Adaboost、GBDT、xgboost的个人理解
前向分布算法
Adaboost
基本步骤
Adaboost 算法的基本原理就是将多个弱分类器进行结合,最终成为一个强分类器。与 bagging 不同的是,这个弱分类器的训练不是并行化的,而是采用一种迭代的方式。其基本步骤就是:
- 每次训练只训练一个弱分类器,训练好的弱分类器将参与到下一次迭代,也就是说第 N 次迭代中会有 N-1 个分类器是之前就训练好的,在其他参数不变的情况下训练第 N 个分类器。
- 该第 N 个分类器训练的时候,要找到一组新的训练数据,让前面 N-1 个分类器在其上的表现很差,然后让第 N 个分类器这组数据上训练。怎么找到这组新的训练数据,其实就是权重的调整,其思想就是第 N 个分类器将着重关注前面 N-1 个分类器中分错的样本,即通过重采样的方法给予这些数据更高的权重,也相当于改变样本的概率分布,这将使得前 N-1 个分类器在该样本上表现不佳,而只要第 N 个分类器在该样本上正确分类即能获得很高的性能。
- 最终,在此基础上,对所有 N 个弱分类器采用加权投票的方法来对测试样本进行预测,这 N 个弱分类器的权重将由其分类正确率来决定,正确率越高的弱分类器在强分类器中拥有更大的权重。
具体流程
自己总结的计算具体流程:
假设有$N$个训练样本,第 1 次迭代每个样本的权重初始化为:
第 k 次迭代中的分类器 $C$ 的样本加权错误率为(分母为权重归一化):
对于错误分类的样本,其第 k+1 次迭代的权重将被调整为:
对于正确分类的样本,其第 k+1 次迭代的权重将被调整为:
其中,由于错误率(二分类问题)是一个小于 0.5 的数,所以是一个大于 1 的数,权重调整目的是使错误样本的权重更高,在下一轮迭代中有更高的概率被选中,降低正确样本的选中概率。
为了统一描述权重的更新往往用来替代,这样权重的更新可以描述为:
同时权重更新完之后需要对权重进行归一化使得(其实就是上面第二步分母做的事情,主要是保证加权误差率的正确)。
另外,新训练好的弱分类器将加入到集成模型中:
最后,强分类器将表达为 次迭代的 个弱分类器的权重和:
运算案例
下面是一个李宏毅老师深度学习的例子以帮助理解:
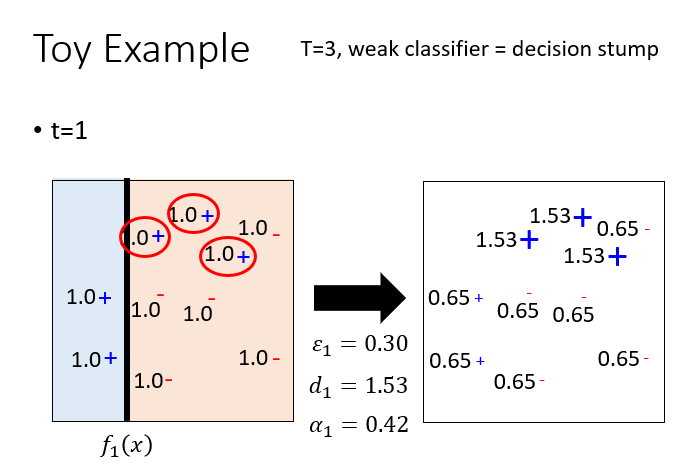
初始一共有10个样本,并且每个样本的权重是一致的,假如有这么一个弱分类器,其产生的决策边界如图黑线所示,其中蓝色区域为其分类的正样本,红色区域为其分类的负样本,那么一共有三个被红色圈中的样本分类错误,所以第一次迭代的错误率,那么,那么分类正确的样本权重将调整为,分类错误的样本权重将调整为,第 1 个弱分类器的权重,这个例子讲的时候没有乘。
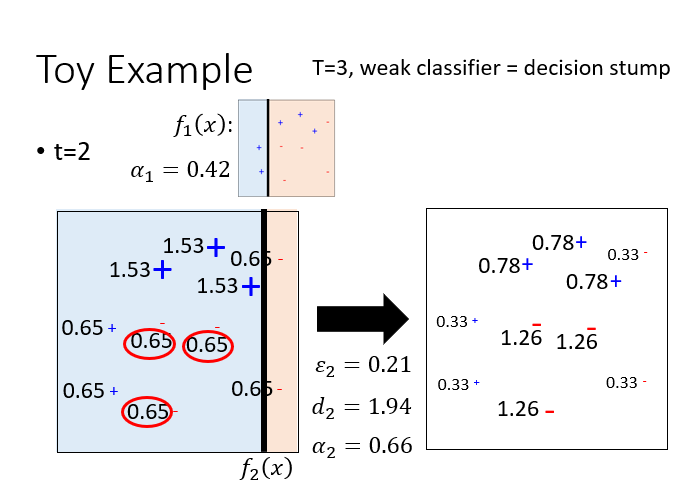
这是第 2 次迭代。
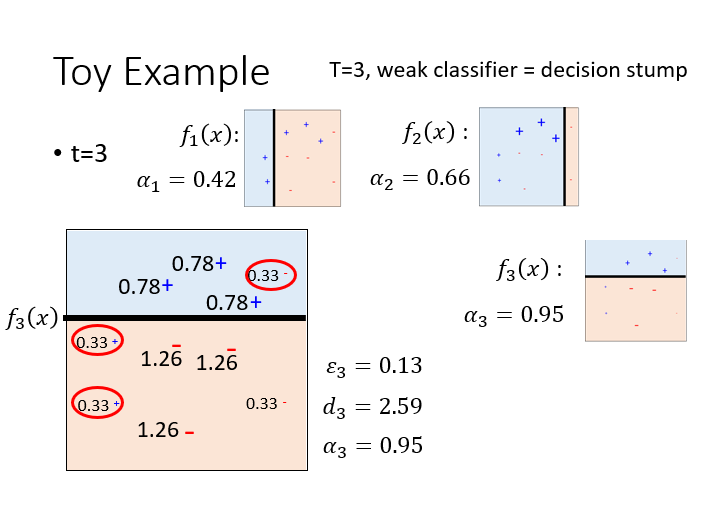
这是第 3 次迭代。
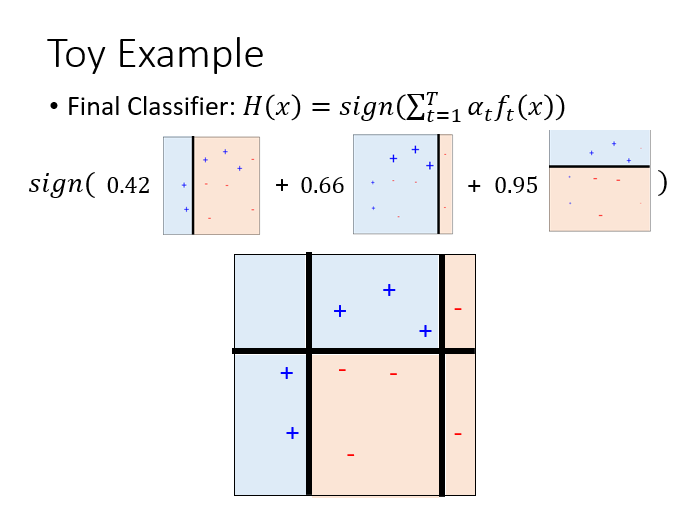
最终所有弱分类器的加权组合将会得到一个强分类器,这个强分类器将会正确分类这个实例的所有样本。
看了很多例子,这个例子对我来说最形象生动,但是注意这个例子的权重调整没有进行归一化。
公式推导
证明:为什么?
假如有一个训练集,在第 m-1 次迭代后已经有一个多种弱分类器组合而成的线性分类器:
在第 m 次迭代将要训练第 m 个弱分类器,它的权重是,使之成为一个更强的分类器:
所以仍然需要确定弱分类器及其权重,因此定义强分类器总指数误差为:
注:指数误差通常用在boosting中,指数误差始终大于 0,但是确保越接近正确的结果误差越小,反之越大。
令 以及 ,可以将上式简化为
我们可以将上式写成下面这种形式(即将错误分类和正确分类的误差进行求和):
这意味着总误差是所有正确分类和错误分类的加权误差和。
由于是一个常数,为了找到一个新的弱分类器权重能够最小化误差$E$,则对$E$进行求导:
令上述公式为 0 可以求得
其中。
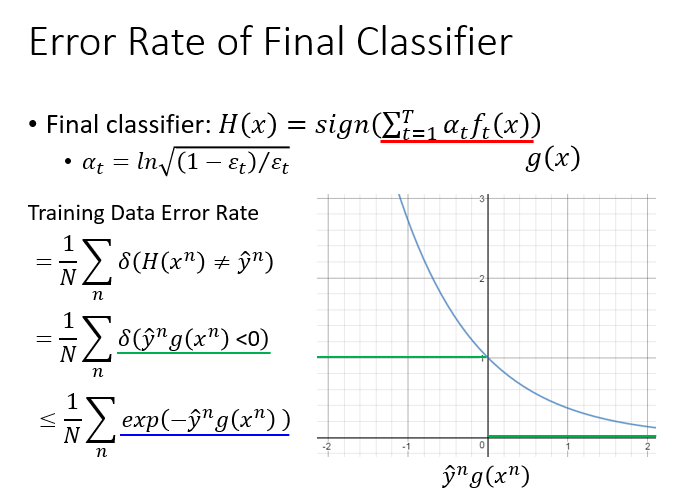
证明:Adaboost随着迭代次数增加,误差率会越来越小。
结合上图,误差函数将被定义为
从图中可直观的感受到其小于等于一个上界函数。这个式子实际上等于第 T 次迭代的样本权重和。证明如下:
根据
则
下面要证明该上界函数将越来越小:
根据
如果使用递推的方式则有
结合上述证明,结论是:
由于,所以训练数据的错误率会随着迭代次数的增加而越来越小。
令 ,则 ,有
证明如下(自文哥的学习日记):
要证:
即证:
令 ,因为,所以 ,所以 ,令:
则:
所以 递增,又因为 ,所以 在 上成立,故原式得证。
推论:如果存在 ,对所有 $m$ 有,则
参考
paper: AdaBoost and the Super Bowl of Classifiers A Tutorial Introduction to Adaptive Boosting
李宏毅深度学习:https://datawhalechina.github.io/leeml-notes/#/chapter38/chapter38?id=adaboost
wikipedia.org: https://en.wikipedia.org/wiki/AdaBoost
李航:统计学习方法第二版
网站:https://www.jianshu.com/u/c5df9e229a67
实现:参考@ljpzzz
GBDT
使用前向分布算法构建提升树:
需要求解最小化损失函数的参数$\Theta$:
当采用平方误差损失函数时:
这里 $r$ 是当前模型拟合数据的误差
算例:



参考
李航:统计学习方法第二版