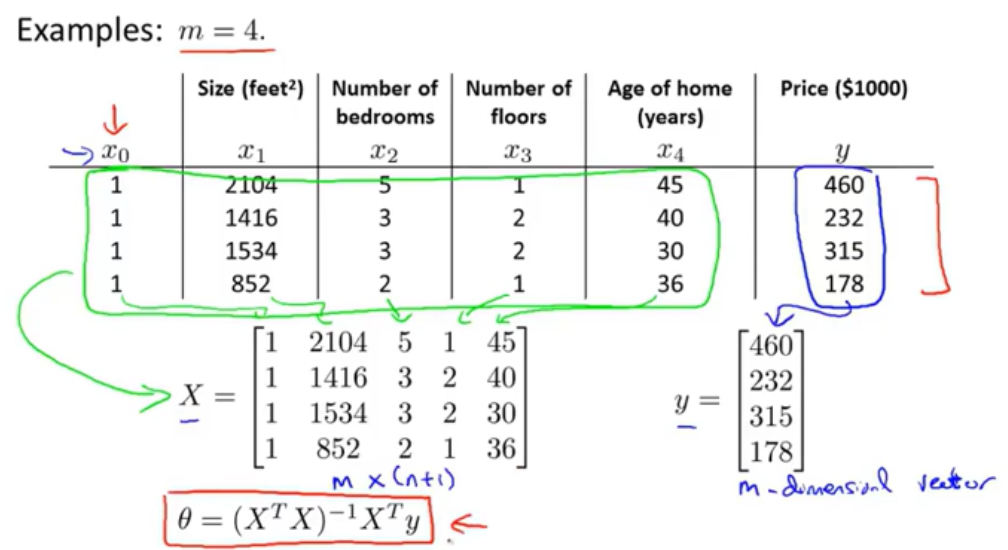
正规方程
构造
- 直观形式
符号形式
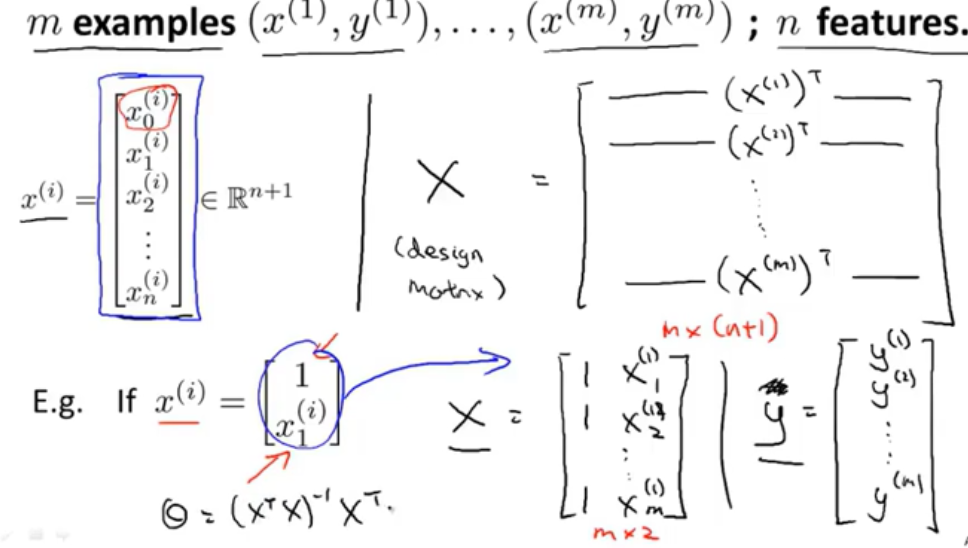
$X^TX$为非可逆矩阵的原因

梯度下降法和正规方程取舍
- 当特征数小于10000时更加倾向于使用正规方程求解参数$\theta$,当特征数大于10000时使用梯度下降直接迭代会更好

logistic回归
算法框架
问题引入
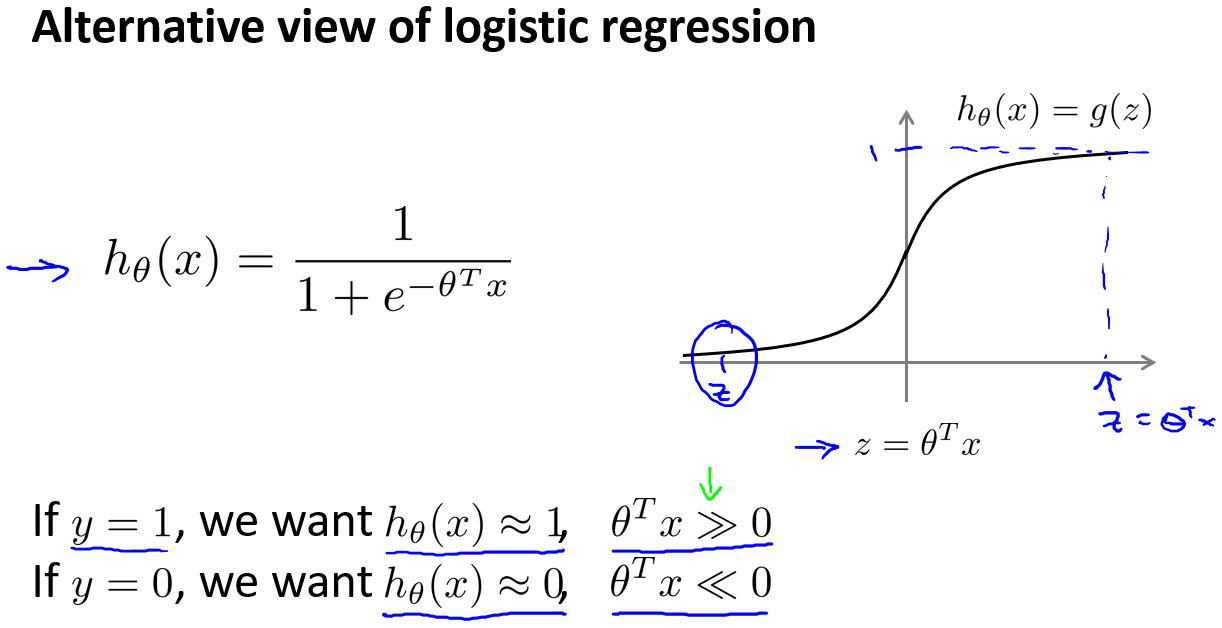
在分类问题中,我们希望输出$y$的取值为0或者1,如果使用线性回归,那么假设函数的输出值可能远大于1,或者远小于0。因此我们需要一个函数能够将输出值永远在0到1之间,即当假设函数大于等于0.5,预测$y=1$,当假设函数小于0.5,预测$y=0$。
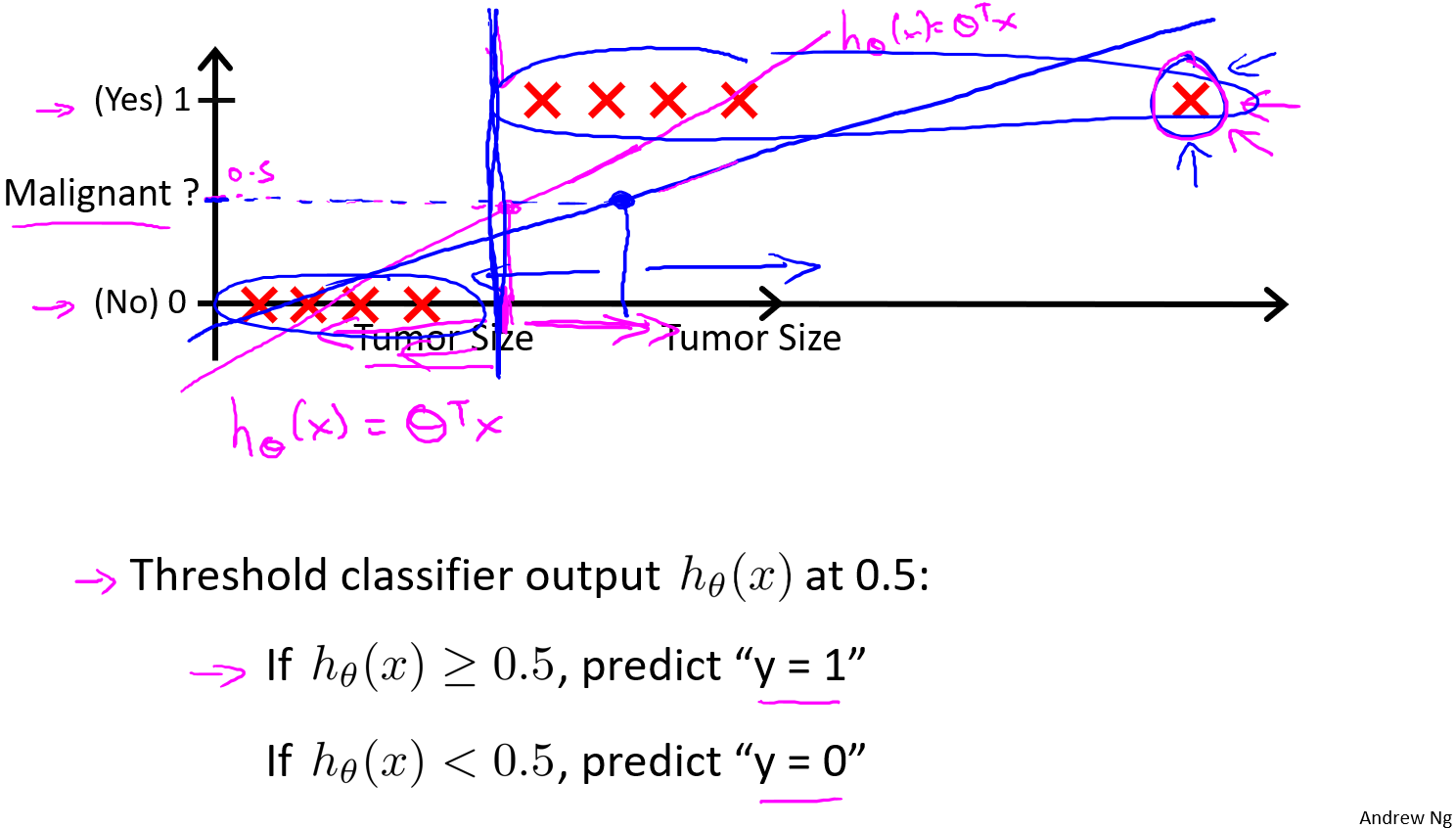
为此引入logistic回归
决策界限
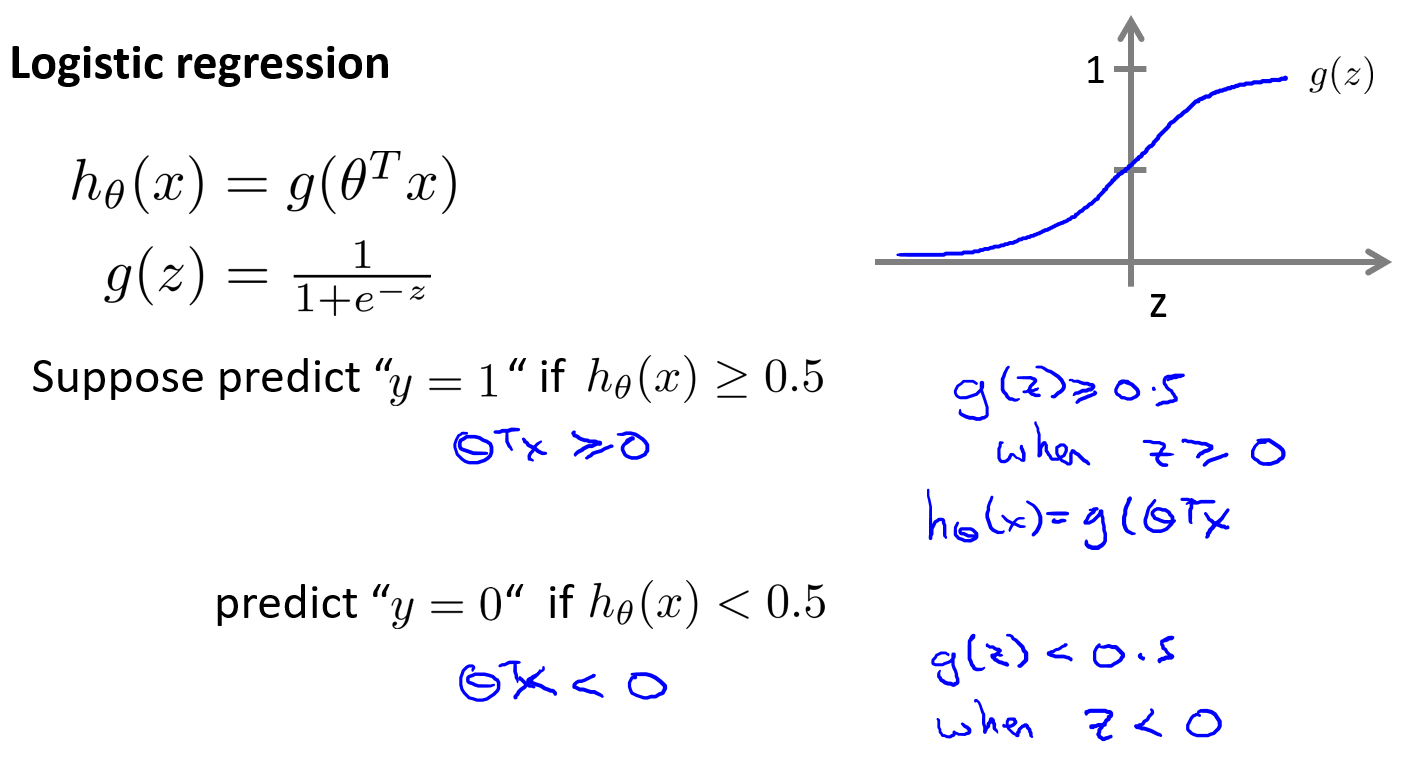
在逻辑斯蒂回归中,我们预测:
当$h_\theta(x)\ge0.5$时,预测 $y=1$。
当$h_\theta(x)\lt0.5$时,预测 $y=0$。
根据上面绘制出的 S 形函数图像,我们知道当
$z=0$时$g(z)=0.5$
$z\gt0$ 时$g(z)\gt0.5$
$z\lt0$ 时$g(z)\lt0.5$
又$z=\theta^Tx$,即:$\theta^Tx\ge0$时,预测$y=1$;$\theta^Tx\lt0$时,预测$y=0$
现在假设我们有一个模型:
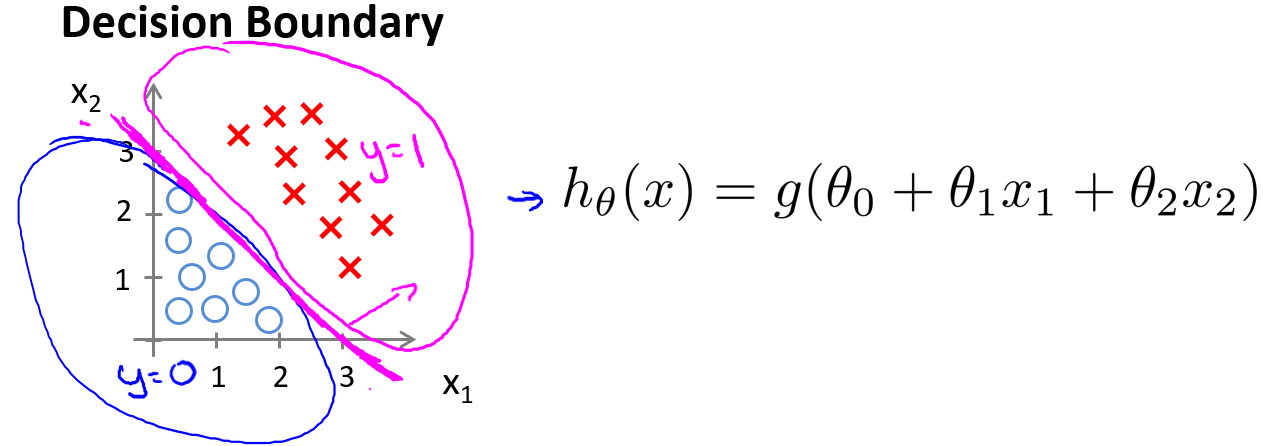
当参数$\theta$是向量$[-3\;1\;1]$,则当$\theta_0+\theta_1x_1+\theta_2 x_2\ge0$,模型将预测$y=1$。我们可以绘制直线$x_1+x_2=3$,将预测为1的区域和预测为0的区域分隔开。
现在假设我们有另一个模型:

当参数$\theta$是向量$[-1\;0\;0\;1\;1]$,则当$\theta_0+\theta_1x_1+\theta_2x_2+\theta_3x_1^2+\theta_4x_2^{2}\ge0$,模型将预测$y=1$。我们可以绘制圆形$x_1^2+x_2^2=1$,将预测为1的区域和预测为0的区域分隔开。
注意:决策界限不是训练集的属性,而是假设本身及其参数的属性,只要给定参数向量$\theta$,决策界限就确定了。
代价函数
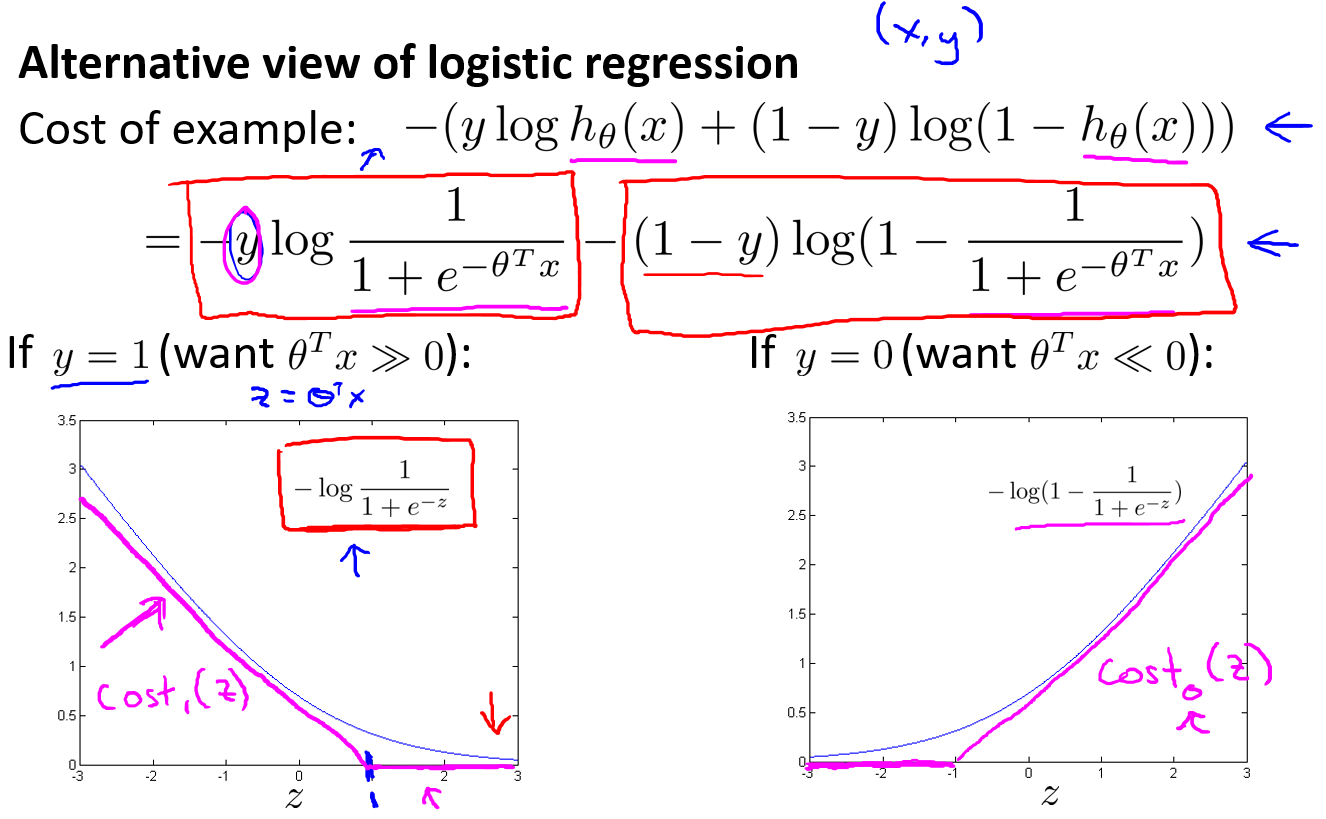
对于线性回归模型,我们定义的代价函数是所有模型误差的平方和。理论上来说,我们也可以对逻辑回归模型沿用这个定义,但是问题在于,当我们将带入到这样定义了的代价函数中时,我们得到的代价函数将是一个非凸函数(non-convexfunction)。
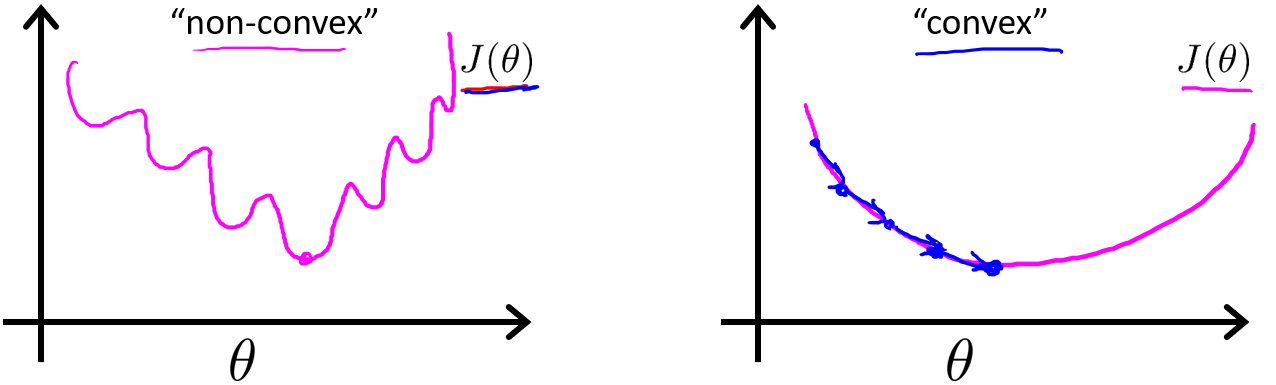
这意味着我们的代价函数有许多局部最小值,这将影响梯度下降算法寻找全局最小值。因此我们需要重新定义逻辑回归的代价函数为
这样做的意义就是希望当$y=1$的时候$h\theta(x)$越接近1代价函数越小,越接近0代价函数越大;反之当$y=0$的时候$h\theta(x)$越接近0代价函数越小,越接近1代价函数越大
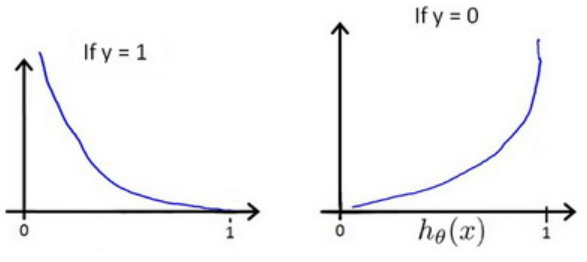
在得到这样一个代价函数以后,我们便可以用梯度下降算法来求得能使代价函数最小的参数了。算法为

- 偏导数推导
高级优化
Gradient descent
Conjugate gradient(共轭梯度-fminunc)
- 一般函数

加入了正则项

BFGS
L-BFGS
多分类:一对多
一对多的思想就是构造一个伪数据集,将多个类的中一个类标记为正向类$(y=1)$,将其他所有类都标记为负向类,这个模型记作。然后选择另一个类标记为正向类$(y=2)$,再将其他类都标记为正向类,这个模型记作,以此类推。最后得到一系列分类器记为:
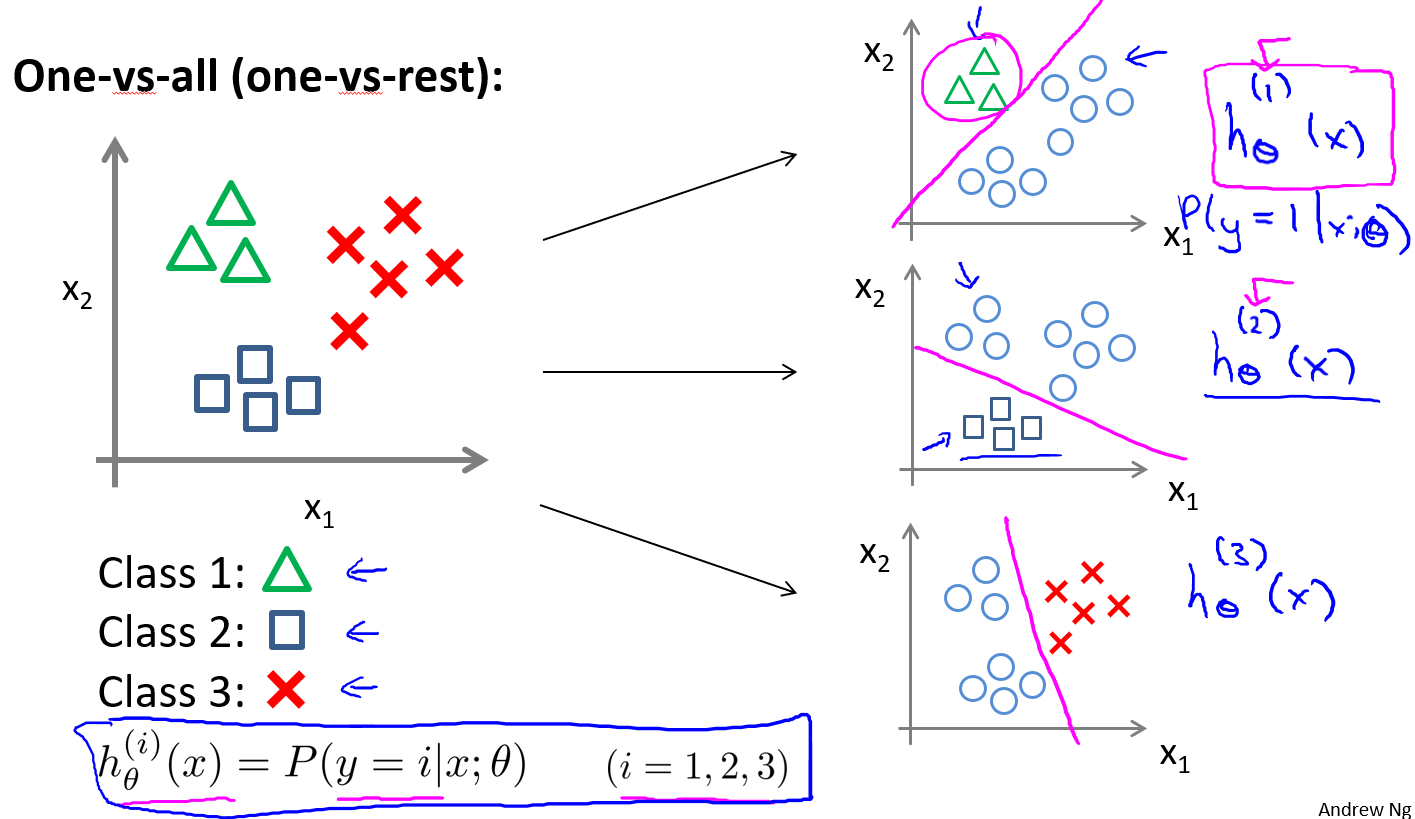
在做预测的时候,将所有分类器都运行一遍,然后对于每个输出变量,都选择可能性最高的作为输出,即$\maxih\theta^{(i)}(x)$。

正则化
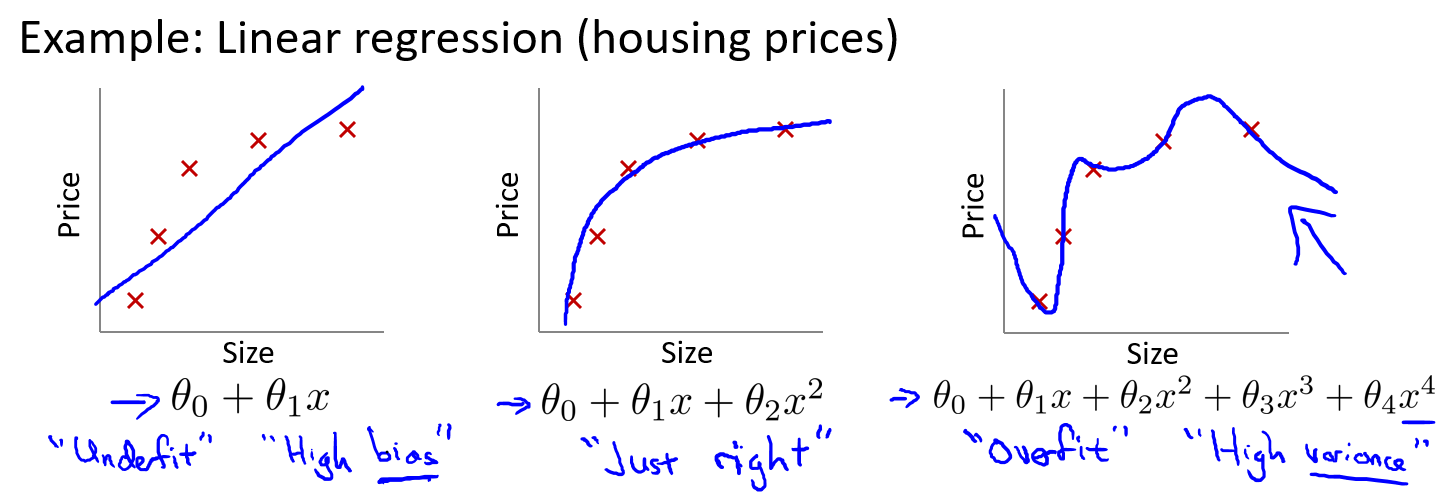
过拟合问题
由于特征维度过多,模型假设过于复杂,参数过多,训练数据过少,噪声过多,导致拟合的函数完美的预测训练集,但对新数据的测试集预测结果差。 过度的拟合了训练数据,而没有考虑到泛化能力。
- 回归例子:
- 分类例子:
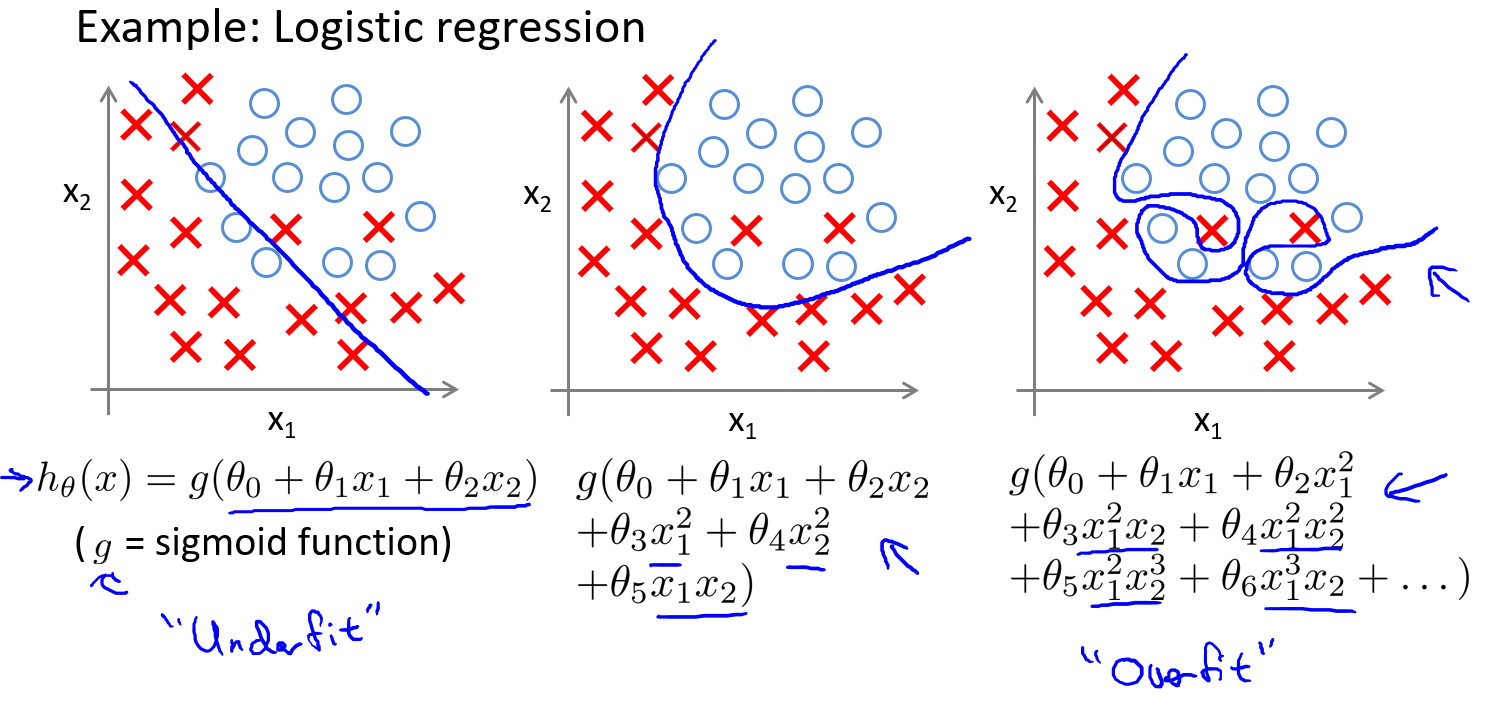
解决过拟合的方法:
- 丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如PCA)
- 正则化。 保留所有的特征,但是减少参数的大小(magnitude)。
动机
在下面的右图中高次项的出现导致了过拟合的产生,所以如果我们能让这些高次项的系数接近于0的话,我们就能很好的拟合了。 所以我们要做的就是在一定程度上减小这些参数$\theta$的值,这就是正则化的基本方法。因此我们要做的就是修改代价函数,在$\theta_3$和$\theta_4$设置一点惩罚。这样的话,我们在尝试最小化代价函数的时候也需要将这个惩罚纳入考虑中,并最终导致选择较小一些的$\theta_3$和$\theta_4$。
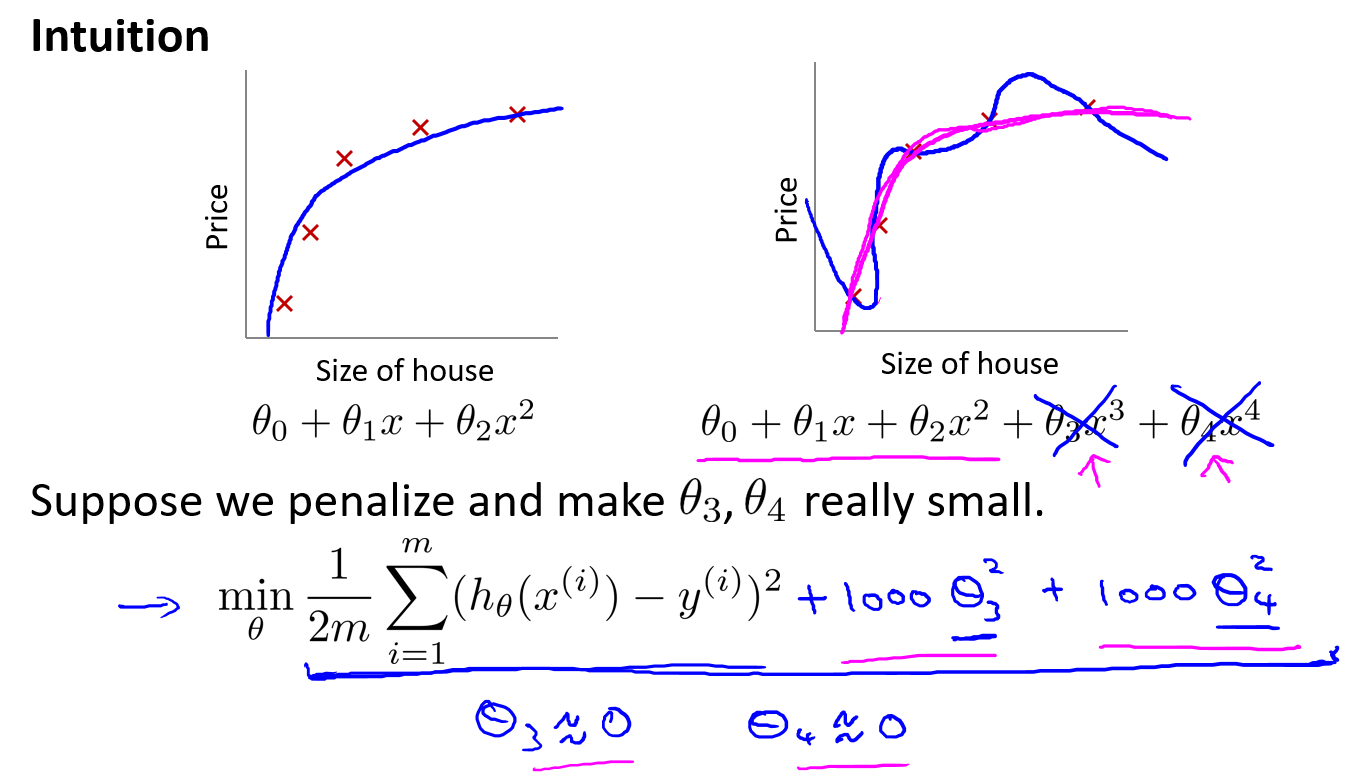
引入正则项
但是在实际的问题中,我们并不知道哪些系数是相关性较低的,或者是高次项的需要选择出来进行惩罚,所以需要为所有的参数都设置惩罚进行优化,于是加上正则项后的优化目标就是
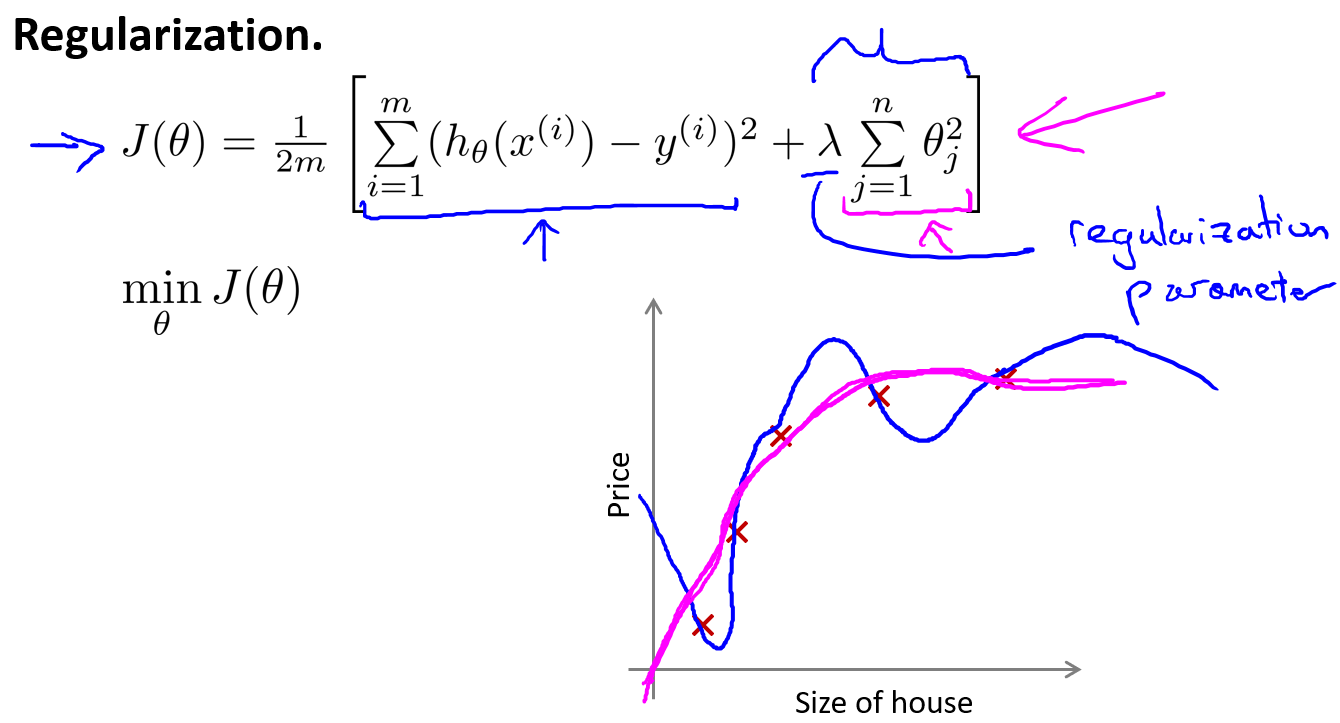
虽然这个函数并不是严格的二次函数,但是它相比原来的高次项函数更加地平滑。
对于$\lambda$的选择,如果$\lambda$选择过大,相当于对所有参数都进行了惩罚,那么最终优化的结果将会导致所有参数趋向于0,而假设函数就只剩下一个常数项,这将会导致欠拟合。以对于正则化,我们要取一个合理的 的值,这样才能更好的应用正则化。
线性回归
梯度更新
正规方程
加入正则项后的矩阵一定是可逆的

如果特征数量是$n$那么方阵是一个$(n+1)*(n+1)$维的,并且对角元上除了第一个元素是0,其他元素都是1。
logistic回归
梯度更新
神经网络
动机
- 无论是线性回归和逻辑回归,当特征太多时,计算的负荷会非常大。
- 使用非线性的多项式项,能够建立更好的分类模型。
- 如果希望用特征构建非线性多项式模型,即便是两两特征组合,也会特征膨胀。
前向传播网络
算法框架
前向传播网络的计算实质是函数优化
模型建立
神经网络模型建立在很多神经元之上,每一个神经元又是一个个学习模型。这些神经元(也叫激活单元,activation unit)采纳一些特征作为输出,并且根据本身的模型提供一个输出。下图是一个以逻辑回归模型作为自身学习模型的神经元示例,在神经网络中,参数又可被成为权重(weight)。
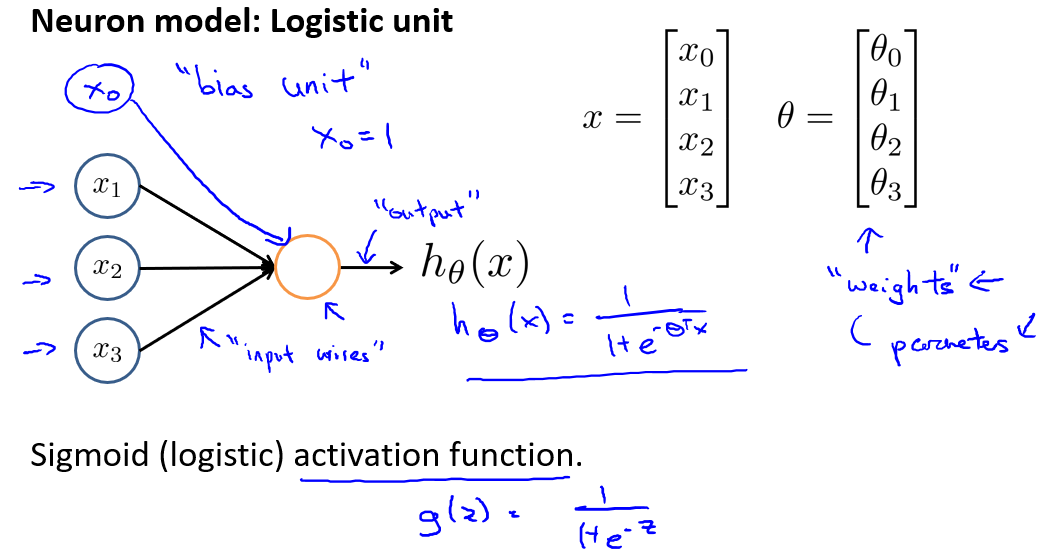
于是设计出了类似于神经元的神经网络,效果如下:
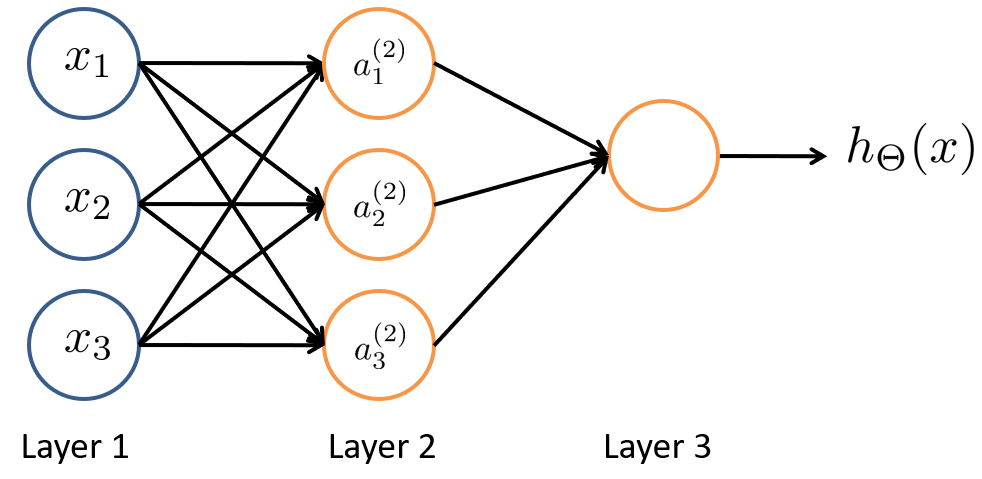
其中 是输入单元(input units),我们将原始数据输入给它们。是中间单元,它们负责将数据进行处理,然后呈递到下一层。 最后是输出单元,它负责计算。
神经网络模型是许多逻辑单元按照不同层级组织起来的网络,每一层的输出变量都是下一层的输入变量。下图为一个3层的神经网络,第一层成为输入层(Input Layer),最后一层称为输出层(Output Layer),中间一层成为隐藏层(Hidden Layers)。我们为每一层都增加一个偏差单位(bias unit),值永远为1:
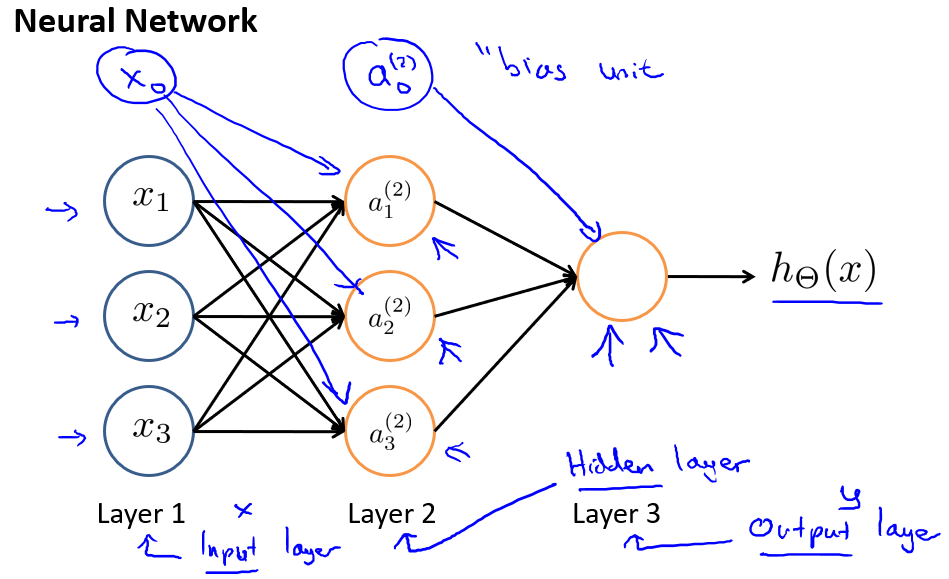
下面引入一些标记法来帮助描述模型:
- 代表第$j$层的第$i$个激活单元。
- 代表从第$j$层映射到第$j+1$层时的权重的矩阵,例如代表从第一层映射到第二层的权重的矩阵。其尺寸为:以第$j+1$层的激活单元数量为行数,以第$j$层的激活单元数加一为列数的矩阵。例如:上图所示的神经网络中的尺寸为 3*4。
对于上图所示的模型,激活单元和输出分别表达为:
上面进行的讨论中只是将特征矩阵中的一行(一个训练实例)喂给了神经网络,我们需要将整个训练集都喂给我们的神经网络算法来学习模型。我们可以知道:每一个$a$都是由上一层所有$x$的和每一个$x$所对应的决定的。我们把这样从左到右的算法称为前向传播算法( FORWARD PROPAGATION ),把$x$,$\Theta$,$a$ 分别用矩阵表示:
我们可以得到$g(\Theta*X)=a$。相对于使用循环来编码,利用向量化的方法会使得计算更为简便。

使用神经网络的计算来表示逻辑运算
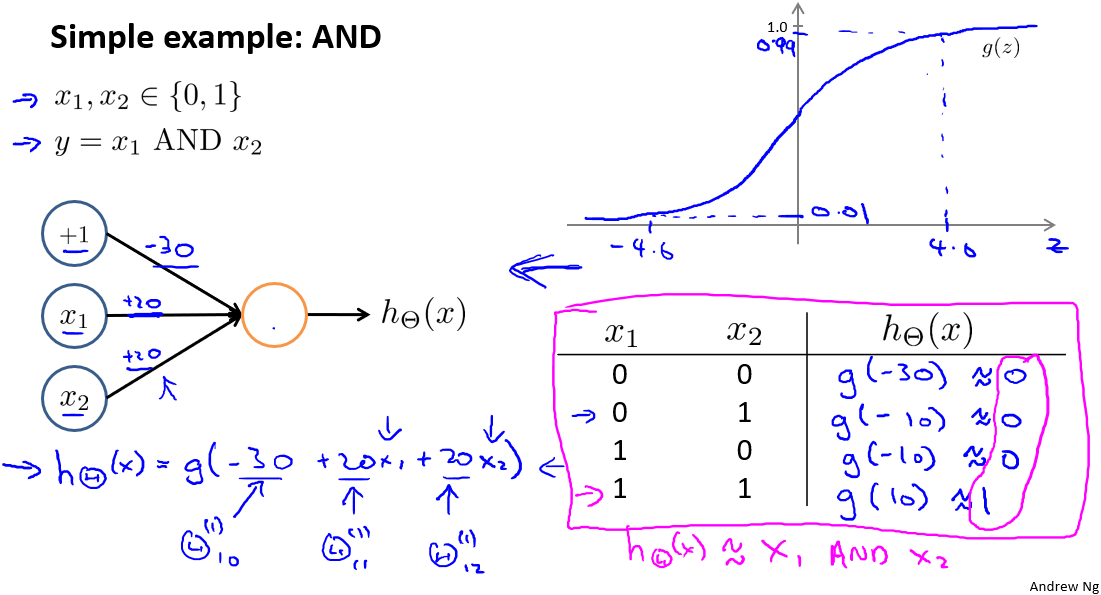
- 与运算AND
- 或运算OR

- 非运算NOT
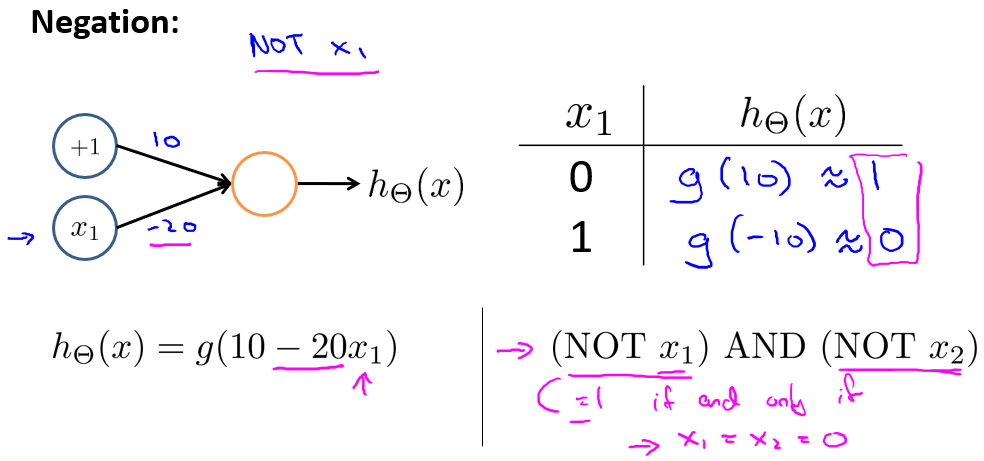
- 异或运算
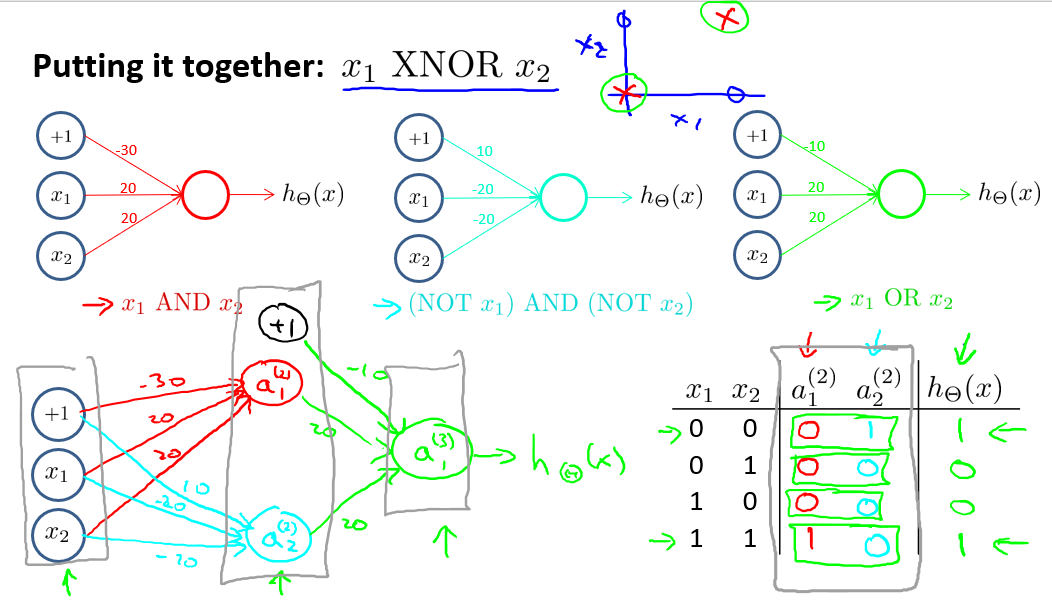
多分类问题
网络结构如下:
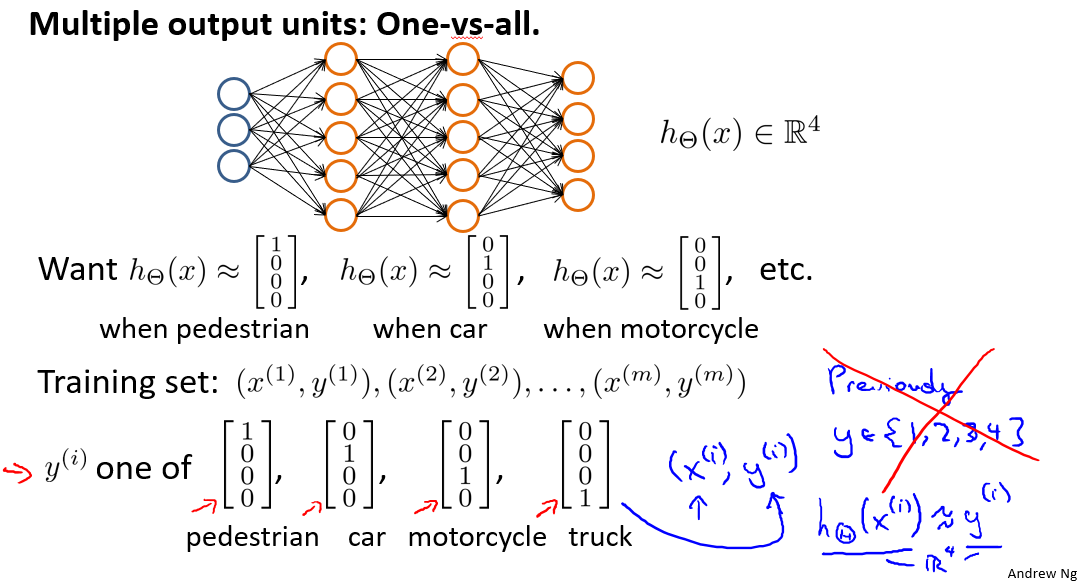
神经网络算法的输出结果为四种可能情形之一。
代价函数
首先引入一些便于稍后讨论的新标记方法:
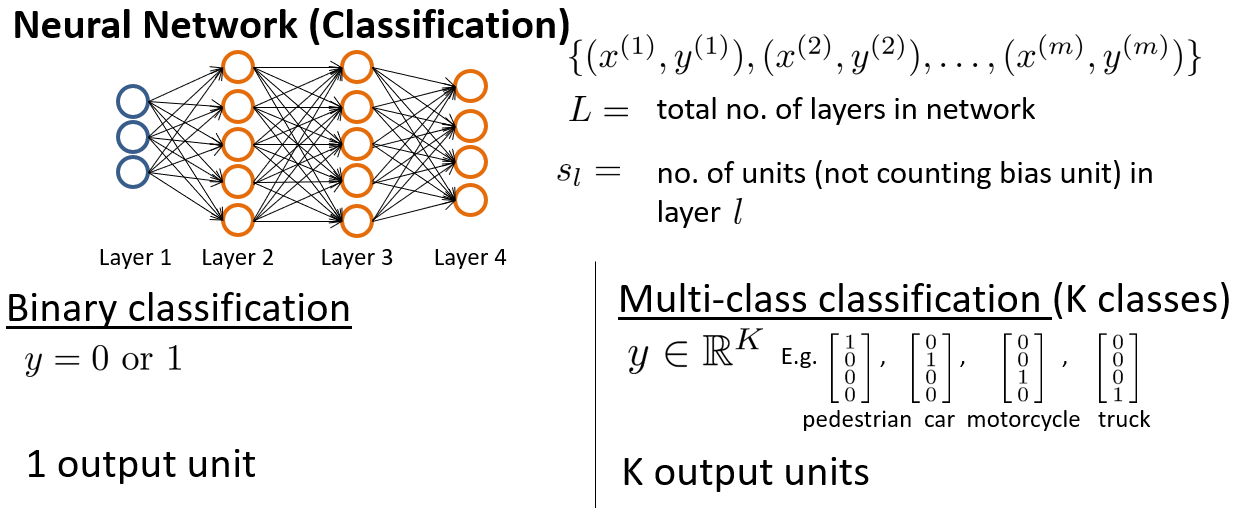
假设神经网络的训练样本有$m$个,每个包含一组输入$x$和一组输出信号$y$,$L$表示神经网络层数,表示每层的neuron个数(表示输出层神经元个数),代表最后一层中处理单元的个数。
将神经网络的分类定义为两种情况:二类分类和多类分类,
二类分类:$S_L=1,y=0\;or\;1$表示哪一类;
$K$类分类:$S_L=k,y_i=1$表示分到第$i$类$(k>2)$;
我们回顾逻辑回归问题中我们的代价函数为:
在逻辑回归中,我们只有一个输出变量,又称标量(scalar),也只有一个因变量$y$,但是在神经网络中,我们可以有很多输出变量,我们的是一个维度为$K$的向量,并且我们训练集中的因变量也是同样维度的一个向量,因此我们的代价函数会比逻辑回归更加复杂一些,为:
这个看起来复杂很多的代价函数背后的思想还是一样的,我们希望通过代价函数来观察算法预测的结果与真实情况的误差有多大,唯一不同的是,对于每一行特征,我们都会给出$K$个预测,基本上我们可以利用循环,对每一行特征都预测$K$个不同结果,然后在利用循环在$K$个预测中选择可能性最高的一个,将其与$y$中的实际数据进行比较。
正则化的那一项只是排除了每一层后,每一层的$\Theta$矩阵的和。最里层的循环$j$循环所有的行(由层的激活单元数决定),循环则循环所有的列,由该层(层)的激活单元数所决定。
总的来说,损失函数包括两项:
- 与真实值之间的距离为每个样本-每个类输出的加和。
- 对参数进行regularization的非bias项所有参数的平方和。
反向传播网络
算法步骤
模型建立
回顾前向传播算法:
- $z^{(l)}$是第$l$层没通过激活函数的值
- $a^{(l)}$是第$l$层通过激活函数后的值
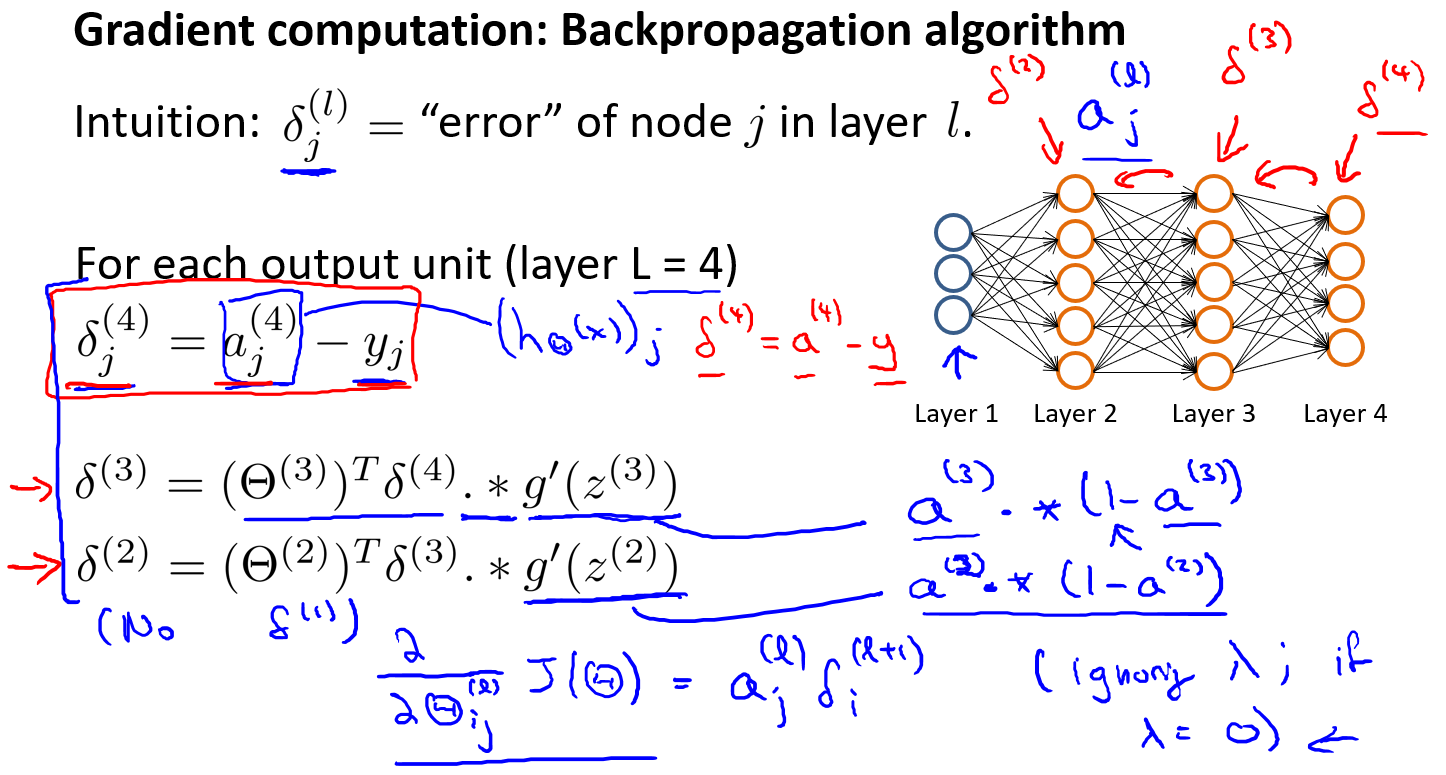
后向传播算法:
- $l$代表目前所计算的是第几层。
- $j$代表目前计算层中的激活单元的下标,也将是下一层的第个输入变量的下标。
- $i$ 代表下一层中误差单元的下标,是受到权重矩阵中第行影响的下一层中的误差单元的下标。
- 是第$l$层结点$j$ 的误差
我们从最后一层的误差开始计算,误差是激活单元的预测()与实际值($y^k$)之间的误差,($k=1:k$)。 我们用来表示误差,则: ,我们利用这个误差值来计算前一层的误差: 其中是$S$形函数的导数,(这里需要推导证明)。而则是权重导致的误差的和。下一步是继续计算第二层的误差:因为第一层是输入变量,不存在误差。我们有了所有的误差的表达式后,便可以计算代价函数的偏导数了,假设$\lambda=0$,即我们不做任何正则化处理时有。
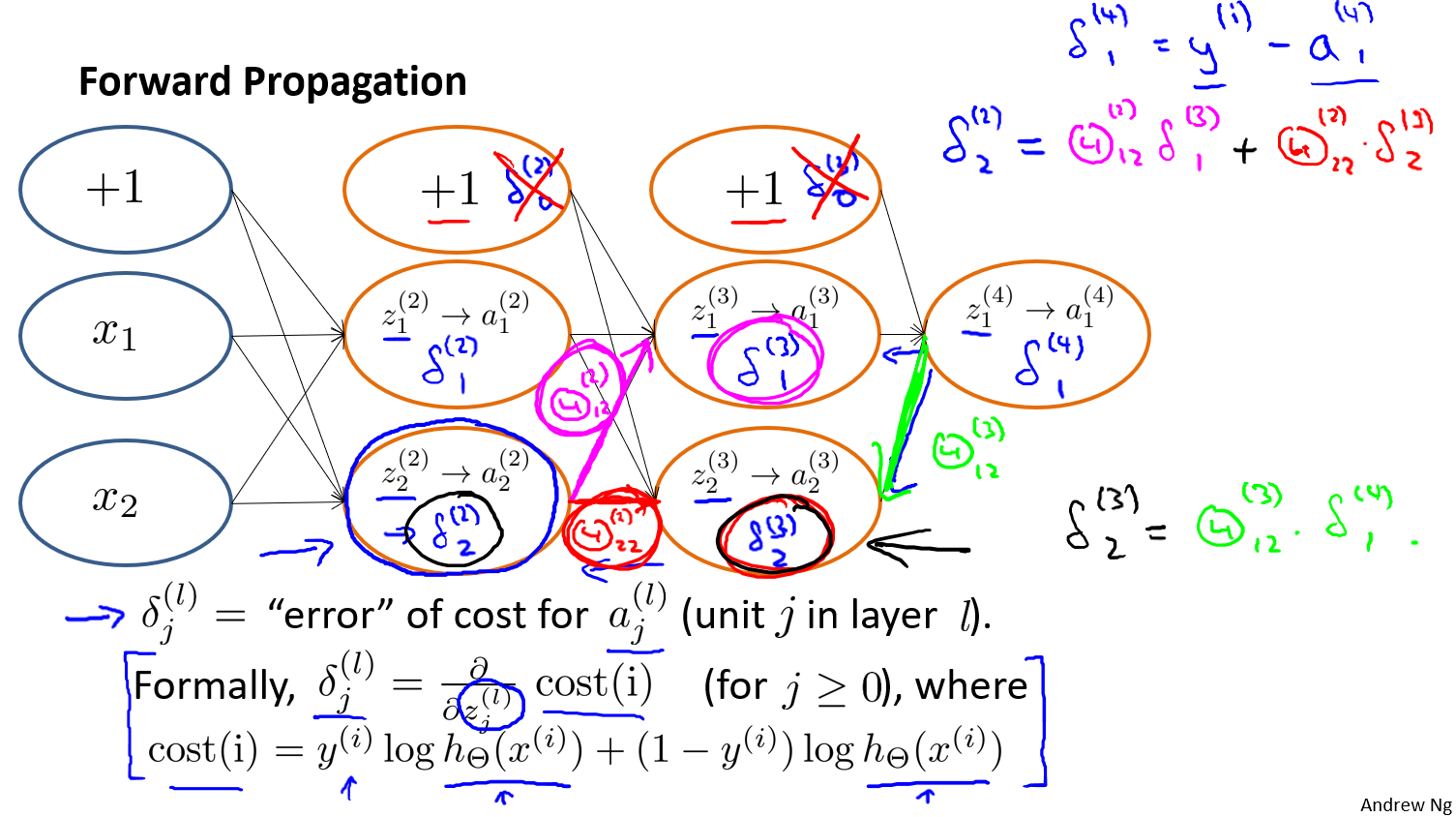
梯度检测
启发
导数可以由双侧差分来近似
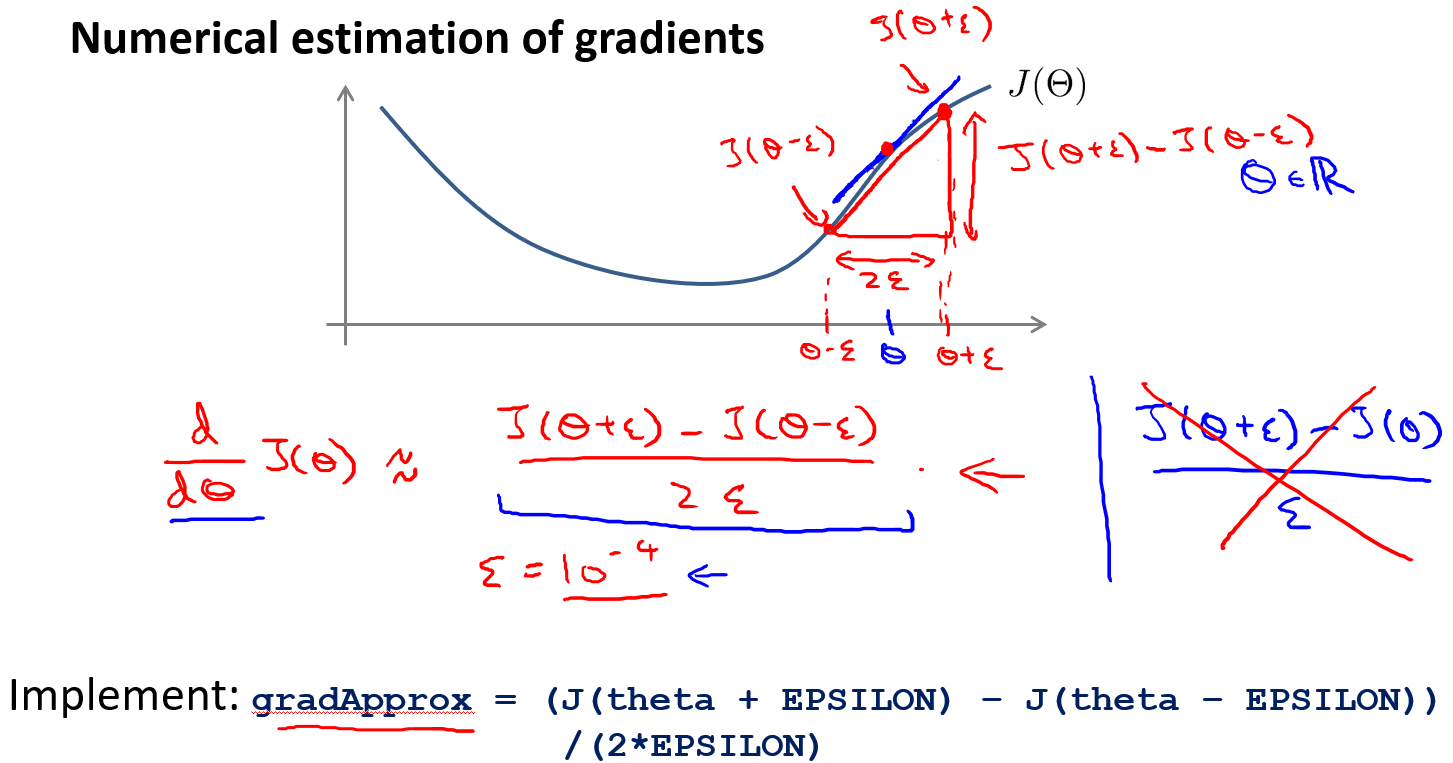
推广
推广到偏导数也可以计算得到一个双侧差分矩阵

比较
最终将上述得到的近似梯度矩阵与反向传播得到的偏导数矩阵进行比较

具体步骤

随机初始化
对称权重问题
到目前为止我们都是初始所有参数为0,这样的初始方法对于逻辑回归来说是可行的,但是对于神经网络来说是不可行的。如果我们令所有的初始参数都为0,这将意味着我们第二层的所有激活单元都会有相同的值。
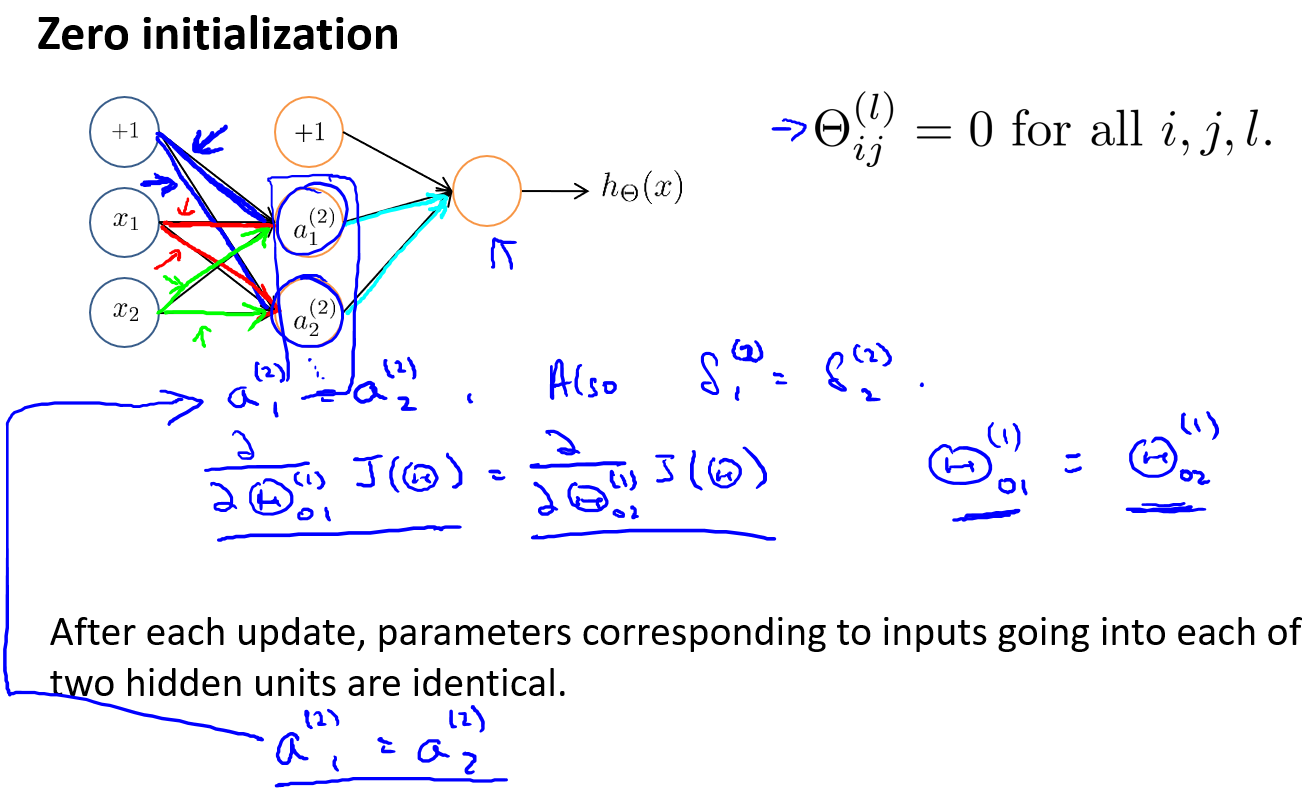
更好的初始化
将初始值设置为

神经网络的训练
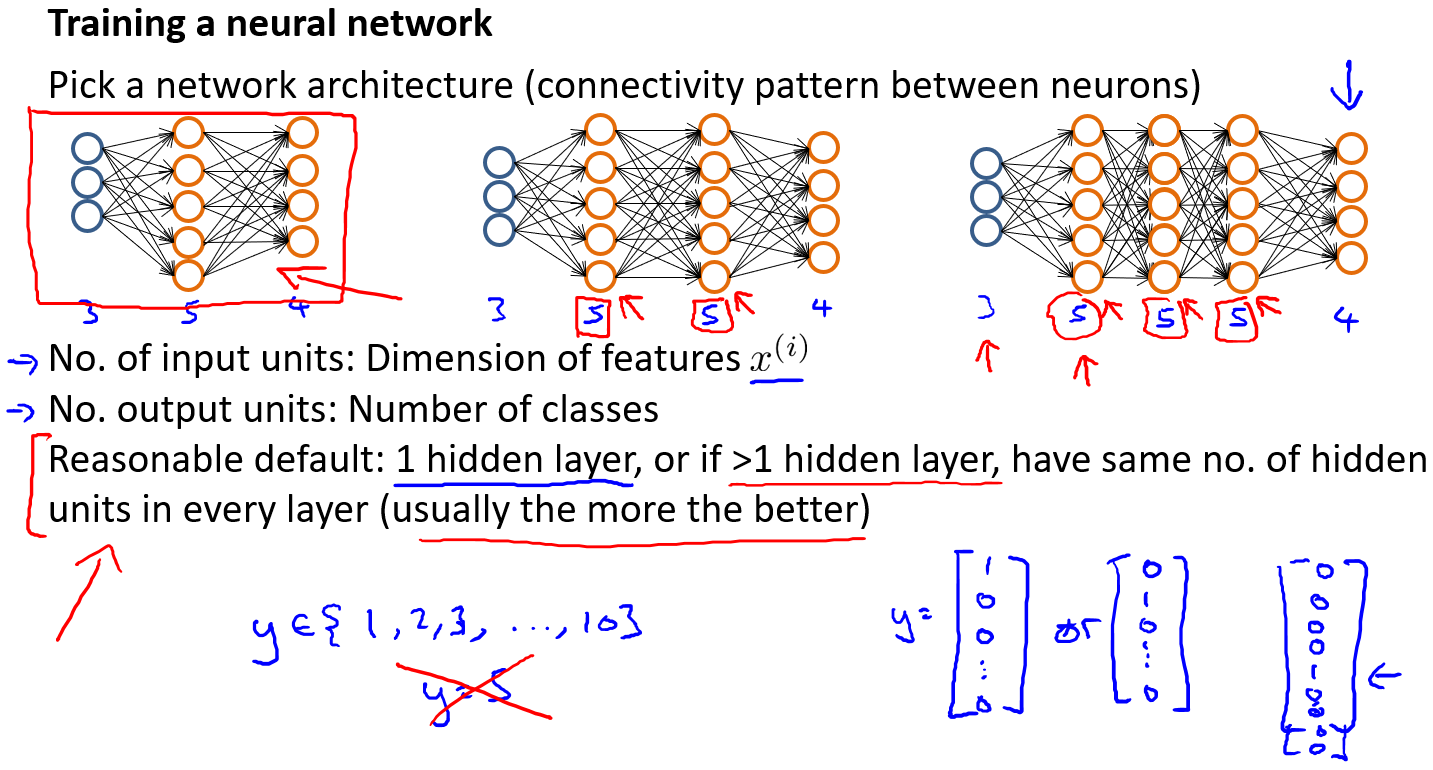
网络架构
第一层的单元数即我们训练集的特征数量。
最后一层的单元数是我们训练集的结果的类的数量。
如果隐藏层数大于1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好。
我们真正要决定的是隐藏层的层数和每个中间层的单元数。
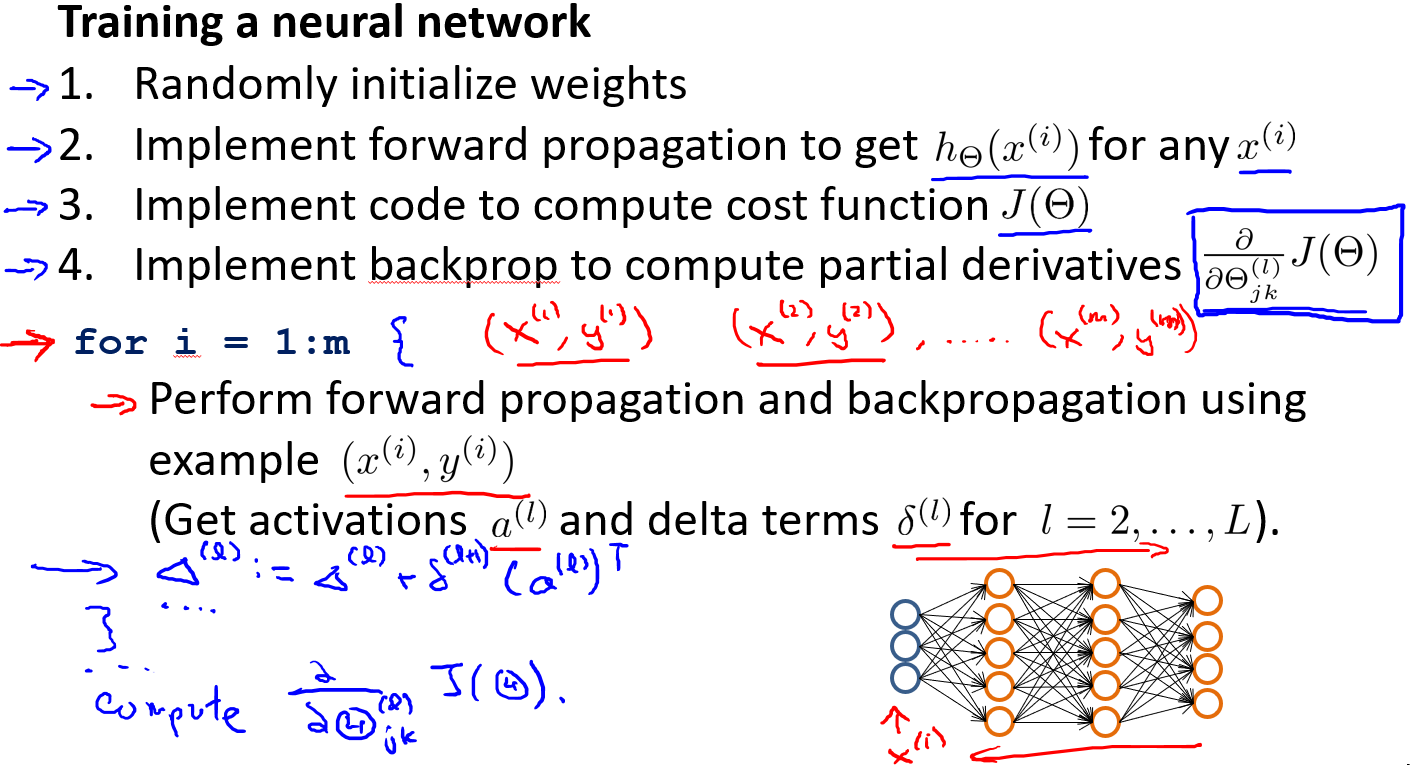
训练步骤
- 参数的随机初始化
- 利用正向传播方法计算所有的$h_\theta(x)$
- 编写计算代价函数$J$的代码
- 利用反向传播方法计算所有偏导数
- 利用数值检验方法检验这些偏导数
- 使用优化算法来最小化代价函数

算法性能优化
错误的方向
我们不应该随机选择下述的某种方法来改进我们的算法,而是运用一些机器学习诊断法来帮助我们知道上面哪些方法对我们的算法是有效的。
- 获得更多的训练样本——通常是有效的,但代价较大,下面的方法也可能有效,可考虑先采用下面的几种方法。
- 尝试减少特征的数量
- 尝试获得更多的特征
- 尝试增加多项式特征
- 尝试减少正则化程度$\lambda$
- 尝试增加正则化程度$\lambda$
正确的建议
评估一个假设:将数据分成训练集和测试集,通过训练集让我们的模型学习得出其参数后,计算得到误差最小的,对测试集运用该模型。
模型选择和交叉验证集:将数据分成训练集、测试集和交叉验证集,通过训练集让我们的不同模型学习得出其参数后,使用交叉验证集运用这些模型,计算得到误差最小的,对测试集使用该模型。
诊断偏差和方差
偏差:是指一个模型的在不同训练集上的平均性能和最优模型的差异。偏差可以用来衡量一个模型的拟合能力。偏差越大,预测值平均性能越偏离最优模型。
方差:描述的是 一个模型在不同训练集上的差异,描述的是一个模型在不同训练集之间的差异,表示模型的泛化能力,方差越小,模型的泛化能力越强。
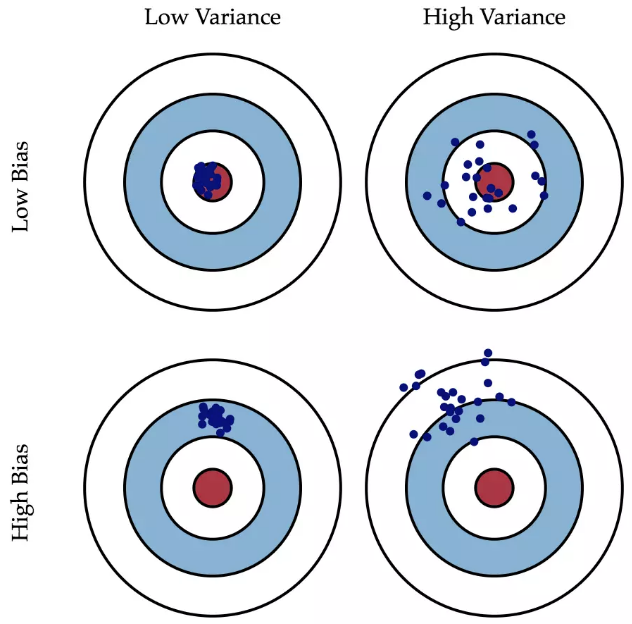
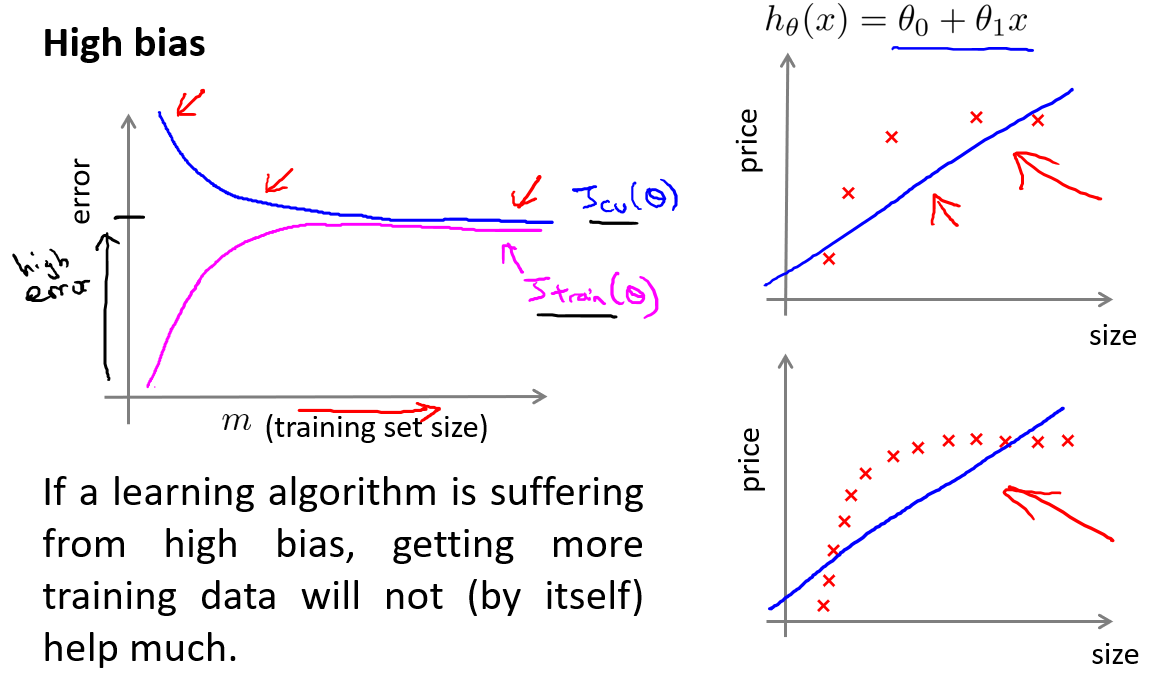
高偏差:欠拟合
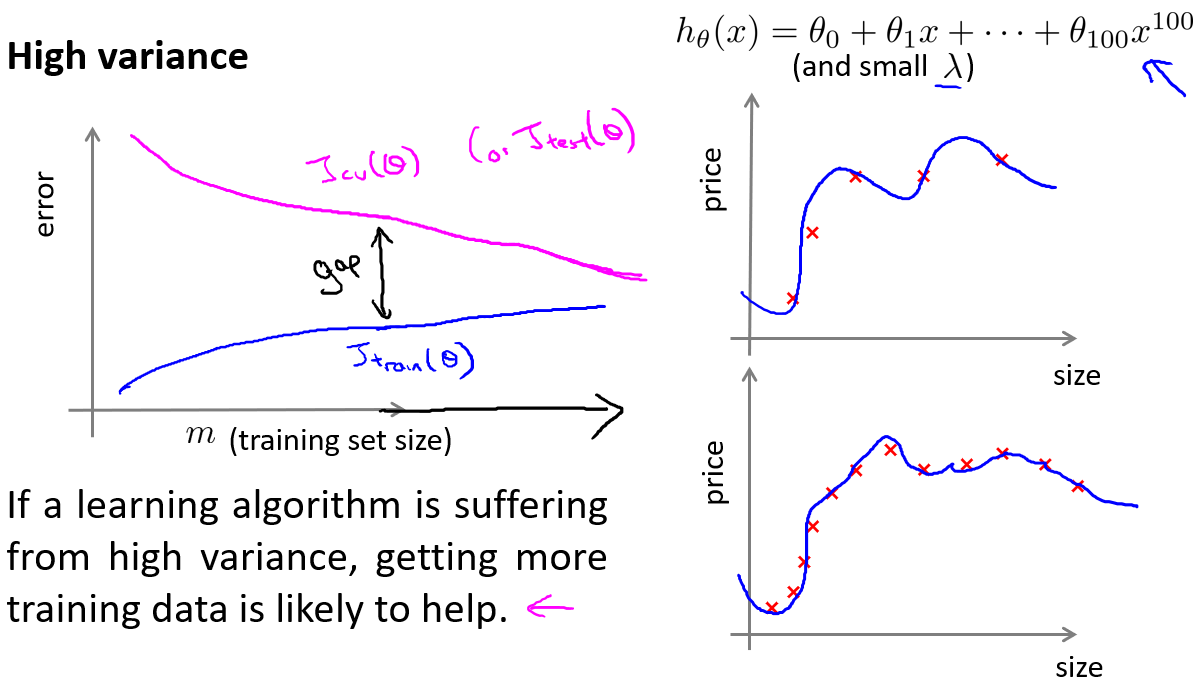
高方差:过拟合
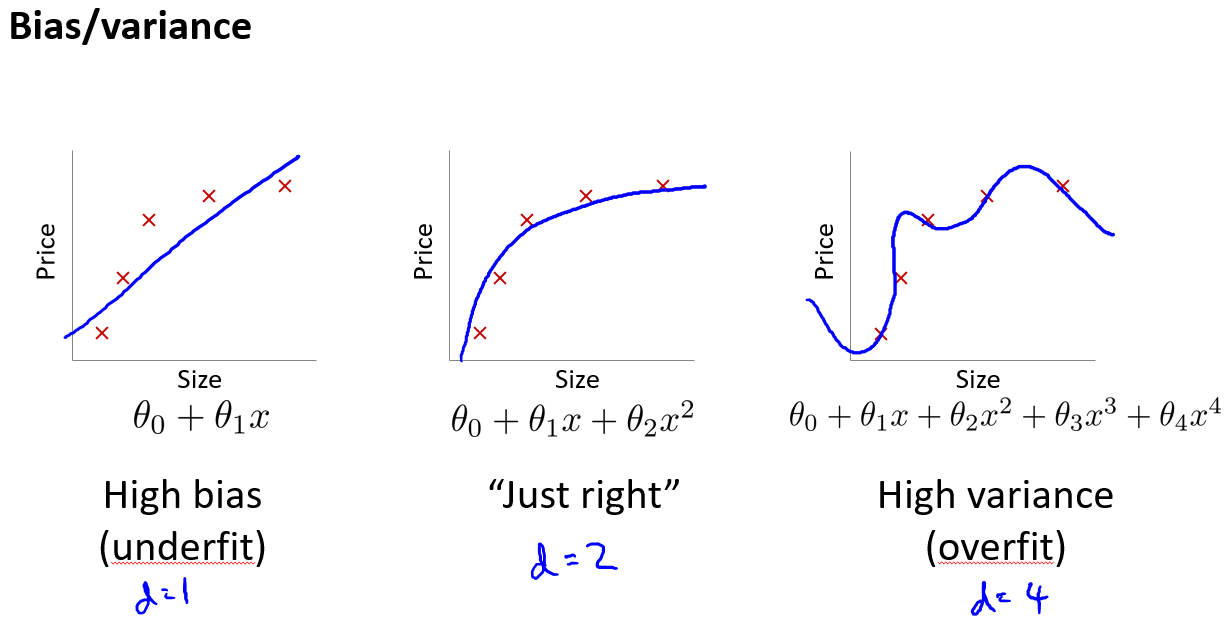
高偏差,验证集和训练集的损失函数很接近
高方差,验证集的损失函数远远大于训练集
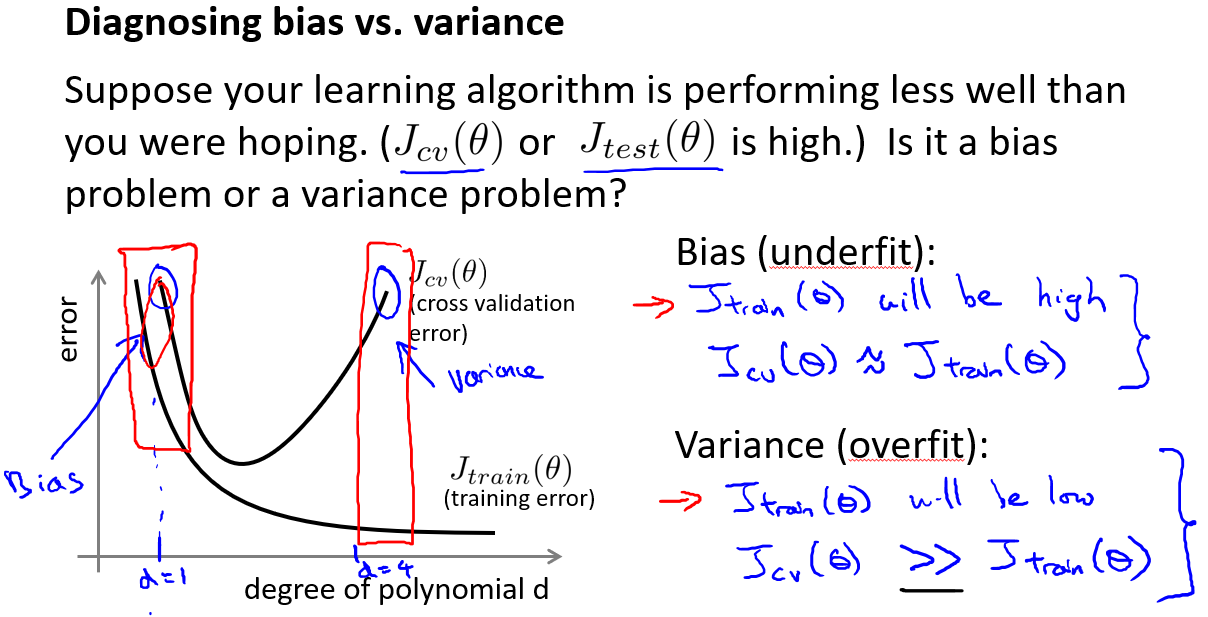
正则化和偏差/方差
选择$\lambda$的方法为:
- 使用训练集训练出n个不同程度正则化的模型
- 用n个模型分别对交叉验证集计算的出交叉验证误差
- 选择得出交叉验证误差最小的模型
- 运用步骤3中选出模型对测试集计算得出推广误差,我们也可以同时将训练集和交叉验证集模型的代价函数误差与λ的值绘制在一张图表上:
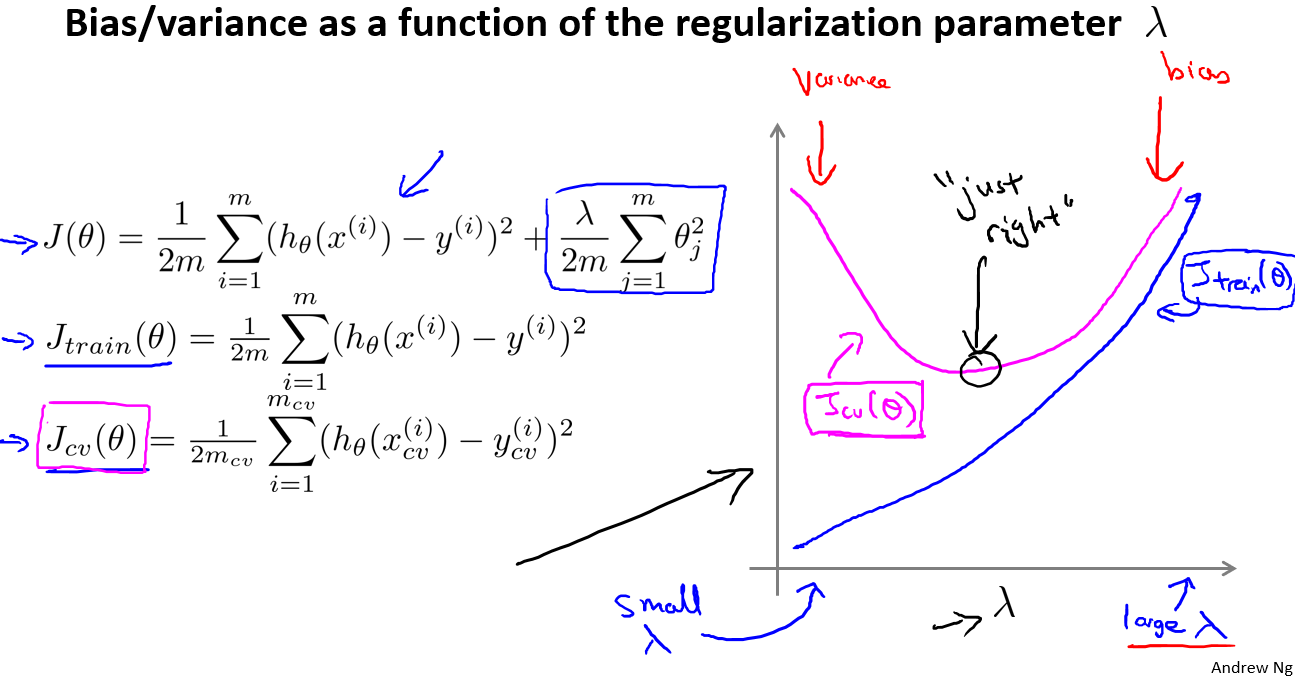
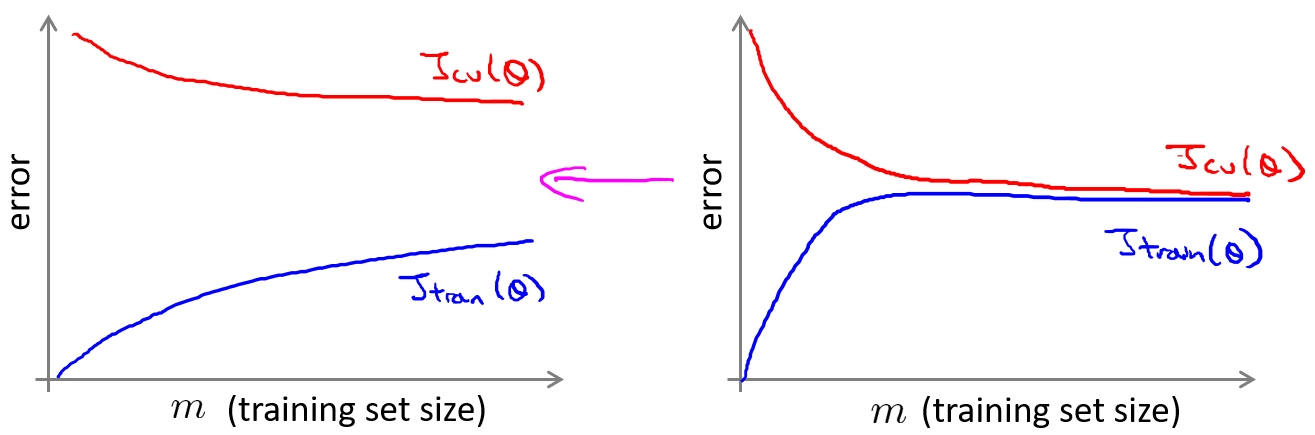
学习曲线
学习曲线就是一种很好的工具,我经常使用学习曲线来判断某一个学习算法是否处于偏差、方差问题。学习曲线是学习算法的一个很好的合理检验(sanity check)。学习曲线是将训练集误差和交叉验证集误差作为训练集样本数量($m$)的函数绘制的图表。
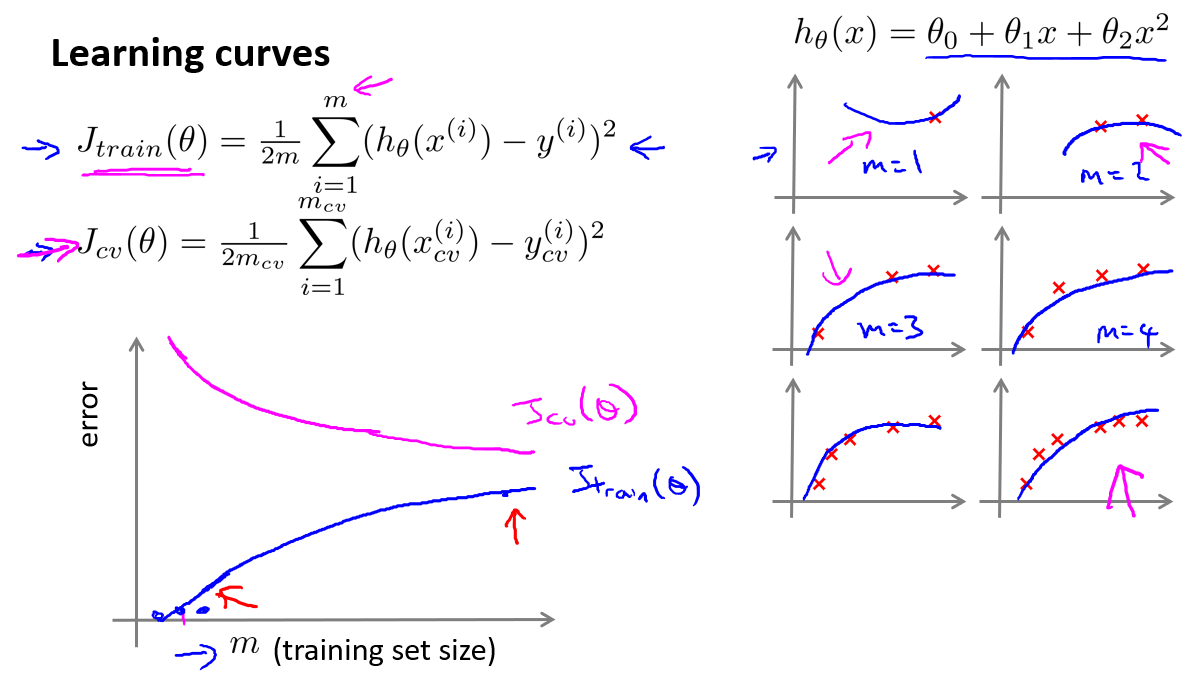
在高偏差/欠拟合的情况下,增加数据到训练集不一定能有帮助。
在高方差/过拟合的情况下,增加更多数据到训练集可能可以提高算法效果。
有针对的做法
获得更多的训练样本——解决高方差
尝试减少特征的数量——解决高方差
尝试获得更多的特征——解决高偏差
尝试增加多项式特征——解决高偏差
尝试减少正则化程度λ——解决高偏差
尝试增加正则化程度λ——解决高方差
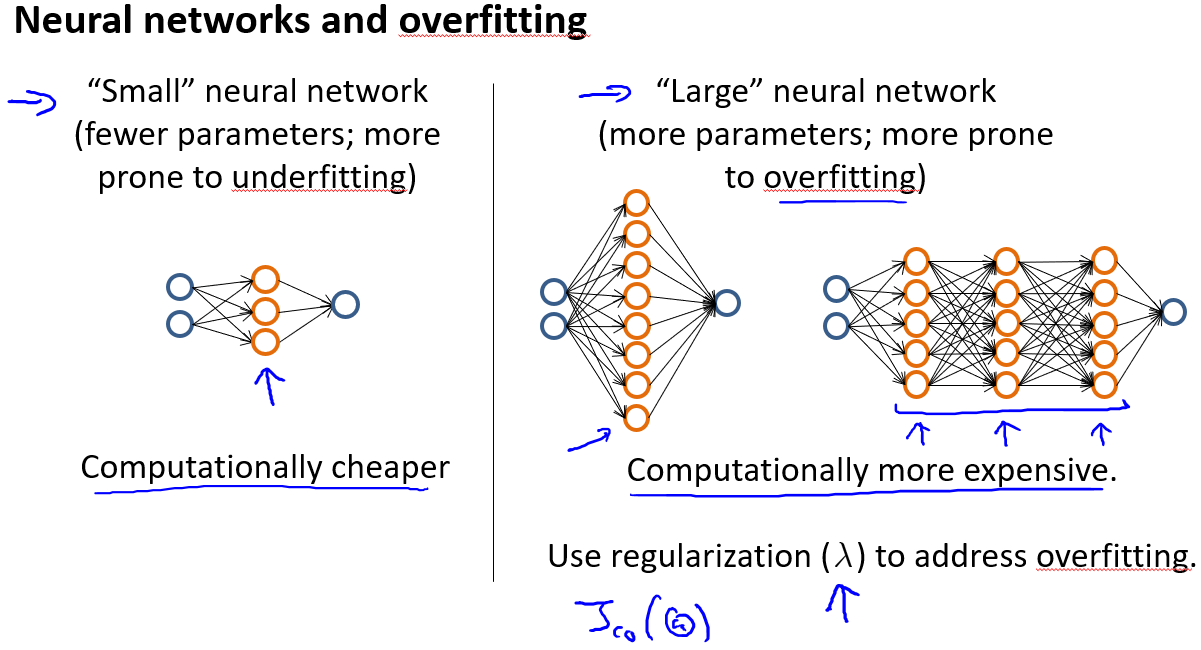
对于神经网络:
使用较小的神经网络,类似于参数较少的情况,容易导致高偏差和欠拟合,但计算代价较小;使用较大的神经网络,类似于参数较多的情况,容易导致高方差和过拟合,虽然计算代价比较大,但是可以通过正则化手段来调整而更加适应数据。
对于神经网络中的隐藏层的层数的选择,通常从一层开始逐渐增加层数,为了更好地作选择,可以把数据分为训练集、交叉验证集和测试集,针对不同隐藏层层数的神经网络训练神经网络,然后选择交叉验证集代价最小的神经网络。
机器学习系统设计
给定机器学习任务,首先要做什么?
以一个垃圾邮件分类器算法为例进行讨论为了构建这个分类器算法,我们可以做很多事,例如:
收集更多的数据,让我们有更多的垃圾邮件和非垃圾邮件的样本
基于邮件的路由信息开发一系列复杂的特征
基于邮件的正文信息开发一系列复杂的特征,包括考虑截词的处理
为探测刻意的拼写错误(把watch 写成w4tch)开发复杂的算法
总结一下就是:
数据获取
特征提取
其次,构建一个学习算法的推荐方法为:
从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算法
绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择
进行误差分析:人工检查交叉验证集中我们算法中产生预测误差的样本,看看这些样本是否有某种系统化的趋势
总结一下就是:
快速实现一个较为简单快速、即便不是那么完美的算法。看看算法造成的错误,通过误差分析,来看看他犯了什么错,提出新的想法,快速地发现你尝试的这些想法是否能够提高算法的表现,从而你会更快地做出决定,在算法中放弃什么,吸收什么误差分析可以帮助我们系统化地选择该做什么。
既然我们要做误差分析就需要构建评价指标,但在构建之前我们需要解决类偏斜(skewed classes)问题,即样本分布极度不均衡。
查准率(Precision)和查全率(Recall) 我们将算法预测的结果分成四种情况:
正确肯定(True Positive,TP):预测为真,实际为真
正确否定(True Negative,TN):预测为假,实际为假
错误肯定(False Positive,FP):预测为真,实际为假
错误否定(False Negative,FN):预测为假,实际为真
查准率(精确率)=。例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
查全率(召回率)=。例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。
| 预测值 | |||
|---|---|---|---|
| Positive | Negtive | ||
| 实际值 | Positive | TP | FN |
| Negtive | FP | TN |
查准率和查全率之间的权衡
如果我们希望更高的查准率,我们可以使用比0.5更大的阀值,如0.7,0.9。这样做我们会减少错误预测病人为恶性肿瘤的情况,同时却会增加未能成功预测肿瘤为恶性的情况。
如果我们希望提高查全率,尽可能地让所有有可能是恶性肿瘤的病人都得到进一步地检查、诊断,我们可以使用比0.5更小的阀值,如0.3,0.1。
我们可以将不同阀值情况下,查全率与查准率的关系绘制成图表,曲线的形状根据数据的不同而不同:

得到大量的数据并在某种类型的学习算法中进行训练,可以是一种有效的方法来获得一个具有良好性能的学习算法。大部分算法,都具有相似的性能,其次,随着训练数据集的增大,算法的性能也都对应地增强了。
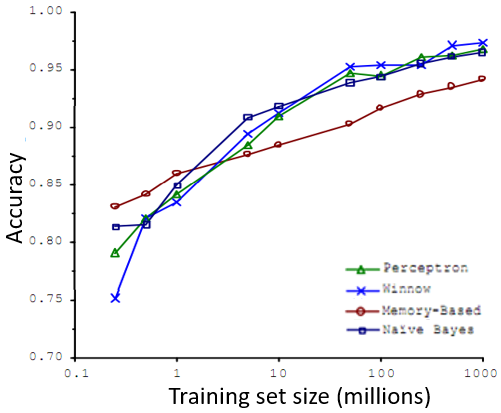
这些结果表明,许多不同的学习算法有时倾向于表现出非常相似的表现,这还取决于一些细节,但是真正能提高性能的,是你能够给一个算法大量的训练数据。像这样的结果,引起了一种在机器学习中的普遍共识:”取得成功的人不是拥有最好算法的人,而是拥有最多数据的人”。
在训练参数较多的模型时,如果训练集比参数的数量还大,甚至是更多,那么这些算法就不太可能会过度拟合。也就是说训练误差有希望接近测试误差。因此偏差问题,我么将通过确保有一个具有很多参数的学习算法来解决,以便我们能够得到一个较低偏差的算法,并且通过用非常大的训练集来保证。在此没有方差问题,我们的算法将没有方差,并且通过将这两个值放在一起,我们最终可以得到一个低误差和低方差的学习算法。
支持向量机
算法框架
SVM without Kernels
SVM with Kernels
模型建立
从logistic回归出发进行修改得到本质上的SVM。
如果有一个 $y=1$的样本,现在我们希望$h\theta(x)$ 趋近1。因为我们想要正确地将此样本分类,这就意味着当 $h\theta(x)$趋近于1时,$\theta^Tx$ 应当远大于0。相反地,如果我们有另一个样本,即$y=0$。我们希望假设函数的输出值将趋近于0,这对应于$\theta^Tx$则希望其远小于0,
假如将损失函数近似为一个线性函数,简化的同时也更加有利于求解速度
因此优化目标从
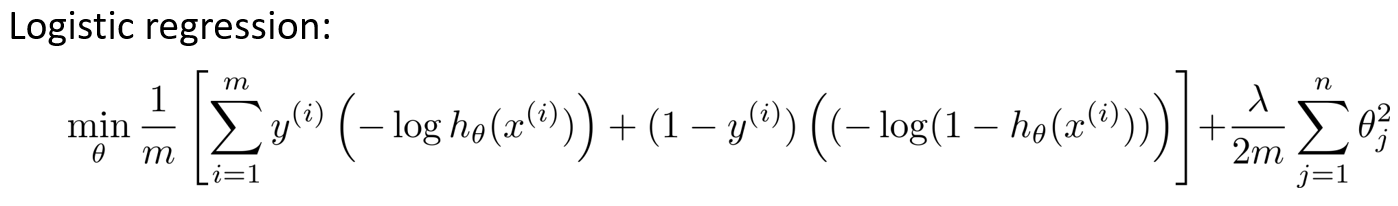
变成了(注意$\lambda(C)$和$m$的变化,可以理解为同除某数优化结果不变)上图左边的函数为$cost_1$,右图为$cost_2$。
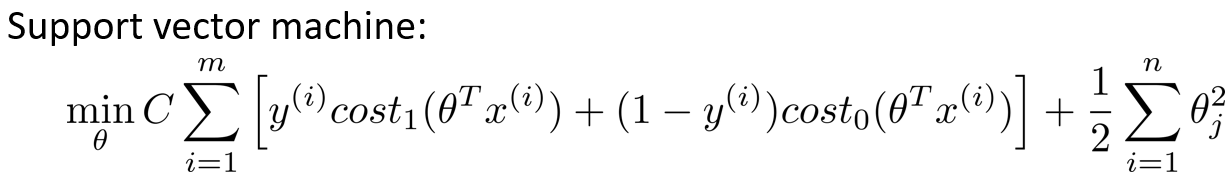
安全距离
事实上,如果有一个正样本$y=1$,则其实仅仅要求$\theta^Tx$大于等于0,就能将该样本恰当分出,这是因为如果$\theta^Tx$>1的话,我们的模型代价函数值为0,类似地,如果你有一个负样本,则仅需要$\theta^Tx$\<=0就会将负例正确分离,但是,支持向量机的要求更高,不仅仅要能正确分开输入的样本,即不仅仅要求$\theta^Tx$>0,我们需要的是比0值大很多,比如大于等于1,我也想这个比0小很多,比如我希望它小于等于-1,这就相当于在支持向量机中嵌入了一个额外的安全因子,或者说安全的间距因子。

另外,如果 $C$非常大,则最小化代价函数的时候,将会很希望找到一个使第一项为0的最优解。因此对这样的一个数据集,也许我们将选择这样的决策界,从而最大间距地分离开正样本和负样本。那么在让代价函数最小化的过程中,我们希望找出在$y=1$和$y=0$两种情况下都使得代价函数中左边的这一项尽量为零的参数。如果我们找到了这样的参数,则我们的最小化问题便转变成:
决策边界
事实上,支持向量机现在要比这个大间距分类器所体现得更成熟,尤其是当你使用大间距分类器的时候,你的学习算法会受异常点(outlier) 的影响。比如我们加入一个额外的正样本。
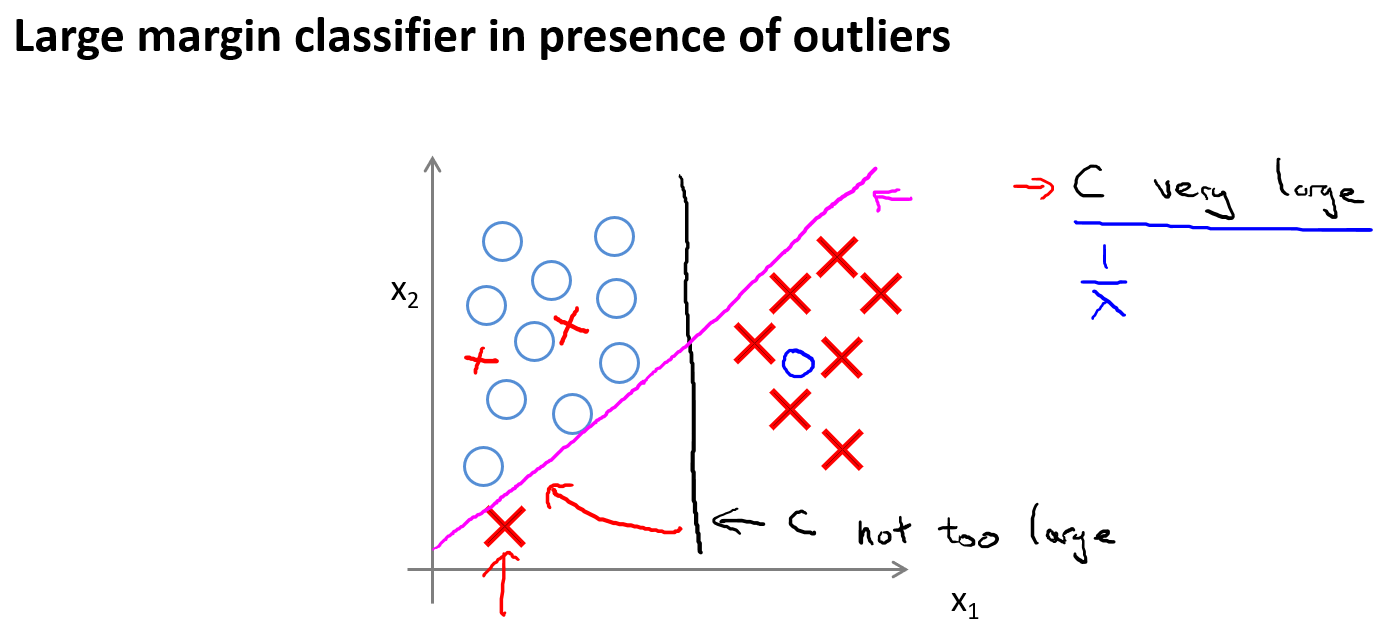
在这里,如果加了这个样本,为了将样本用最大间距分开,也许最终会得到一条类似这样的决策界,对么?就是这条粉色的线,仅仅基于一个异常值,仅仅基于一个样本,就将我决策界从这条黑线变到这条粉线,这实在是不明智的。而如果正则化参数$C$,设置的非常大,这事实上正是支持向量机将会做的。它将决策界,从黑线变到了粉线,但是如果$C$ 设置的小一点,如果将C设置的不要太大,则最终会得到这条黑线,当然数据如果不是线性可分的,如果你在这里有一些正样本或者你在这里有一些负样本,则支持向量机也会将它们恰当分开。因此,大间距分类器的描述,仅仅是从直观上给出了正则化参数$C$非常大的情形,同时,要提醒你$C$的作用类似于$\frac{1}{\lambda}$,$\lambda$是我们之前使用过的正则化参数。这只是$C$非常大的情形,或者等价地 $\lambda$ 非常小的情形。你最终会得到类似粉线这样的决策界,但是实际上应用支持向量机的时候,当$C$不是非常非常大的时候,它可以忽略掉一些异常点的影响,得到更好的决策界。甚至当数据不是线性可分的时候,支持向量机也可以给出好的结果。
回顾 $C=\frac{1}{\lambda}$,因此:
$C$ 较大时,相当于 $\lambda$ 较小,可能会导致过拟合,高方差。
$C$ 较小时,相当于$\lambda$较大,可能会导致低拟合,高偏差。
数学含义
向量内积的含义:一个向量在另一个向量上投影的长度。
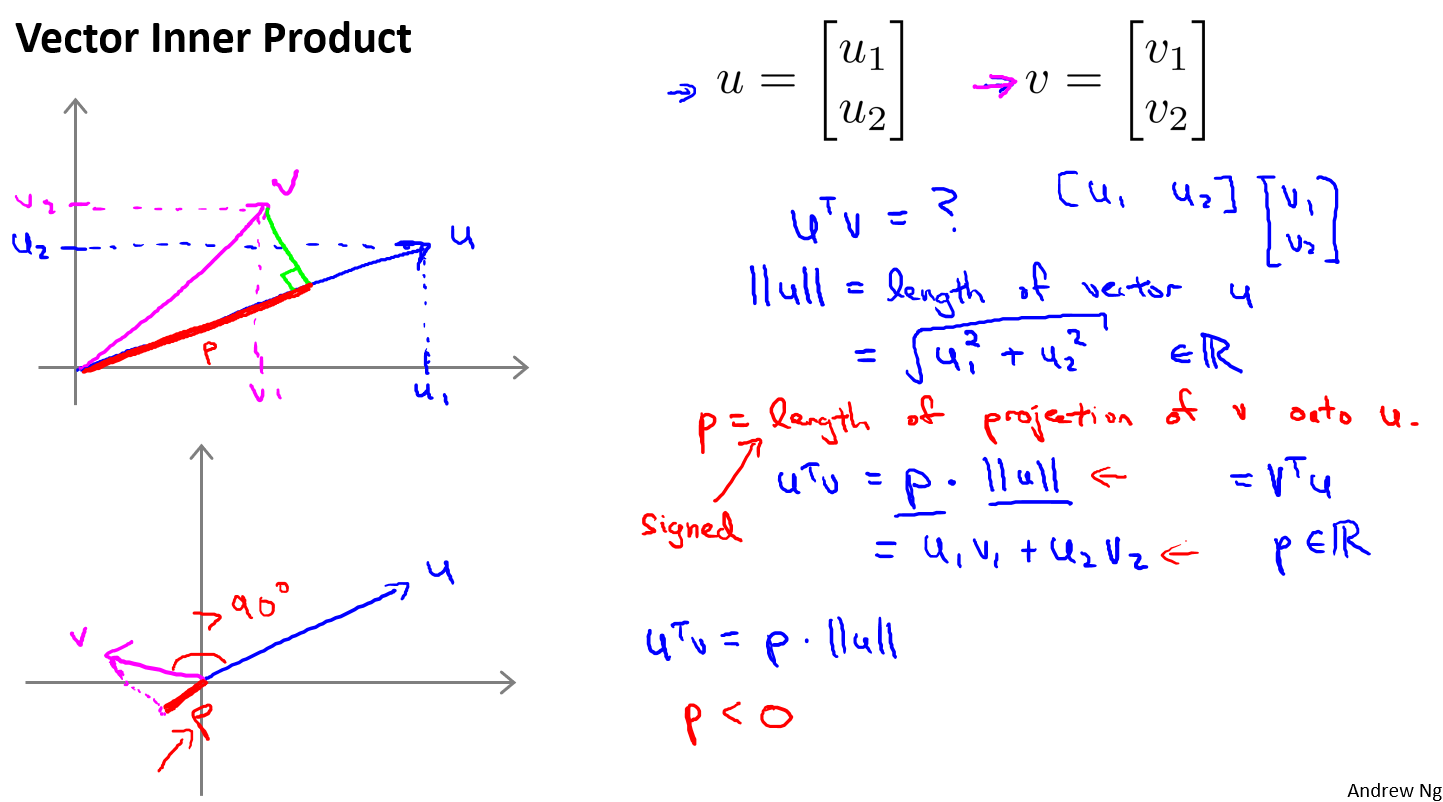
而支持向量机做的全部事情,就是极小化参数向量 范数的平方,或者说长度的平方。这相当于最大化在向量上的投影,即最大化间距(margin),如图所示。
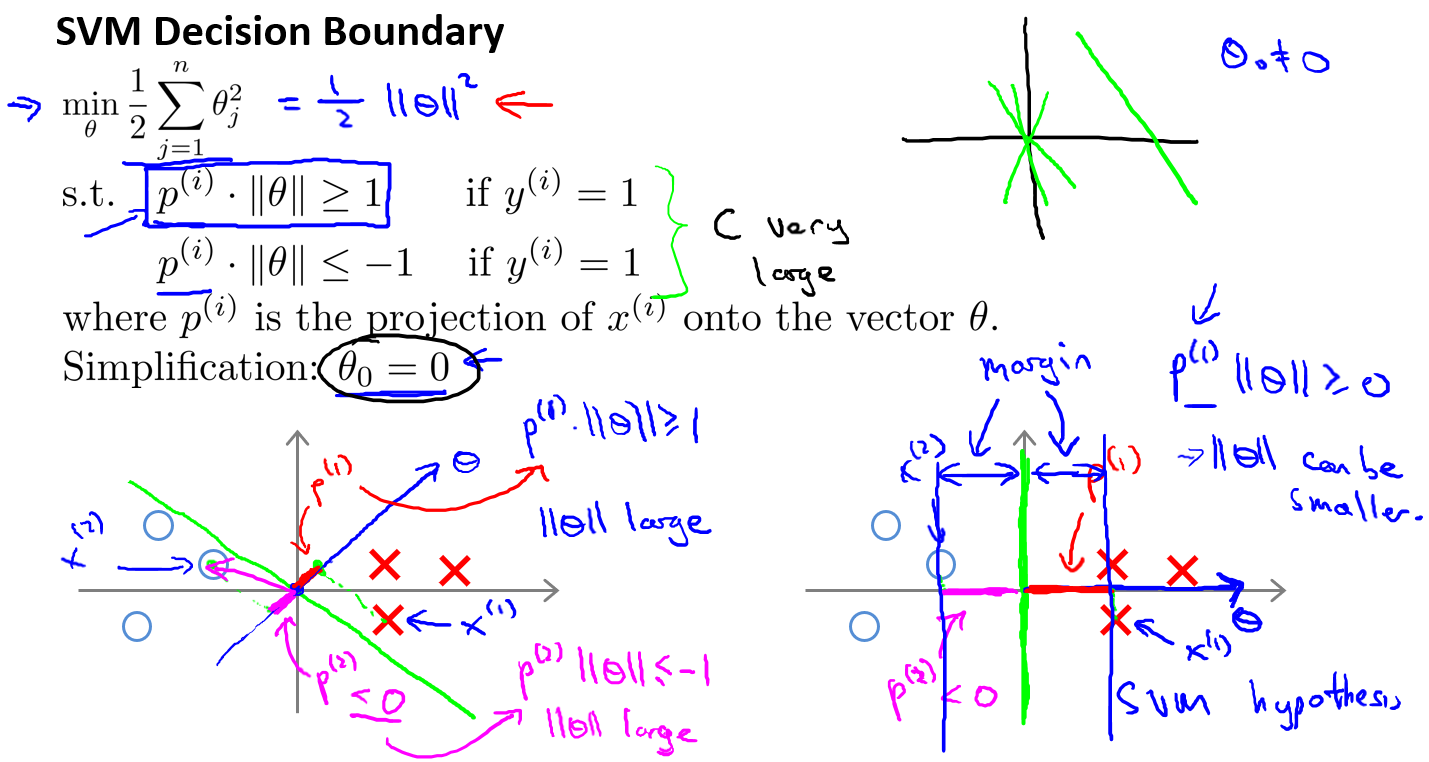
核函数
对于无法用直线进行分隔的分类问题,可以使用高级数的多项式模型来解决
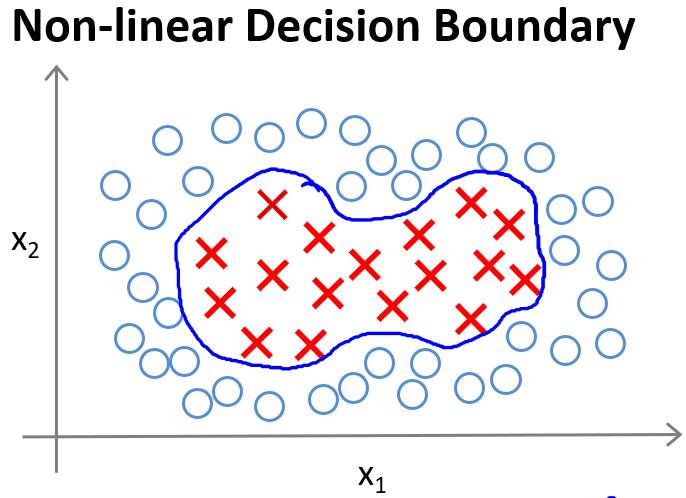
引入
为了获得上图所示的判定边界,我们的模型可能是的形式。我们可以用一系列的新的特征$f$来替换模型中的每一项。例如令:得到 。然而,除了对原有的特征进行组合以外,有没有更好的方法来构造?我们可以利用核函数来计算出新的特征。
给定一个训练样本,我们利用的各个特征与我们预先选定的地标(landmarks)的近似程度来选取新的特征。
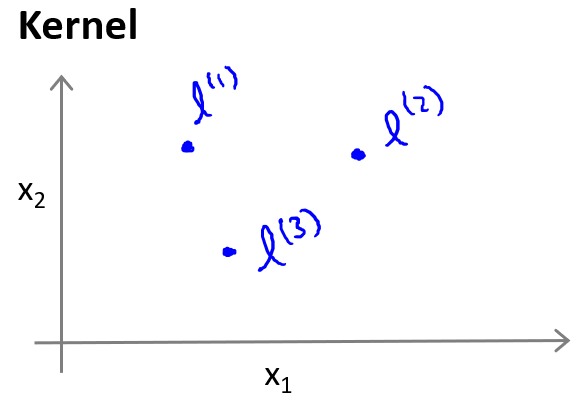
例如:${f}_{1}=similarity(x,{l}^{(1)})=e(-\frac{\begin{Vmatrix}x-l^{(l)}\end{Vmatrix}^2}{2{\sigma }^2})$
其中:$\begin{Vmatrix}x-l^{(l)}\end{Vmatrix}^2=\sum_{j=1}^n(x_j-l_j^{(l)})^2$,为实例$x$中所有特征与地标$l^{(1)}$之间的距离的和。上例中的$similarity(x,{l}^{(1)})$就是核函数,具体而言,这里是一个高斯核函数(Gaussian Kernel)。
这些地标的作用在于:如果一个训练样本与地标之间的距离近似于0,则新特征$f$近似于$e^{-0}=1$,如果训练样本$x$与地标$l$之间距离较远,则$f$近似于$e^{-(一个较大的数)}=0$。
参数含义
假设我们的训练样本含有两个特征[$x_{1}$ $x{_2}$],给定地标$l^{(1)}$与不同的$\sigma$值,见下图:
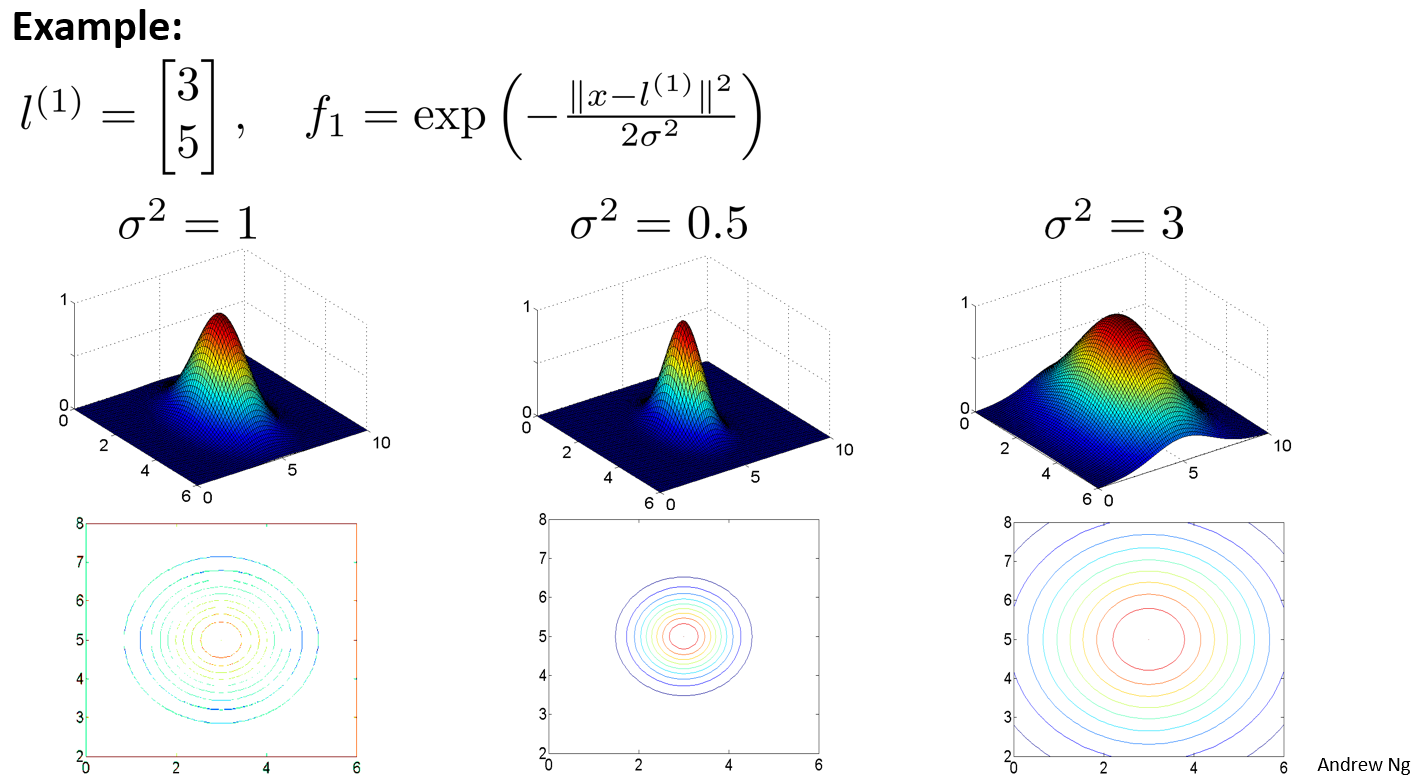
图中水平面的坐标为 ,而垂直坐标轴代表$f$。可以看出,只有当$x$与重合时$f$才具有最大值。随着$x$的改变$f$值改变的速率受到$\sigma^2$的控制。
在下图中,当样本处于洋红色的点位置处,因为其离更近,但是离和较远,因此接近1,而,接近0。因此,因此预测。同理可以求出,对于离较近的绿色点,也预测,但是对于蓝绿色的点,因为其离三个地标都较远,预测。
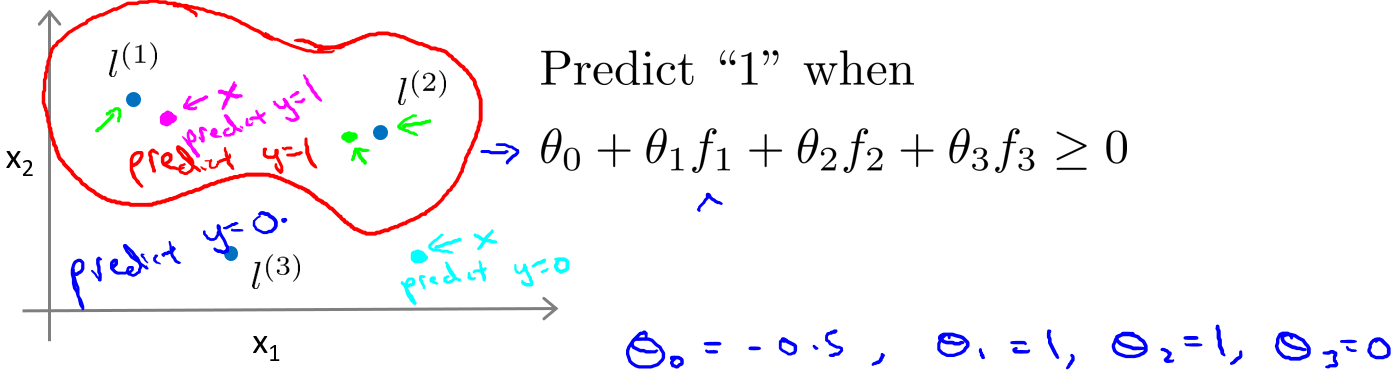
这样,图中红色的封闭曲线所表示的范围,便是我们依据一个单一的训练样本和我们选取的地标所得出的判定边界,在预测时,我们采用的特征不是训练样本本身的特征,而是通过核函数计算出的新特征$f_1,f_2,f_3$。
构建核函数SVM
对于地标的选择,通常是根据训练集的数量选择地标的数量,即如果训练集中有个样本,则我们选取个地标,并且令:$l^{(1)}=x^{(1)},l^{(2)}=x^{(2)},…..,l^{(m)}=x^{(m)}$。这样做的好处在于:现在我们得到的新特征是建立在原有特征与训练集中所有其他特征之间距离的基础之上的,即:
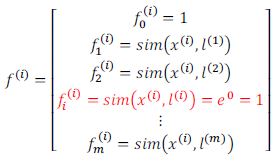
下面我们将核函数运用到支持向量机中,修改我们的支持向量机假设为:
• 给定$x$,计算新特征$f$,当$θ^Tf\ge0$ 时,预测 $y=1$,否则反之。
相应地修改代价函数为:
在具体实施过程中,还需要对最后的正则化项进行些微调整,在计算时,我们用$θ^TMθ$代替$θ^Tθ$,其中$M$是根据选择的核函数而不同的一个矩阵。这样做的原因是为了简化计算。
理论上讲,可以在逻辑回归中使用核函数,但是上面使用 $M$来简化计算的方法不适用与逻辑回归,因此计算将非常耗费时间。
在此,使用现有的软件包(如liblinear,libsvm等)。在使用这些软件包最小化我们的代价函数之前,通常需要编写核函数,并且如果使用高斯核函数,那么在使用之前进行特征缩放是非常必要的。
另外,支持向量机也可以不使用核函数,不使用核函数又称为线性核函数(linear kernel),当不采用非常复杂的函数,或者训练集特征非常多而样本非常少的时候,可以采用这种不带核函数的支持向量机。
SVM参数(结合参数含义)
下面是支持向量机的两个参数$C$和$\sigma$的影响:
$C=\frac{1}{\lambda}$
$C$ 较大时,相当于$\lambda$较小,可能会导致过拟合,高方差;
$C$ 较小时,相当于$\lambda$较大,可能会导致低拟合,高偏差;
$\sigma$较大时,可能会导致低方差,高偏差;
$\sigma$较小时,可能会导致低偏差,高方差。
使用支持向量机
其他核函数
不是所有的相似函数都能成为核函数,其还必须满足默塞尔定理(Mercer’s
Theorem)

在高斯核函数之外我们还有其他一些选择,如:
多项式核函数(Polynomial Kernel)
字符串核函数(String kernel)
卡方核函数( chi-square kernel)
直方图交集核函数(histogram intersection kernel)
等等…
这些核函数的目标也都是根据训练集和地标之间的距离来构建新特征,这些核函数需要满足Mercer’s定理,才能被支持向量机的优化软件正确处理。
多类分类问题
假设我们利用之前介绍的一对多方法来解决一个多类分类问题。如果一共有$k$个类,则我们需要$k$个模型,以及$k$个参数向量${\theta}$。我们同样也可以训练$k$个支持向量机来解决多类分类问题。但是大多数支持向量机软件包都有内置的多类分类功能,我们只要直接使用即可。
经验
尽管你不去写你自己的SVM的优化软件,但是你也需要做几件事:
1、是提出参数$C$的选择。我们在之前的视频中讨论过误差/方差在这方面的性质。
2、你也需要选择内核参数或你想要使用的相似函数,其中一个选择是:我们选择不需要任何内核参数,没有内核参数的理念,也叫线性核函数。因此,如果有人说他使用了线性核的SVM(支持向量机),这就意味这他使用了不带有核函数的SVM(支持向量机)。
SVM v.s logistic regression
从逻辑回归模型,我们得到了支持向量机模型,在两者之间,我们应该如何选择呢?
下面是一些普遍使用的准则:
$n$为特征数,$m$为训练样本数。
(1)如果相较于$m$而言,$n$要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
(2)如果$n$较小,而且$m$大小中等,例如$n$在 1-1000 之间,而$m$在10-10000之间,使用高斯核函数的支持向量机。
(3)如果$n$较小,而$m$较大,例如$n$在1-1000之间,而$m$大于50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。
值得一提的是,神经网络在以上三种情况下都可能会有较好的表现,但是训练神经网络可能非常慢,选择支持向量机的原因主要在于它的代价函数是凸函数,不存在局部最小值。
K-means
算法框架
注:$K$是指簇中心数量,$k$是指簇中心索引
算法步骤
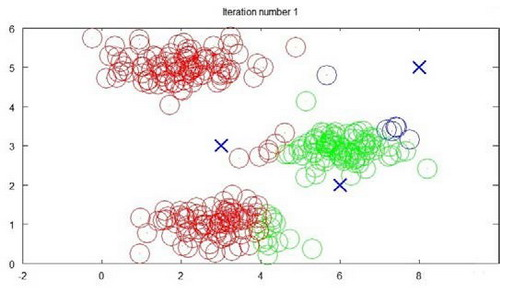
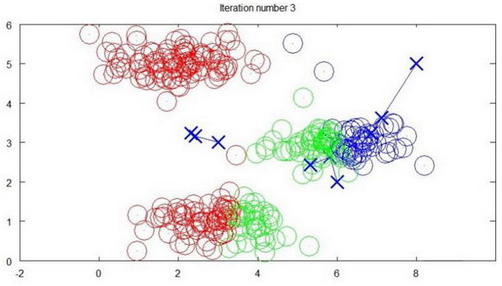
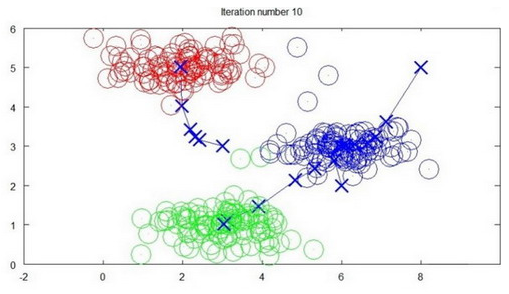
算法分为两个步骤,第一个for循环是赋值步骤,即:对于每一个样例$i$,计算其应该属于的类。第二个for循环是聚类中心的移动,即:对于每一个类$K$,重新计算该类的质心。
可视化
迭代1次
迭代3次
迭代10次
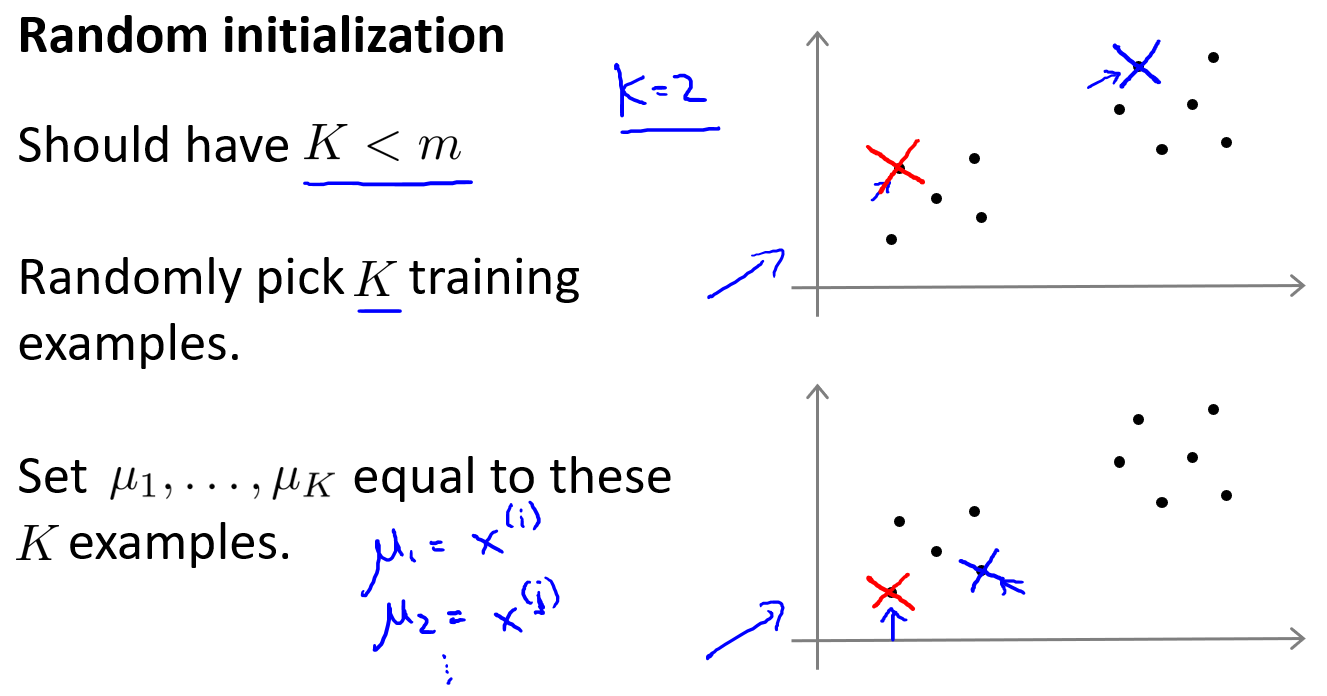
随机初始化
随机选择$k$个样本点作为初始簇中心
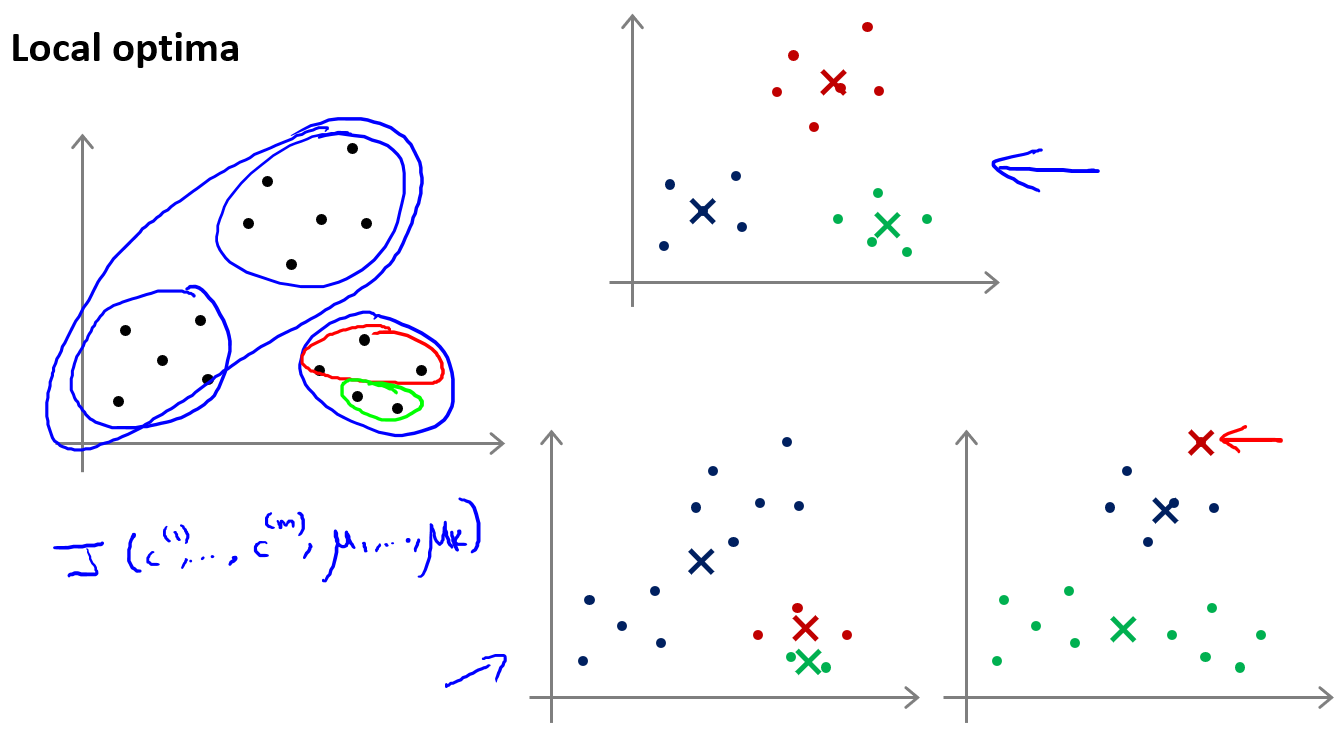
局部最优问题,解决方法是多次随机初始化,选择cost最低的结果
算法步骤

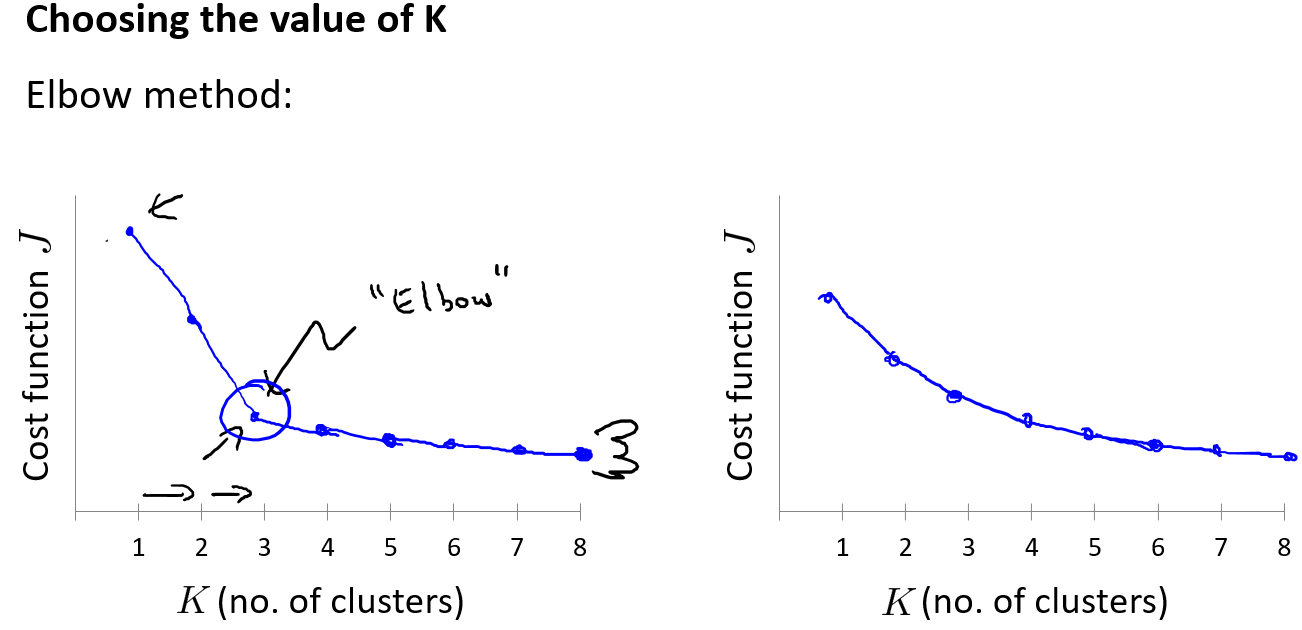
K的选择
“Elbow method”
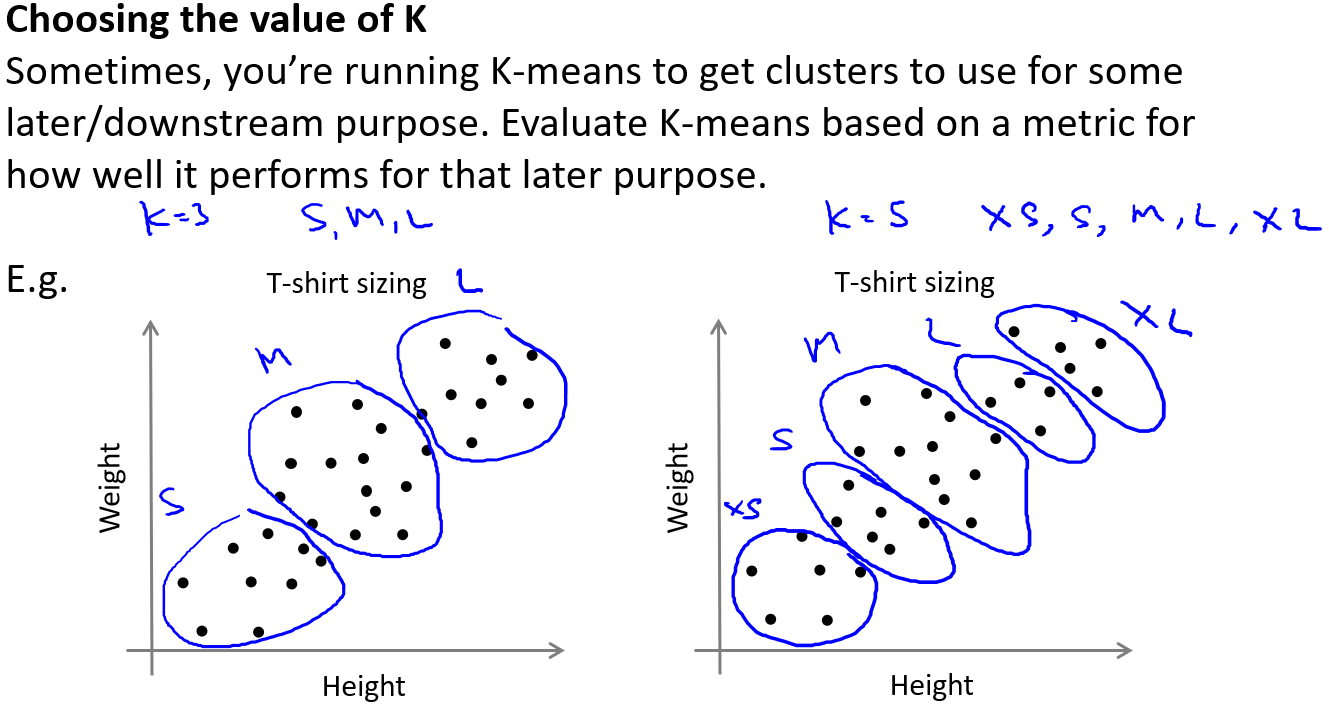
later purpose
主成分分析PCA
动机
- 数据压缩
- 数据可视化
问题概述
在PCA中,我们要做的是找到一个方向向量(Vector direction),当我们把所有的数据都投射到该向量上时,我们希望投射平均均方误差能尽可能地小。方向向量是一个经过原点的向量,而投射误差是从特征向量向该方向向量作垂线的长度。
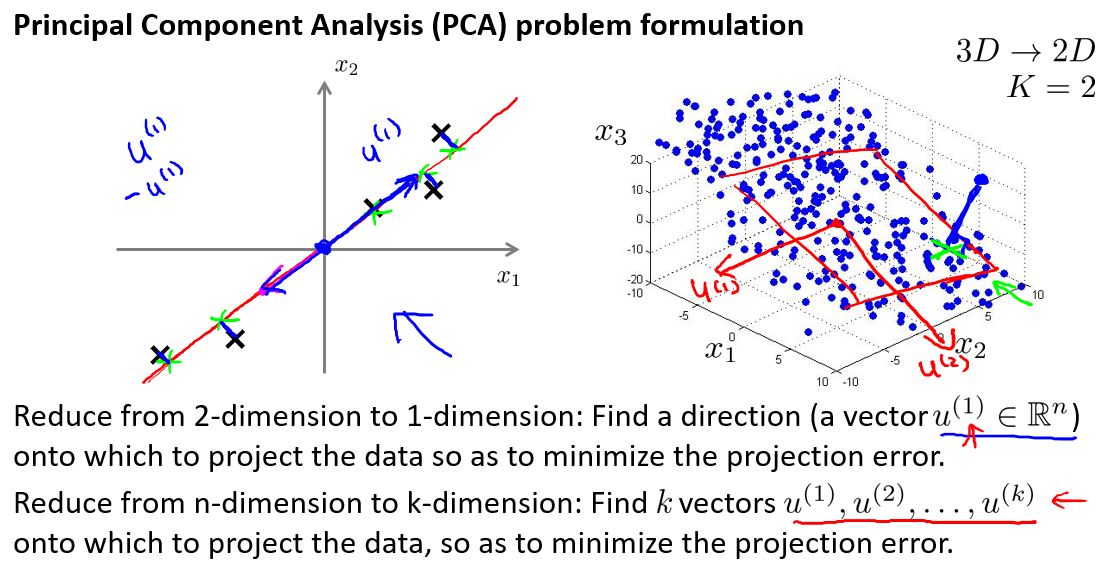
主成分分析与线性回归是两种不同的算法。主成分分析最小化的是投射误差(Projected Error),而线性回归尝试的是最小化预测误差。线性回归的目的是预测结果,而主成分分析不作任何预测。
算法特点
PCA将$n$个特征降维到$k$个,可以用来进行数据压缩,如果100维的向量最后可以用10维来表示,那么压缩率为90%。同样图像处理领域的KL变换使用PCA做图像压缩。但PCA 要保证降维后,还要保证数据的特性损失最小。
PCA技术的一大好处是对数据进行降维的处理。我们可以对新求出的“主元”向量的重要性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维从而简化模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
PCA技术的一个很大的优点是,它是完全无参数限制的。在PCA的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关,与用户是独立的。
但是,这一点同时也可以看作是缺点。如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高。
算法步骤

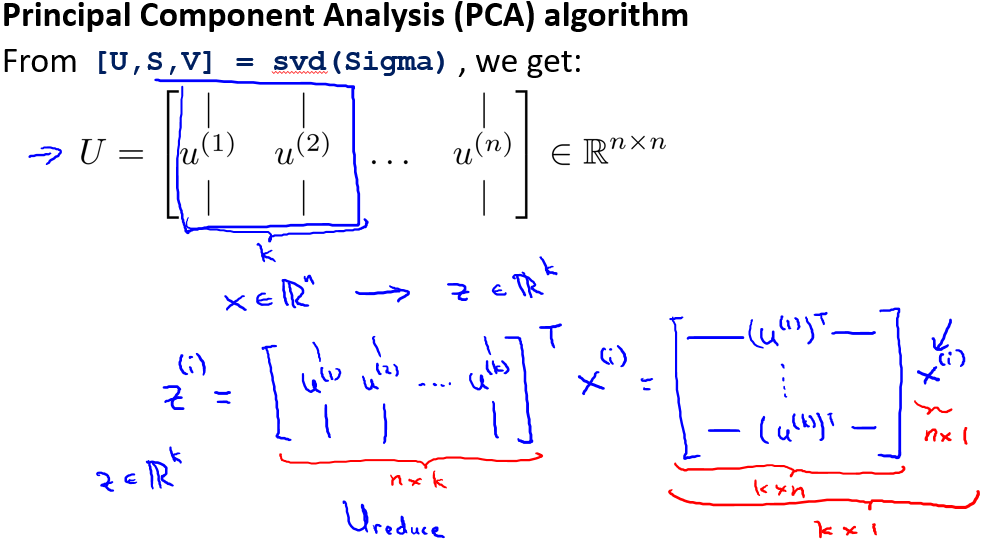

对于一个 $n×n$维度的矩阵,上式中的$U$是一个具有与数据之间最小投射误差的方向向量构成的矩阵。如果我们希望将数据从$n$维降至$k$维,我们只需要从$U$中选取前$k$个向量,获得一个$n×k$维度的矩阵,我们用表示,然后通过如下计算获得要求的新特征向量$z^{(i)}$:,其中$x$是$n×1$维的,因此结果为$k×1$维度。注,我们不对方差特征进行处理。
选择主成分的数量
主要成分分析是减少投射的平均均方误差:
训练集的方差为:$\frac{1}{m}\sum_{i=1}^m\begin{Vmatrix}x^{(i)}\end{Vmatrix}^2$
我们希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的$k$值。
如果我们希望这个比例小于1%,就意味着原本数据的偏差有99%都保留下来了,如果我们选择保留95%的偏差,便能非常显著地降低模型中特征的维度了。

我们可以先令$k=1$,然后进行主要成分分析,获得$U_{reduce}$和$z$,然后计算比例是否小于1%。如果不是的话再令$k=2$,如此类推,直到找到可以使得比例小于1%的最小$k$ 值(原因是各个特征之间通常情况存在某种相关性)。

还有一些更好的方式来选择$k$,当我们在Octave中调用“svd”函数的时候,我们获得三个参数:[U, S, V] = svd(sigma)。
其中的$S$是一个$n×n$的矩阵,只有对角线上有值,而其它单元都是0,我们可以使用这个矩阵来计算平均均方误差与训练集方差的比例:
也就是
在压缩过数据后,我们可以采用如下方法来近似地获得原有的特征:$x{appox}^{(i)}=U{reduce}z^{(i)}$
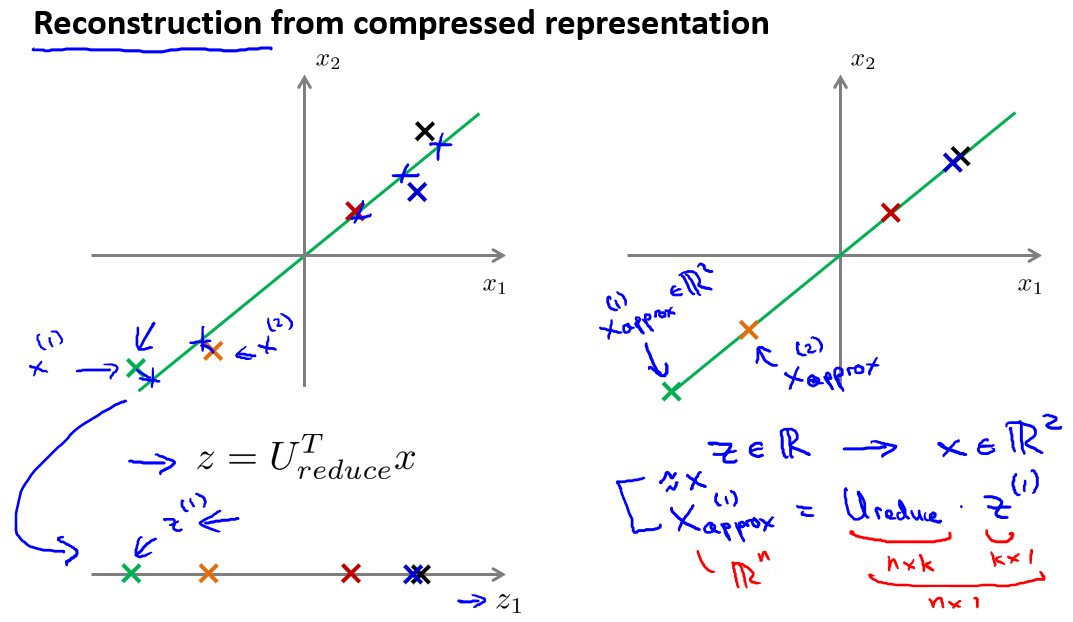
重建的压缩表示
在以前的视频中,我们谈论PCA作为压缩算法。在那里你可能需要把1000维的数据压缩100维特征,或具有三维数据压缩到一二维表示。所以,如果这是一个压缩算法,应该能回到这个压缩表示,回到你原有的高维数据的一种近似。
我们知道,相反的方程为:,。如图:
PCA的应用建议
- 当训练集特征维数较大时使用PCA将数据压缩至较少特征,然后对训练集运行学习算法。在预测时,采用之前学习而来的$U_{reduce}$将输入的特征$x$转换成特征向量$z$,然后再进行预测。

- 错误使用PCA的情况:将其用于减少过拟合(减少了特征的数量)。这样做非常不好,还不如尝试正则化处理。原因在于PCA只是近似地丢弃一些特征,其并不考虑任何与结果变量有关的信息,因此可能会丢失非常重要的特征。然而我们进行正则化处理时,会考虑到结果变量,不会丢掉重要的数据。

- 另一个常见的错误是,默认地将主成分分析作为学习过程中的一部分,这虽然很多时候有效果。但是最好还是从所有原始特征开始,只有在必要的时候(算法运行太慢或者占用太多内存)才考虑采用PCA。

异常检测
基于高斯分布
算法

我们选择一个$\varepsilon$,将$p(x) = \varepsilon$作为我们的判定边界,当$p(x) > \varepsilon$时预测数据为正常数据,否则为异常。
开发和评价一个异常检测系统
异常检测算法是一个非监督学习算法,意味着我们无法根据结果变量 $ y$ 的值来告诉我们数据是否真的是异常的。我们需要另一种方法来帮助检验算法是否有效。当我们开发一个异常检测系统时,我们从带标记(异常或正常)的数据着手,我们从其中选择一部分正常数据用于构建训练集,然后用剩下的正常数据和异常数据混合的数据构成交叉检验集和测试集。下图中60%,20%,20%是推荐的方法,而后者不推荐。

具体的评价方法如下:
- 根据测试集数据,我们估计特征的平均值和方差并构建$p(x)$函数
- 对交叉检验集,我们尝试使用不同的$\varepsilon$值作为阀值,并预测数据是否异常,根据$F1$值或者查准率与查全率的比例来选择 $\varepsilon$
- 选出 $\varepsilon$ 后,针对测试集进行预测,计算异常检验系统的$F1$值,或者查准率与查全率之比
异常检测与监督学习对比
| 异常检测 | 监督学习 | |
|---|---|---|
| 数据特征 | 非常少量的正向类(异常数据 $y=1$), 大量的负向类($y=0$) | 时有大量的正向类和负向类 |
| 异常特征提取的难易程度 | 有许多不同种类的异常,对于任何算法都比较难去从正样本中学习异常的状况。未来遇到的异常可能与已掌握的异常、非常的不同。 | 有足够多的正向类实例,足够用于训练算法,未来遇到的正向类实例可能与训练集中的非常近似。 |
| 例子 | 欺诈行为检测、生产(例如飞机引擎)、检测数据中心的计算机运行状况 | 邮件过滤器、天气预报、肿瘤分类 |
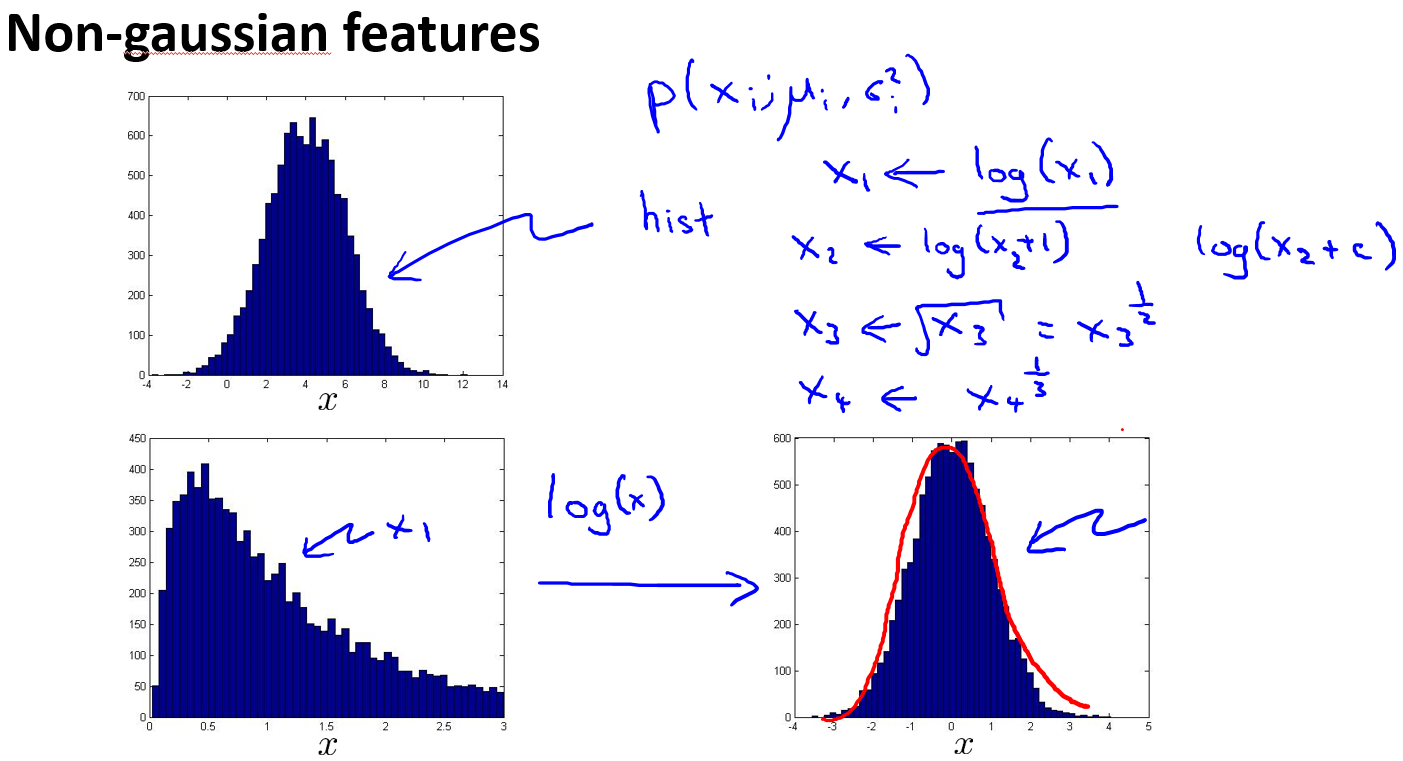
特征选择和处理
异常检测假设特征分布符合高斯分布,如果数据的分布不是高斯分布,异常检测算法也能够工作,但是最好还是将数据转化成高斯分布,例如使用对数函数:$x= log(x+c)$,其中 $c$ 为非负常数; 或者 $x=x^c$,$c$为 0-1 之间的一个分数,等方法。(在python中,通常用np.log1p()函数,$log1p$就是 $log(x+1)$,可以避免出现负数结果,反向函数就是np.expm1())
误差分析
一个常见的问题只分析异常的数据的单一特征可能也会有较高的$p(x)$值,因而被算法认为是正常的。这种情况下误差分析能够帮助我们,我们也许能从问题中发现我们需要增加一些新的特征,增加这些新特征后获得的新算法能够帮助我们更好地进行异常检测。
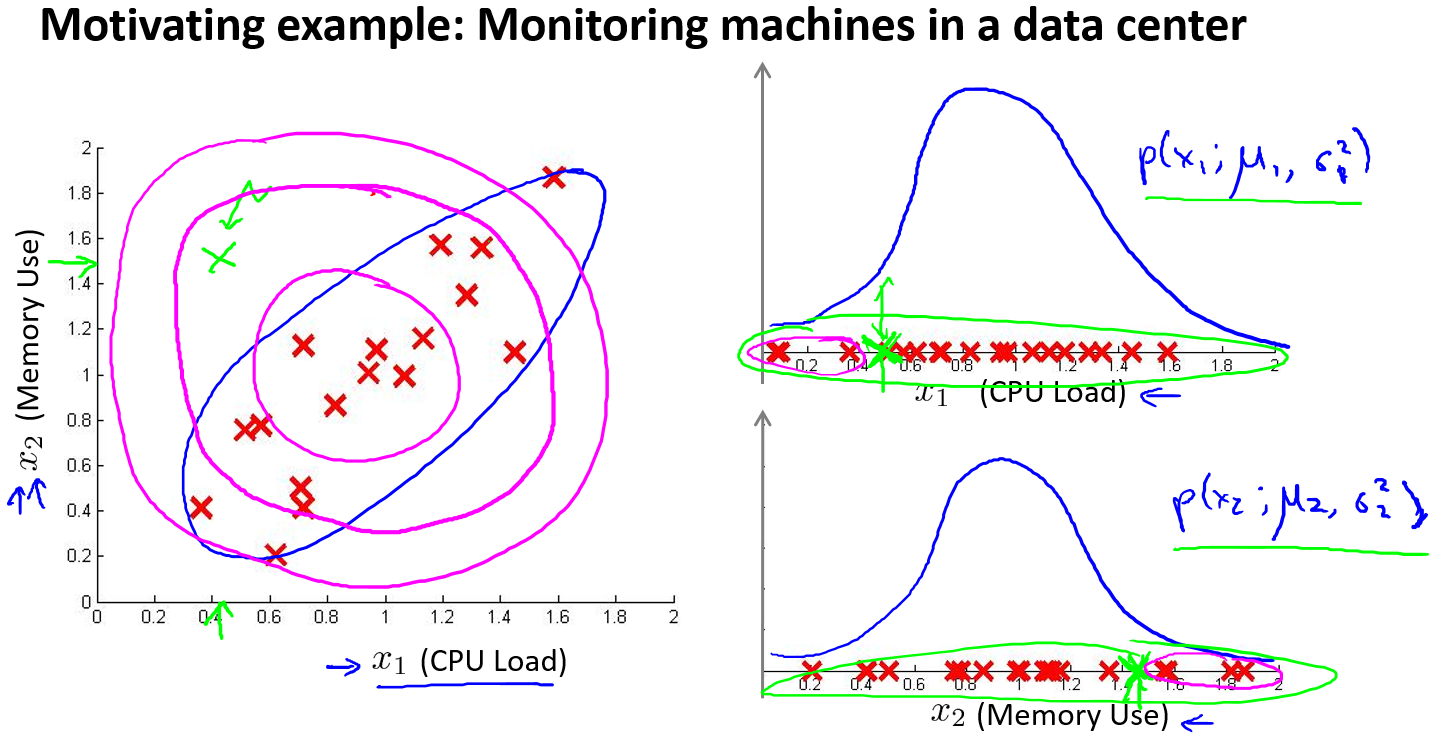
我们通常可以通过将一些相关的特征进行组合,来获得一些新的更好的特征(异常数据的该特征值异常地大或小),例如,在检测数据中心的计算机状况的例子中,我们可以用CPU负载与网络通信量的比例作为一个新的特征,如果该值异常地大,便有可能意味着该服务器是陷入了一些问题中。
基于多元高斯分布
算法
在一般的高斯分布模型中,计算 $p(x)$ 的方法是:通过分别计算每个特征对应的几率然后将其累乘起来,在多元高斯分布模型中,将构建特征的协方差矩阵,用所有的特征一起来计算 $p(x)$。
有一组样本$x^{(1)},x^{(2)},…,x^{(m)}$是一个$n$维向量,假设样本来自一个多元高斯分布。如何尝试估计参数 $\mu$ 和 $\Sigma$ 以及标准公式?如何把所有这一切共同开发一个异常检测算法?
首先计算所有特征的平均值,然后再计算协方差矩阵:
注:其中$\mu $ 是一个向量,其每一个单元都是原特征矩阵中一行数据的均值。最后我们计算多元高斯分布的$p\left( x \right)$:
其中:
- $|\Sigma|$是定矩阵,在 Octave 中用
det(sigma)计算 - $\Sigma^{-1}$ 是逆矩阵
最后见上述开发和评价一个异常检测系统内容开发一个异常检测算法

参数可视化
下面我们来看看协方差矩阵是如何影响模型的:
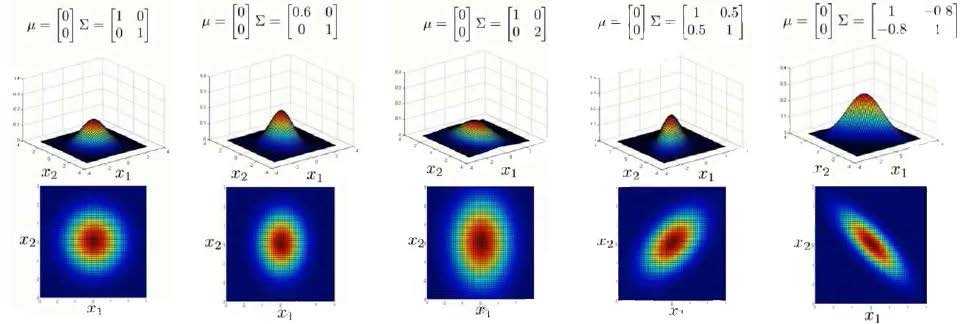
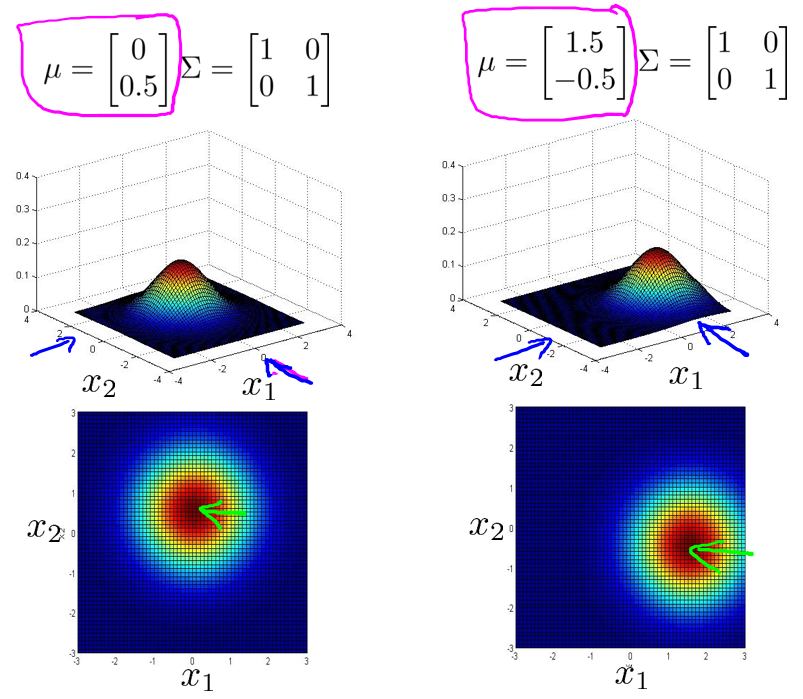
上图是6个不同的模型,从左往右依次分析:
- 是一个一般的高斯分布模型
- 通过协方差矩阵,令特征1拥有较小的偏差,同时保持特征2的偏差
- 通过协方差矩阵,令特征2拥有较大的偏差,同时保持特征1的偏差
- 通过协方差矩阵,在不改变两个特征的原有偏差的基础上,增加两者之间的正相关性
- 通过协方差矩阵,在不改变两个特征的原有偏差的基础上,增加两者之间的负相关性
- 通过$\mu$,在不改变两个特征的原有偏差的基础上,改变特征1和特征2的均值
模型对比
多元高斯分布模型与原高斯分布模型的关系:
可以证明的是,原本的高斯分布模型是多元高斯分布模型的一个子集,如果协方差矩阵只在对角线的单位上有非零的值时,即为原本的高斯分布模型了。
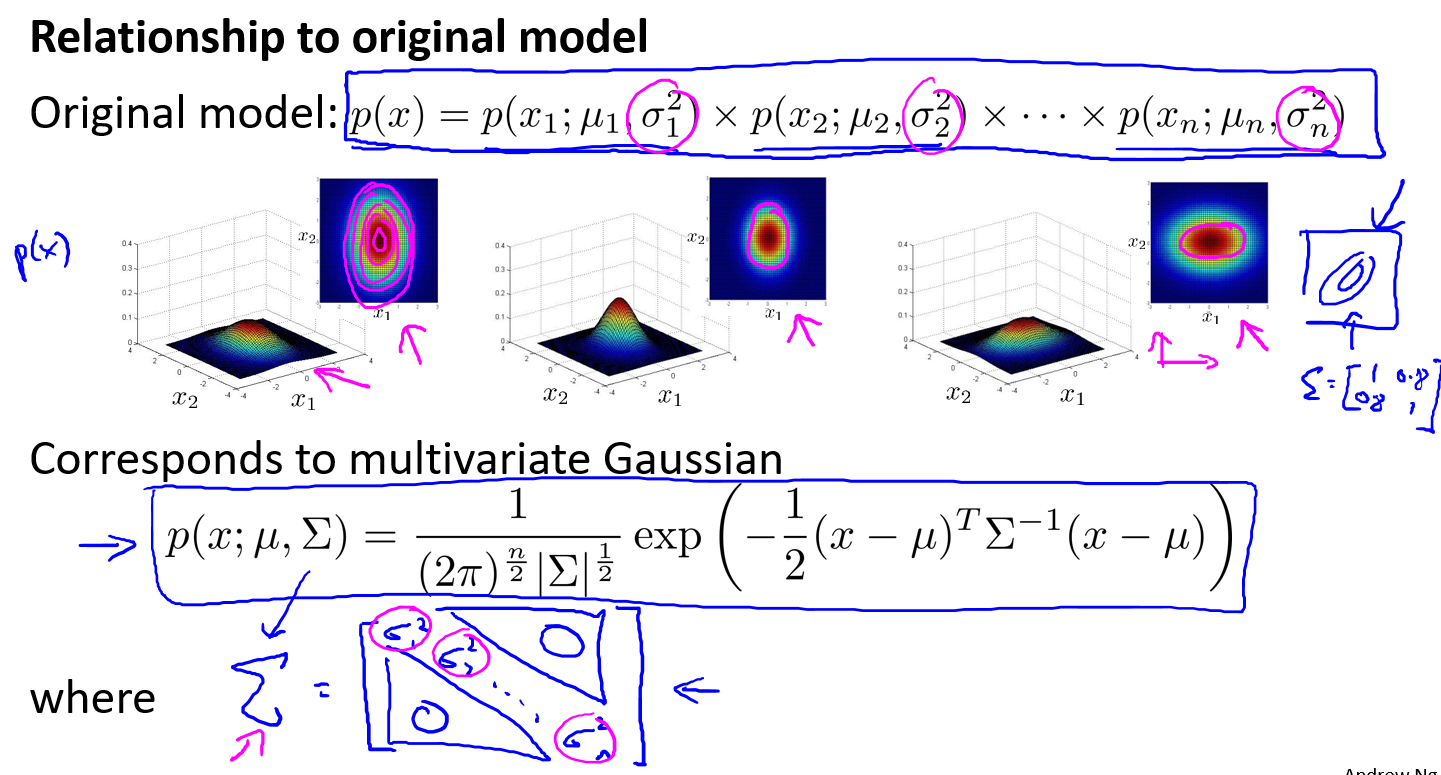
原高斯分布模型和多元高斯分布模型的比较:
| 原高斯分布模型 | 多元高斯分布模型 |
|---|---|
| 不能捕捉特征之间的相关性 但可以通过将特征进行组合的方法来解决 | 自动捕捉特征之间的相关性 |
| 计算代价低,能适应大规模的特征 | 计算代价较高,训练集较小时比较适用 |
| 即使训练样本$m$较小也能很好地运作 | 必须要有 $m>n$,不然的话协方差矩阵$\Sigma$不可逆的,通常需要 $m>10n$ 另外特征冗余也会导致协方差矩阵不可逆 |
原高斯分布模型被广泛使用着,如果特征之间在某种程度上存在相互关联的情况,我们可以通过构造新新特征的方法来捕捉这些相关性。
如果训练集不是太大,并且没有太多的特征,我们可以使用多元高斯分布模型。

推荐系统
基于内容的推荐算法
在一个基于内容的推荐系统算法中,我们假设对于我们希望推荐的东西有一些数据,这些数据是有关这些东西的特征。在我们的例子中,我们可以假设每部电影都有两个特征,如代表电影的浪漫程度,代表电影的动作程度。
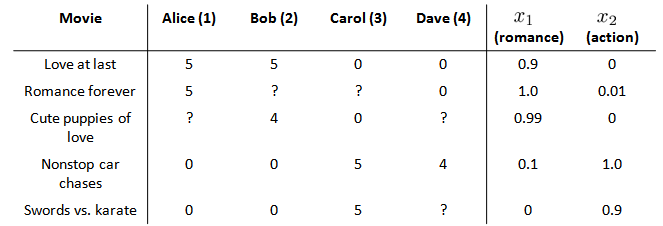
则每部电影都有一个特征向量,如是第一部电影的特征向量为[0.9 0]。
下面我们要基于这些特征来构建一个推荐系统算法。
假设我们采用线性回归模型,我们可以针对每一个用户都训练一个线性回归模型,如是第一个用户的模型的参数。
于是,我们有:
代价函数
针对用户 $j$,该线性回归模型的代价为预测误差的平方和,加上正则化项:
其中 $i:r(i,j)$表示我们只计算那些用户 $j$ 评过分的电影。在一般的线性回归模型中,误差项和正则项应该都是乘以$\frac{1}{2m}$,在这里我们将$m$去掉。并且我们不对方差项$\theta_0$进行正则化处理。
上面的代价函数只是针对一个用户的,为了学习所有用户,我们将所有用户的代价函数求和:
如果我们要用梯度下降法来求解最优解,我们计算代价函数的偏导数后得到梯度下降的更新公式为:
协同过滤
在之前的基于内容的推荐系统中,对于每一部电影,我们都掌握了可用的特征,使用这些特征训练出了每一个用户的参数。相反地,如果我们拥有用户的参数,我们可以学习得出电影的特征。
但是如果我们既没有用户的参数,也没有电影的特征,这两种方法都不可行了。协同过滤算法可以同时学习这两者。我们的优化目标便改为同时针对$x$和$\theta$进行。
对代价函数求偏导数的结果如下:
注:在协同过滤从算法中,我们通常不使用方差项,如果需要的话,算法会自动学得。
协同过滤算法使用步骤如下:
- 初始 为一些随机小值
- 使用梯度下降算法最小化代价函数
- 在训练完算法后,我们预测为用户 $j$ 给电影 $i$ 的评分
通过这个学习过程获得的特征矩阵包含了有关电影的重要数据,这些数据不总是人能读懂的,但是我们可以用这些数据作为给用户推荐电影的依据。
例如,如果一位用户正在观看电影 $x^{(i)}$,我们可以寻找另一部电影$x^{(j)}$,依据两部电影的特征向量之间的距离的大小。
协同过滤算法
优化目标
给定$x^{(1)},…,x^{(n_m)}$,估计$\theta^{(1)},…,\theta^{(n_u)}$:
给定$\theta^{(1)},…,\theta^{(n_u)}$,估计$x^{(1)},…,x^{(n_m)}$:
同时最小化$x^{(1)},…,x^{(n_m)}$和$\theta^{(1)},…,\theta^{(n_u)}$:
算法步骤
向量化:低秩矩阵分解
在上几节视频中,我们谈到了协同过滤算法,本节视频中我将会讲到有关该算法的向量化实现,以及说说有关该算法你可以做的其他事情。
举例子:
- 当给出一件产品时,你能否找到与之相关的其它产品。
- 一位用户最近看上一件产品,有没有其它相关的产品,你可以推荐给他。
我将要做的是:实现一种选择的方法,写出协同过滤算法的预测情况。
我们有关于五部电影的数据集,我将要做的是,将这些用户的电影评分,进行分组并存到一个矩阵中。
我们有五部电影,以及四位用户,那么 这个矩阵 $Y$ 就是一个5行4列的矩阵,它将这些电影的用户评分数据都存在矩阵里:
| Movie | Alice (1) | Bob (2) | Carol (3) | Dave (4) |
|---|---|---|---|---|
| Love at last | 5 | 5 | 0 | 0 |
| Romance forever | 5 | ? | ? | 0 |
| Cute puppies of love | ? | 4 | 0 | ? |
| Nonstop car chases | 0 | 0 | 5 | 4 |
| Swords vs. karate | 0 | 0 | 5 | ? |
推出评分:

通过最小距离找到相关影片:

推行工作上的细节:均值归一化
让我们来看下面的用户评分数据:
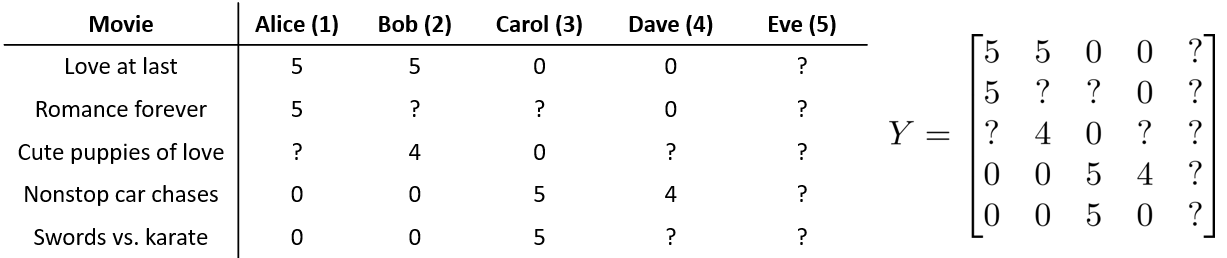
如果我们新增一个用户 Eve,并且 Eve 没有为任何电影评分,那么我们以什么为依据为Eve推荐电影呢?
我们首先需要对结果 $Y $矩阵进行均值归一化处理,将每一个用户对某一部电影的评分减去所有用户对该电影评分的平均值:
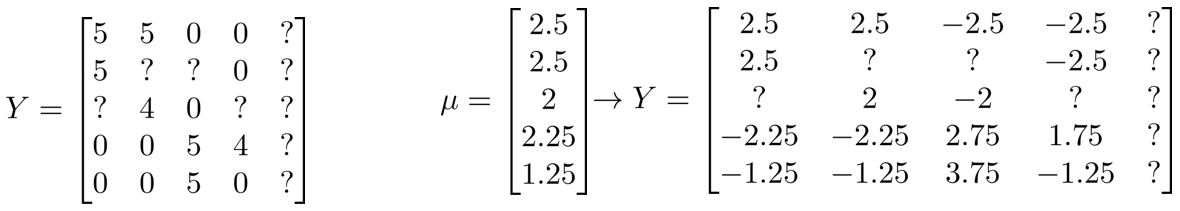
然后我们利用这个新的 $Y$ 矩阵来训练算法。
如果我们要用新训练出的算法来预测评分,则需要将平均值重新加回去,预测,对于Eve,我们的新模型会认为她给每部电影的评分都是该电影的平均分。
大规模机器学习
大型数据集的学习
如果我们有一个低方差的模型,增加数据集的规模可以帮助你获得更好的结果。我们应该怎样应对一个有100万条记录的训练集?
以线性回归模型为例,每一次梯度下降迭代,我们都需要计算训练集的误差的平方和,如果我们的学习算法需要有20次迭代,这便已经是非常大的计算代价。
首先应该做的事是去检查一个这么大规模的训练集是否真的必要,也许我们只用1000个训练集也能获得较好的效果,我们可以绘制学习曲线来帮助判断。
随机梯度下降法(Stochastic Gradient Descent)
如果我们一定需要一个大规模的训练集,我们可以尝试使用随机梯度下降法来代替批量梯度下降法。
在随机梯度下降法中,我们定义代价函数为一个单一训练实例的代价:
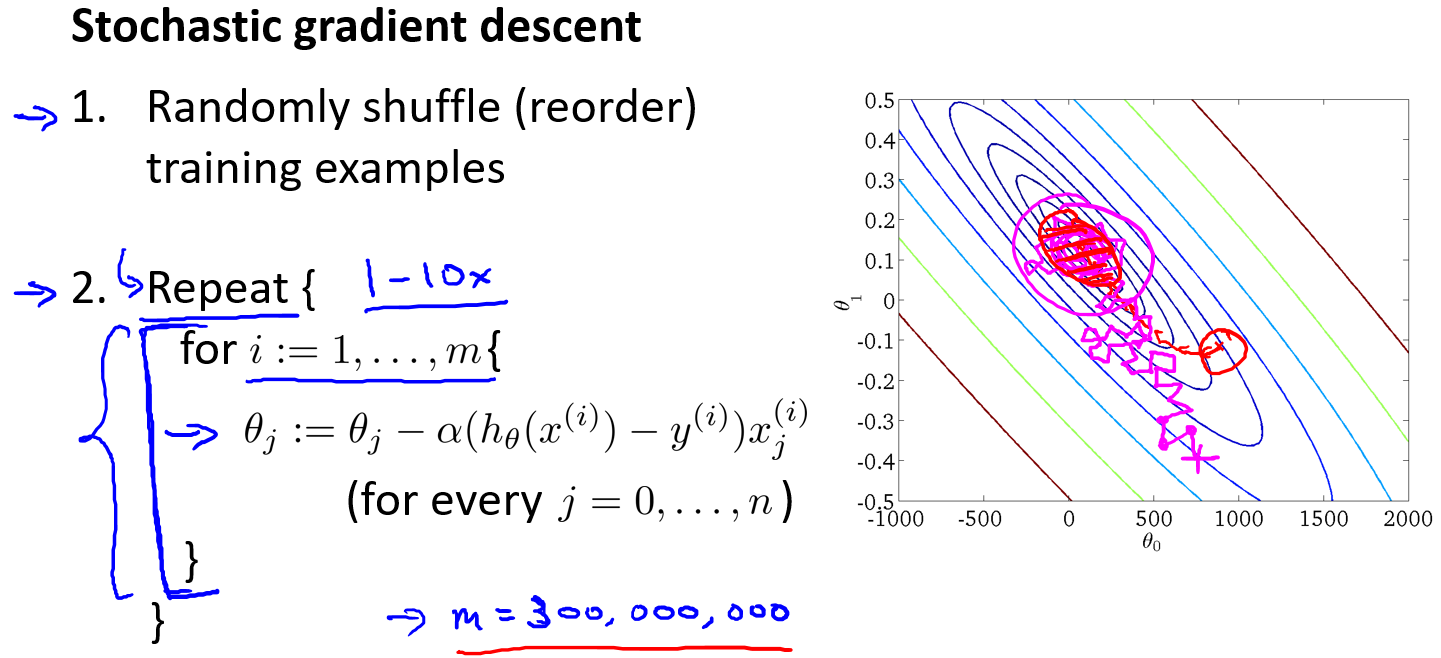
随机梯度下降算法在每一次计算之后便更新参数 $$ ,而不需要首先将所有的训练集求和,在梯度下降算法还没有完成一次迭代时,随机梯度下降算法便已经走出了很远。但是这样的算法存在的问题是,不是每一步都是朝着”正确”的方向迈出的。因此算法虽然会逐渐走向全局最小值的位置,但是可能无法站到那个最小值的那一点,而是在最小值点附近徘徊。
小批量梯度下降(Mini-Batch Gradient Descent)
小批量梯度下降算法是介于批量梯度下降算法和随机梯度下降算法之间的算法,每计算常数$b$次训练实例,便更新一次参数 $$ 。

通常我们会令 $b$ 在 2-100 之间。这样做的好处在于,我们可以用向量化的方式来循环 $b$个训练实例,如果我们用的线性代数函数库比较好,能够支持平行处理,那么算法的总体表现将不受影响(与随机梯度下降相同)。
随机梯度下降收敛
SGD调试
在批量梯度下降中,我们可以令代价函数$J$为迭代次数的函数,绘制图表,根据图表来判断梯度下降是否收敛。但是,在大规模的训练集的情况下,这是不现实的,因为计算代价太大了。
在随机梯度下降中,我们在每一次更新 $$ 之前都计算一次代价,然后每$x$次迭代后,求出这$x$次对训练实例计算代价的平均值,然后绘制这些平均值与$x$次迭代的次数之间的函数图表。
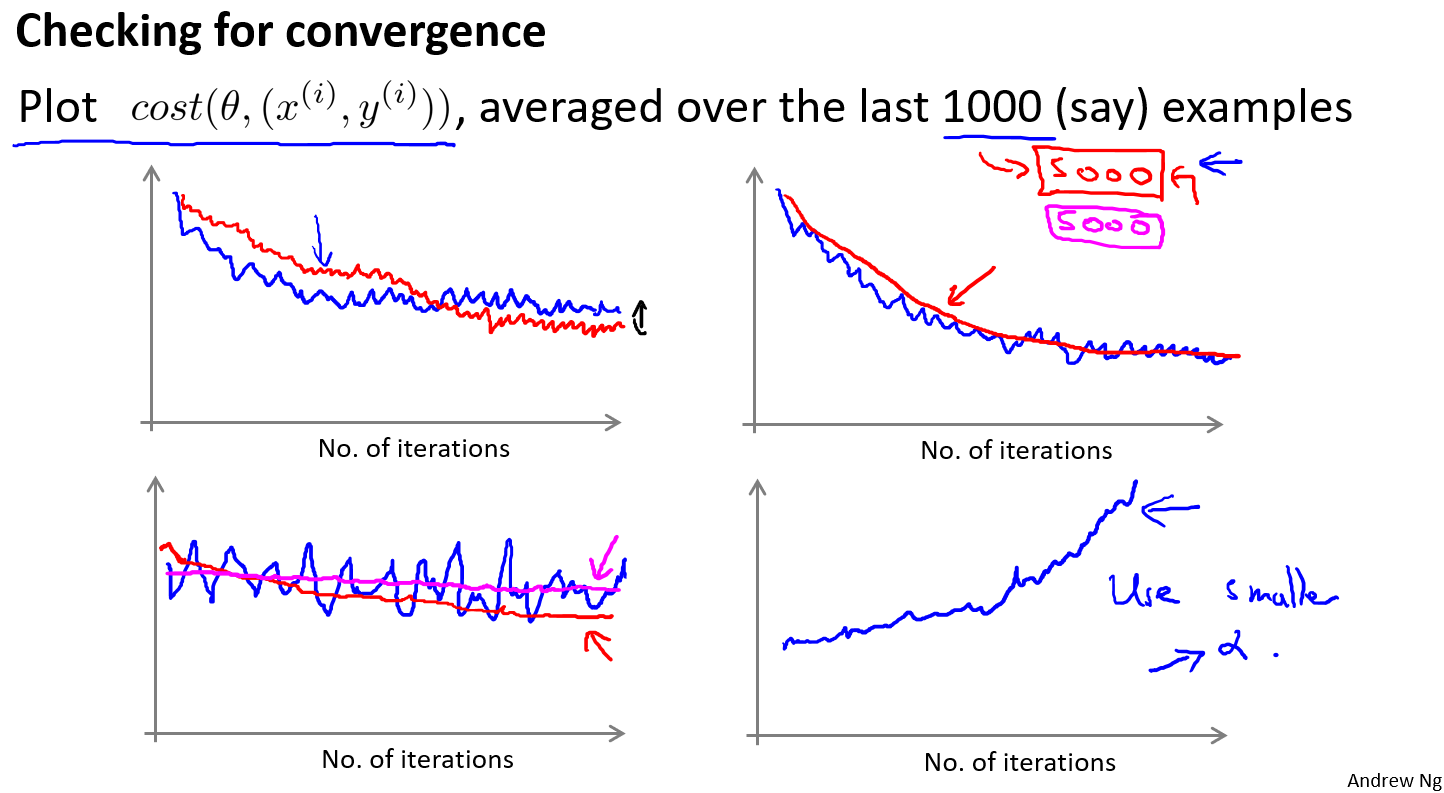
当我们绘制这样的图表时,可能会得到一个颠簸不平但是不会明显减少的函数图像(如左下图中蓝线所示)。我们可以增加$α$来使得函数更加平缓,也许便能看出下降的趋势了(如左下图中红线所示);或者可能函数图表仍然是颠簸不平且不下降的(如洋红色线所示),那么我们的模型本身可能存在一些错误。
学习率调整
如果我们得到的曲线如上面右下方所示,不断地上升,那么我们可能会需要选择一个较小的学习率$α$。
我们也可以令学习率随着迭代次数的增加而减小,例如令:
随着我们不断地靠近全局最小值,通过减小学习率,我们迫使算法收敛而非在最小值附近徘徊。
但是通常我们不需要这样做便能有非常好的效果了,对$α$进行调整所耗费的计算通常不值得
总结下,这段视频中,我们介绍了一种方法,近似地监测出随机梯度下降算法在最优化代价函数中的表现,这种方法不需要定时地扫描整个训练集,来算出整个样本集的代价函数,而是只需要每次对最后1000个,或者多少个样本,求一下平均值。应用这种方法,你既可以保证随机梯度下降法正在正常运转和收敛,也可以用它来调整学习速率$α$的大小。
在线学习
在线学习的算法与随机梯度下降算法有些类似,我们对单一的实例进行学习,而非对一个提前定义的训练集进行循环。
一旦对一个数据的学习完成了,我们便可以丢弃该数据,不需要再存储它了。这种方式的好处在于,我们的算法可以很好的适应用户的倾向性,算法可以针对用户的当前行为不断地更新模型以适应该用户。在线学习的一个优点就是,如果你有一个变化的用户群,又或者你在尝试预测的事情,在缓慢变化,就像你的用户的品味在缓慢变化,这个在线学习算法,可以慢慢地调试你所学习到的假设,将其调节更新到最新的用户行为。
减少映射与数据并行
映射化简和数据并行对于大规模机器学习问题而言是非常重要的概念。之前提到,如果我们用批量梯度下降算法来求解大规模数据集的最优解,我们需要对整个训练集进行循环,计算偏导数和代价,再求和,计算代价非常大。如果我们能够将我们的数据集分配给不多台计算机,让每一台计算机处理数据集的一个子集,然后我们将计所的结果汇总在求和。这样的方法叫做映射简化。
具体而言,如果任何学习算法能够表达为,对训练集的函数的求和,那么便能将这个任务分配给多台计算机(或者同一台计算机的不同CPU 核心),以达到加速处理的目的。
例如,我们有400个训练实例,我们可以将批量梯度下降的求和任务分配给4台计算机进行处理:

很多高级的线性代数函数库已经能够利用多核CPU的多个核心来并行地处理矩阵运算,这也是算法的向量化实现如此重要的缘故(比调用循环快)。
应用实例:图片文字识别
OCR pipeline
图像文字识别应用所作的事是,从一张给定的图片中识别文字。
为了完成这样的工作,需要采取如下步骤:
- 文字侦测(Text detection)——将图片上的文字与其他环境对象分离开来
- 字符切分(Character segmentation)——将文字分割成一个个单一的字符
- 字符分类(Character classification)——确定每一个字符是什么
可以用流水线来表示这个问题,每一项任务可以由一个单独的部门来负责解决:

滑动窗口
滑动窗口是一项用来从图像中抽取对象的技术。假使我们需要在一张图片中识别行人,首先要做的是用许多固定尺寸的图片来训练一个能够准确识别行人的模型。然后我们用之前训练识别行人的模型时所采用的图片尺寸在我们要进行行人识别的图片上进行剪裁,然后将剪裁得到的切片交给模型,让模型判断是否为行人,然后在图片上滑动剪裁区域重新进行剪裁,将新剪裁的切片也交给模型进行判断,如此循环直至将图片全部检测完。
一旦完成后,我们按比例放大剪裁的区域,再以新的尺寸对图片进行剪裁,将新剪裁的切片按比例缩小至模型所采纳的尺寸,交给模型进行判断,如此循环。

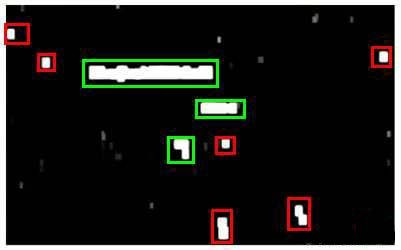
滑动窗口技术也被用于文字识别,首先训练模型能够区分字符与非字符,然后,运用滑动窗口技术识别字符,一旦完成了字符的识别,我们将识别得出的区域进行一些扩展,然后将重叠的区域进行合并。接着我们以宽高比作为过滤条件,过滤掉高度比宽度更大的区域(认为单词的长度通常比高度要大)。下图中绿色的区域是经过这些步骤后被认为是文字的区域,而红色的区域是被忽略的。
以上便是文字侦测阶段。下一步是训练一个模型来完成将文字分割成一个个字符的任务,需要的训练集由单个字符的图片和两个相连字符之间的图片来训练模型。
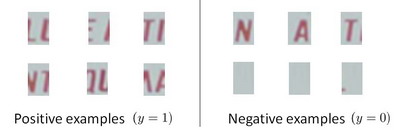

模型训练完后,我们仍然是使用滑动窗口技术来进行字符识别。
以上便是字符切分阶段。最后一个阶段是字符分类阶段,利用神经网络、支持向量机或者逻辑回归算法训练一个分类器即可。
获取大量数据和人工数据
如果我们的模型是低方差的,那么获得更多的数据用于训练模型,是能够有更好的效果的。问题在于,我们怎样获得数据,数据不总是可以直接获得的,我们有可能需要人工地创造一些数据。
以我们的文字识别应用为例,我们可以字体网站下载各种字体,然后利用这些不同的字体配上各种不同的随机背景图片创造出一些用于训练的实例,这让我们能够获得一个无限大的训练集。这是从零开始创造实例。
另一种方法是,利用已有的数据,然后对其进行修改,例如将已有的字符图片进行一些扭曲、旋转、模糊处理。只要我们认为实际数据有可能和经过这样处理后的数据类似,我们便可以用这样的方法来创造大量的数据。
有关获得更多数据的几种方法:
- 人工数据合成
- 手动收集、标记数据
- 众包
天花板分析:下一步的pipeline
在机器学习的应用中,我们通常需要通过几个步骤才能进行最终的预测,我们如何能够知道哪一部分最值得我们花时间和精力去改善呢?这个问题可以通过上限分析来回答。
回到我们的文字识别应用中,我们的流程图如下:
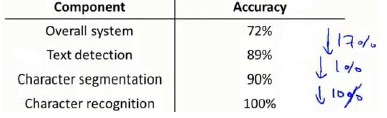
流程图中每一部分的输出都是下一部分的输入,上限分析中,我们选取一部分,手工提供100%正确的输出结果,然后看应用的整体效果提升了多少。假使我们的例子中总体效果为72%的正确率。
如果我们令文字侦测部分输出的结果100%正确,发现系统的总体效果从72%提高到了89%。这意味着我们很可能会希望投入时间精力来提高我们的文字侦测部分。
接着我们手动选择数据,让字符切分输出的结果100%正确,发现系统的总体效果只提升了1%,这意味着,我们的字符切分部分可能已经足够好了。
最后我们手工选择数据,让字符分类输出的结果100%正确,系统的总体效果又提升了10%,这意味着我们可能也会应该投入更多的时间和精力来提高应用的总体表现。
总结
又又又看了一次机器学习的视频,最大的收获应该是对神经网络的本质有了更深的认识,另外感觉吴恩达对知识点的讲述方式和以往自己听到方式有很多不一样,仿佛打开了新世界…另外后面几章似乎有点水啊,感觉只是点到为止,没有涉及很深的内容,也可能是因为之前接触过才这么觉得吧…除了看视频做笔记之外,我还用python3基本复现了课程作业,指导书上用的是octave,一种很像matlab的语言,不过似乎有点老了,所以还是选择用比较流行的语言来写吧。容易实现的算法自己就从头开始写,当然没有做太多优化,然后自己写完了也要学会调用库来完成,因为库的实现有更多的优化速度更快以及更高的容错能力,如果是真实的项目一般会调用库函数来完成;当然也有很多比较难以实现的算法部分,比如复杂优化算法,那就只能先调包了。刚开始写的时候真的是很痛苦很难受,虽然之前有看一本叫《machine learning in action》的书,以及看了@liuyubobobo在慕课上的视频《Python3入门机器学习经典算法与应用》复现算法,但是很多代码还是不怎么会写,有种编码无力的感觉,所以也参考了很多别人的代码。复现代码地址在我的github 上。
实现难点
- 逻辑斯蒂回归需要用到scipy的牛顿截断法进行参数优化
- 神经网络本质上也是参数优化问题,若想调用参数优化包,实现的时候需要将所有参数整合到一个变量才能作为参数传递进入参数优化的函数中
- 调用opt.minimize的时候theta的传递会转化成为行向量,注意前面的算法设计
- 非线性决策边界的绘制用plt.coutour绘制等高线