时间原因没有认真读论文和看代码,看了一下下Up主-霹雳吧啦Wz的讲述,记录一下自己认为的yolo多次迭代版本的核心设计,以达到临阵磨枪,不快也光的目的。
论文:
- 【Yolov1】You Only Look Once: Unified, Real-Time Object Detection (2016 CVPR)
- 【Yolov2】YOLO9000: Better, Faster, Stronger (2017 CVPR)
- 【Yolov3】YOLOv3: An Incremental Improvement
- 【Yolov4】Optimal Speed and Accuracy of Object Detection
- 【Yolov5】Github
- 【YolovX】YOLOX: Exceeding YOLO Series in 2021
总结下来我认为该系列的核心设计有几个方面:
- 数据增强方式
- 多尺度特征提取网络结构的设计、多尺度检测头
- 多尺度anchor(部分版本)
- 定位损失函数的设计
个人总结
个人总结Yolo系列比较work的地方,包括
- 数据增强:Mosaic,Copy-Paste、Random affine、Mixup、Albumentations、Augment HSV(Hue, Saturation, value)
- 网络结构:特征提取层(残差)、多尺度特征提取(SPP,SPPF)、多尺度检测头(通过聚类得到的anchor template)
- 损失函数:IoU、GIoU、DIoU、CIoU,Focus Loss.
- 定位纠正:Eliminate grid sensititive-使纠正区间在合理范围,IoU threhold-提高正样本数
- 训练策略:multi-scale training,
Yolov1
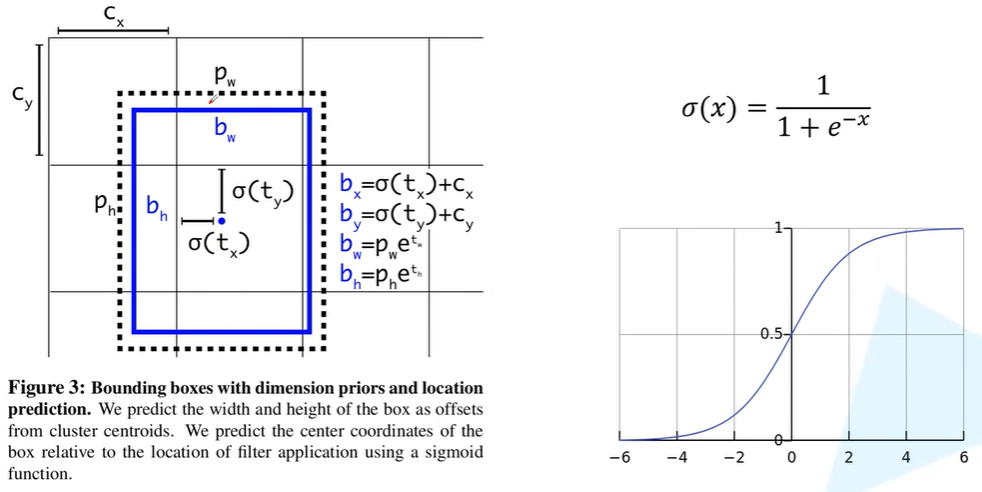
Yolov1系列的核心想法是将图像分成 网格(实操中通过32倍下采样成 的像素点的特征图),在计算损失阶段,每个网格只计算中心点落在该网格的物体的定位和分类误差。
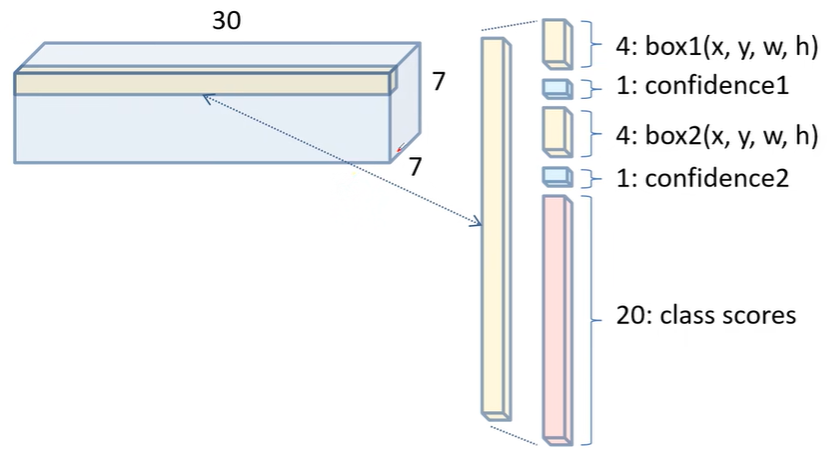
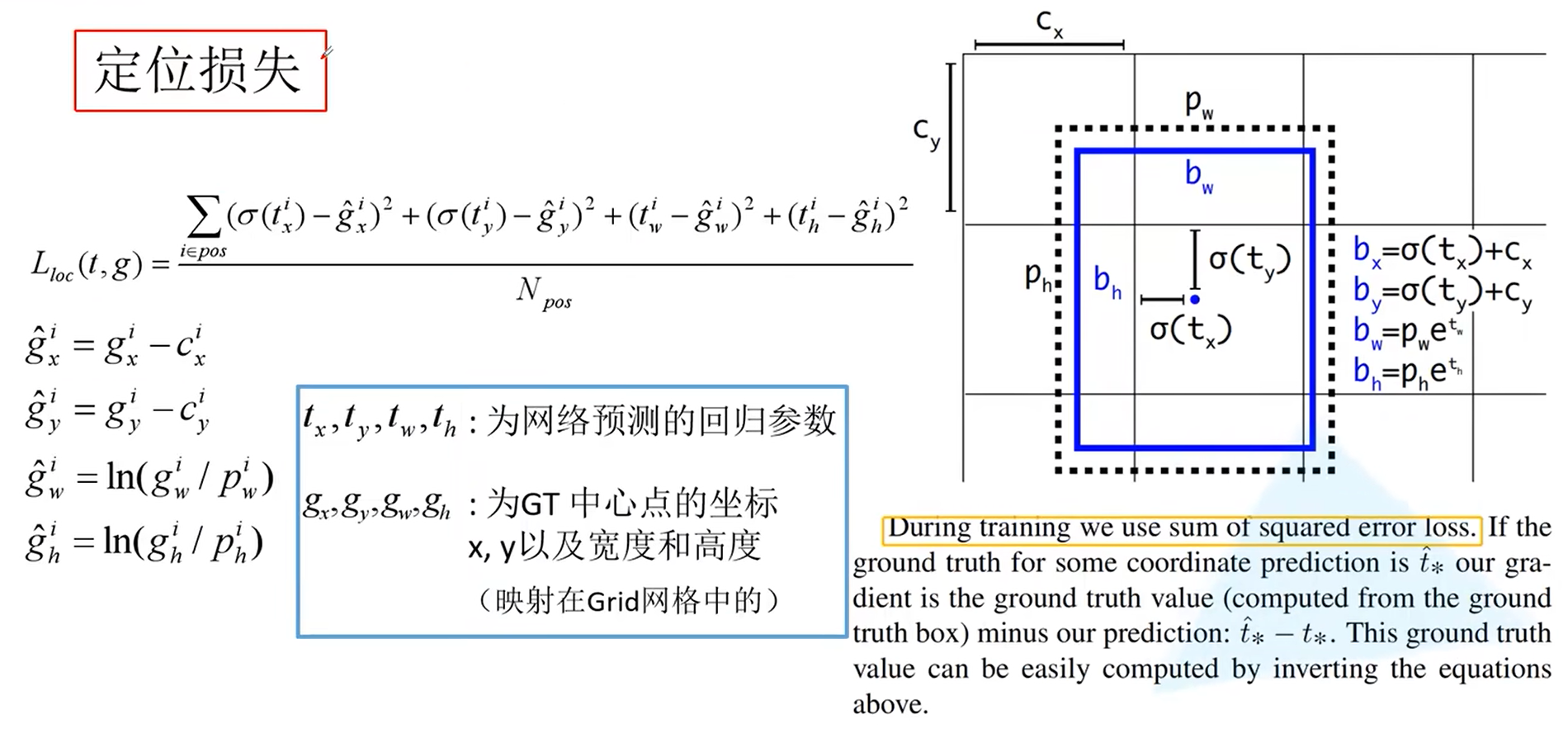
往往每个网格都要需要负责预测$B$个定位框,而对于每个框要预测5个参数,分别是bounding box的的位置(4个参数),用对角线的两个点 来表示或者用一个点加框的宽高来表示,还有1个参数是判断bounding box是否含物体的置信度(往往理解为预测的框和ground truth的IOU)。
除此之外每个网格还要负责预测这个网格中 个类别的概率,代表该网格中物体的分类结果,当然这样的设计也是Yolov1存在的缺陷,即每个网格中只能预测最多1个物体,同时每个网格预测的定位框是anchor-free的。
在Yolov1的实验中,$B$ 取 2,$C$ 取 20,如下图所示:
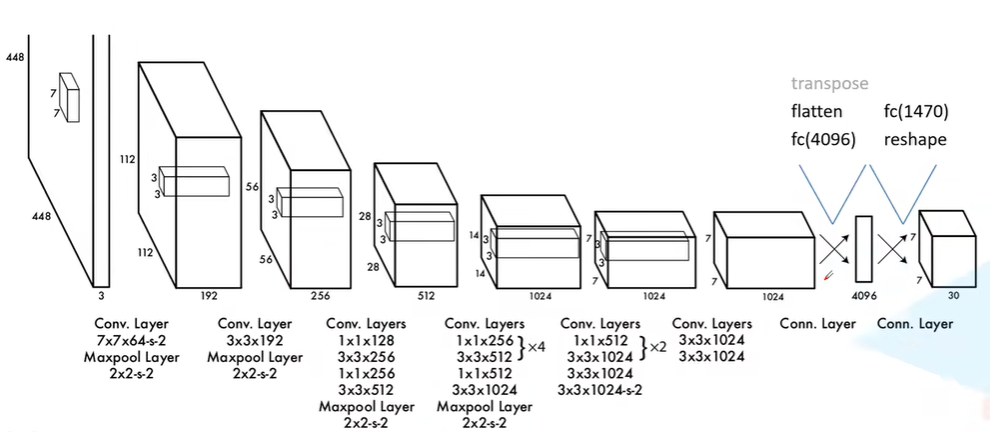
Yolov1的backbone是全卷积网络加全连接检测头,没有考虑梯度消失和尺度的问题。
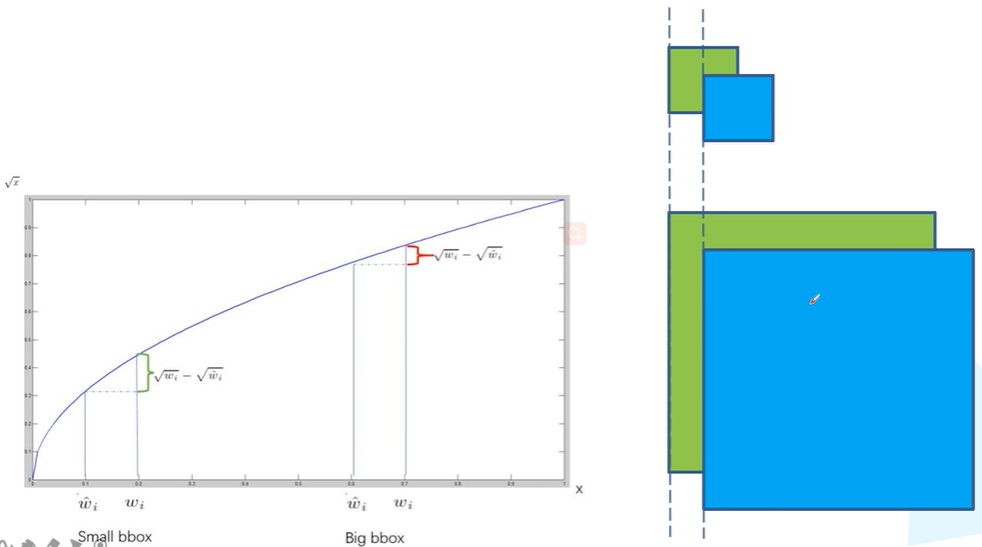
从损失函数的设计上,是定位损失、置信度损失和分类损失的加权和,用的均是误差平方和,其中定位损失的w和h使用了开发的误差平方和是为了降低定位损失对大尺寸物体的敏感度(权重),即在相同的偏置x,y的定位误差上,大物体的总体定位误差更小。

Yolov2
改进的点:
- Batch Normalization (代替dropout对模型进行正则化)
- High Resolution Classifier ()
- Convolutional With Anchor Boxes
- Dimension Clusters
- Direct location prediction
- Fine-Graied Features
- Multi-Scale Training
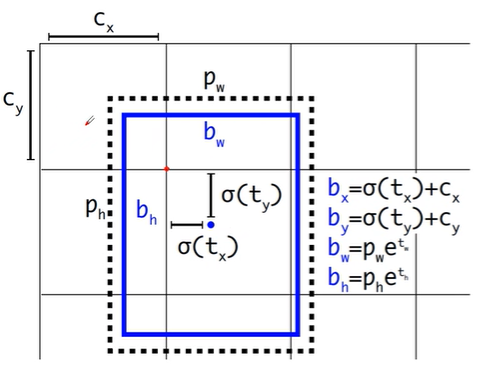
Yolov2的核心思想是:通过K-means聚类的方法获取数据集的目标的尺寸的先验信息作为anchor template(论文中K=5),于是通过聚类得以得到不同尺度大小的anchor template,下一步是要把anchor template应用到定位中,对于每个网格都有 K 个anchor template,其中心位于网格左上角,希望网络来学习anchor长和宽的调整,以及anchor中心位置的调整。
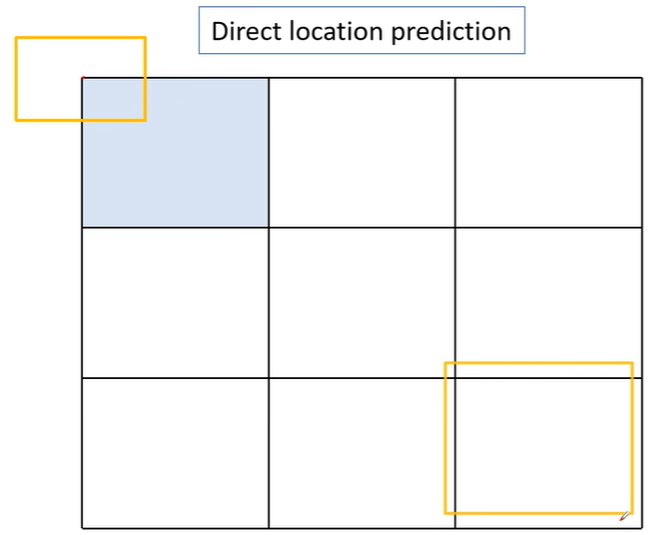
而对于中心位置的调整,希望通过损失函数的设计使每个网格中anchor位置的偏移不超出网格的位置,这样的设计是为了让每个网格的anchor仅负责该网格的定位,其通过以下方式来实现,其中 为网络的输出,而 为调整后用来计算定位损失的参数, 为sigmoid函数,将输入映射到 的范围,而 表示当前网格左上角像素点较整个图像的左上角的偏移,如上图为例,的范围是。表示为聚类得到的不同anchor的长宽,使用一个平滑的函数 进行微调(但是 的值域是不受限的,可能会出现无穷的情况,这在Yolov5中进行修改),同样分类损失结合IOU也通过sigmoid进行约束网络预测的 的范围。

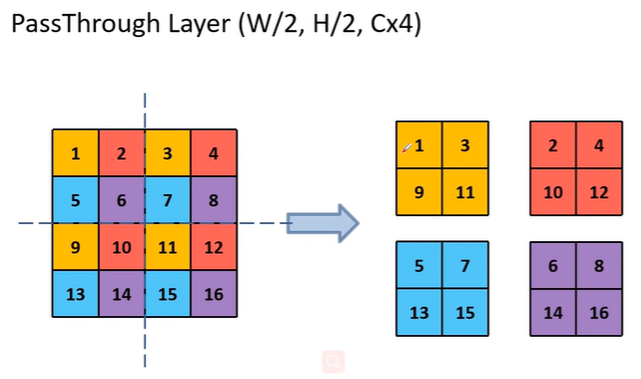
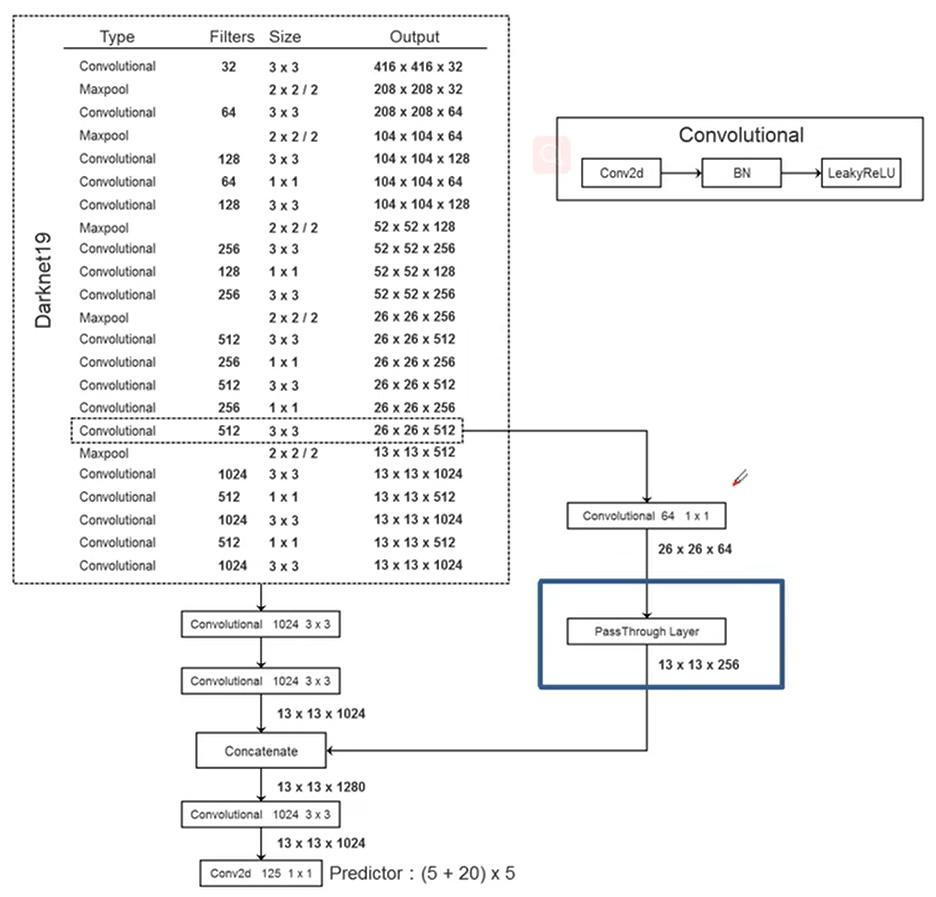
网络结构:采用了和ResNet类似的DarkNet作为backbone,对高尺度的信息做了PassThrough Layer特征重排降维,最后通过concatenation融合高低尺度特征。
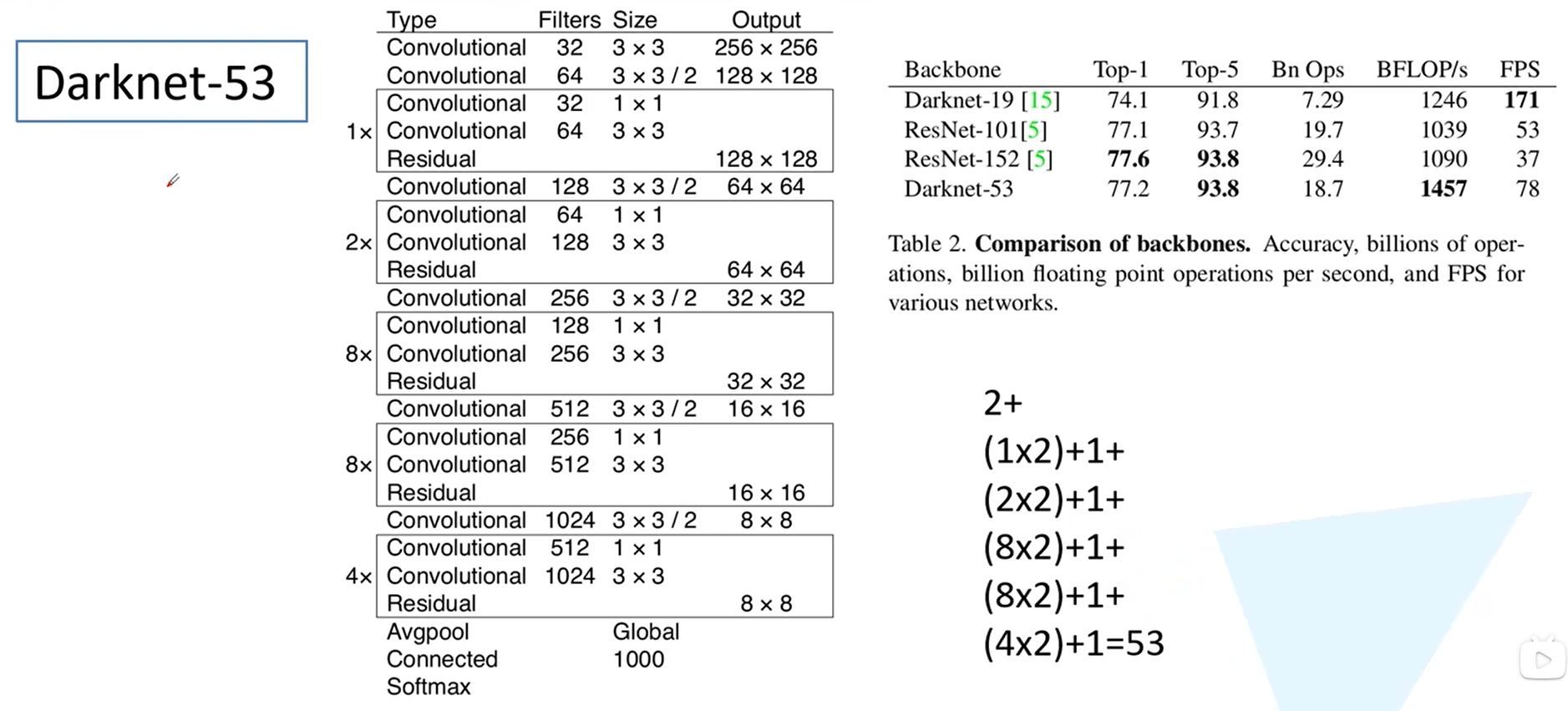
Yolov3
我认为Yolov3的核心是多尺度anchor template和多尺度检测头的提出,至于损失函数的修改并不是很重要。
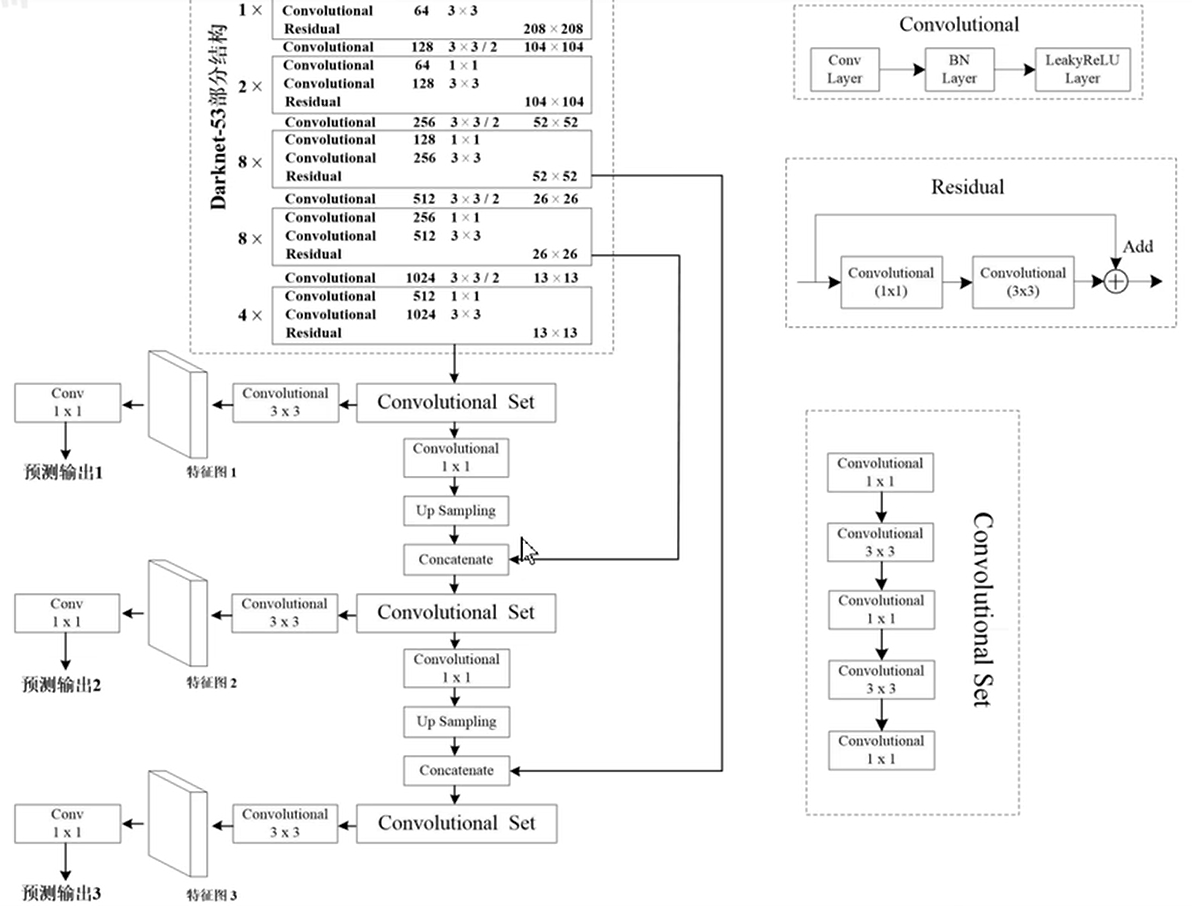
网络结构:backbone去Maxpooling,多尺度检测头的引入,有大中小三个不同尺度的分类头,其中每个分类头又有3个不同anchor,所以K-means通过聚类得到9个不同尺度的anchor
损失函数的设计


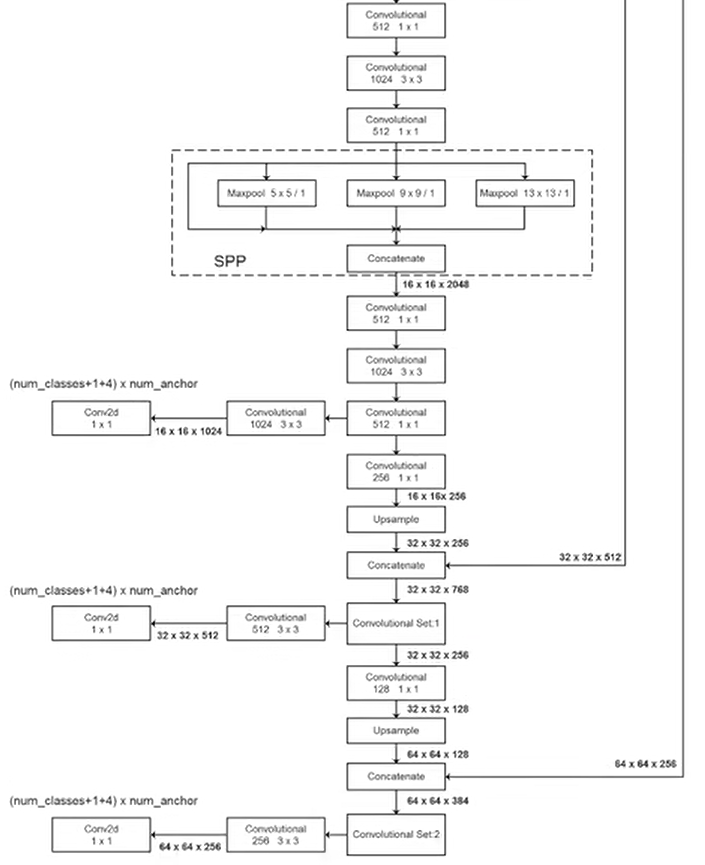
Yolov3-SPP
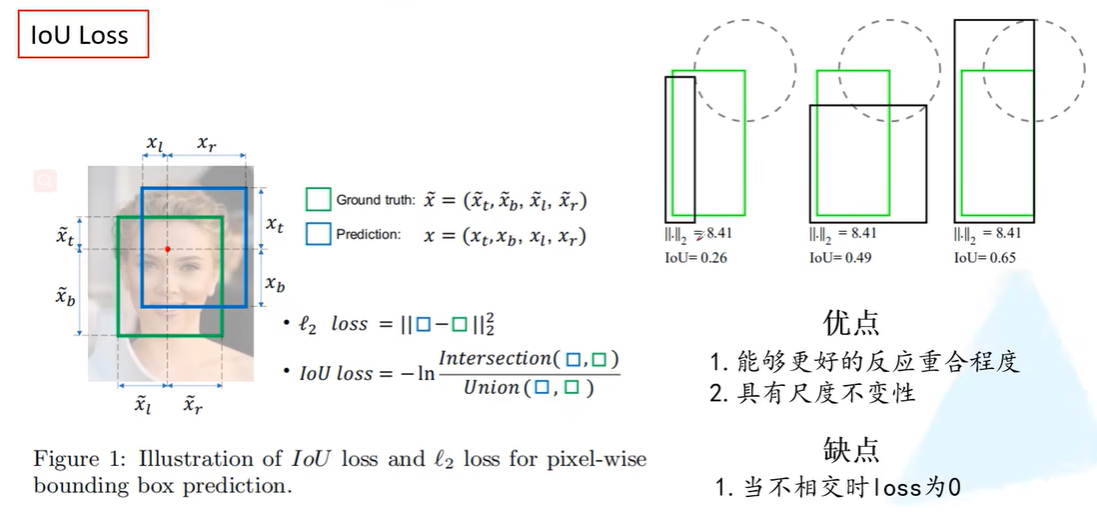
Yolov3-SPP的核心修改是以Mosaic为主的数据增强方式和新的IoU定位损失函数。

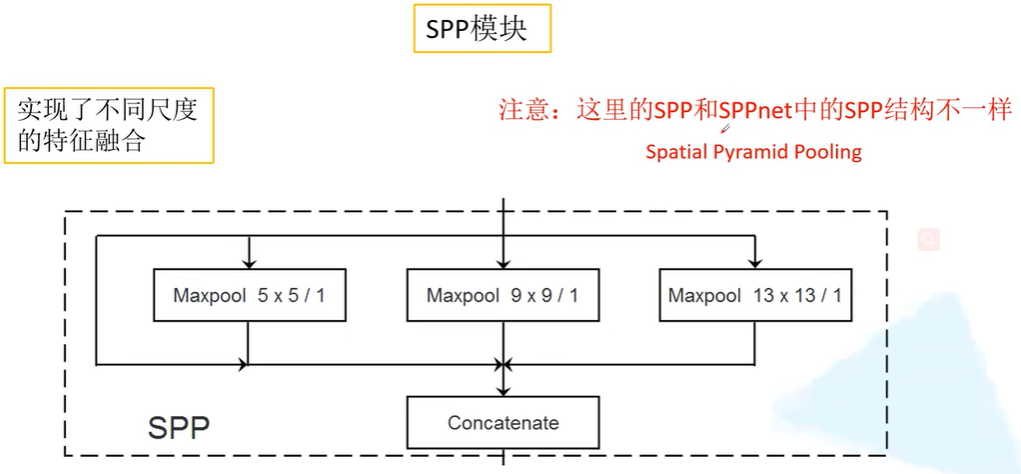
网络结构:SPP模块
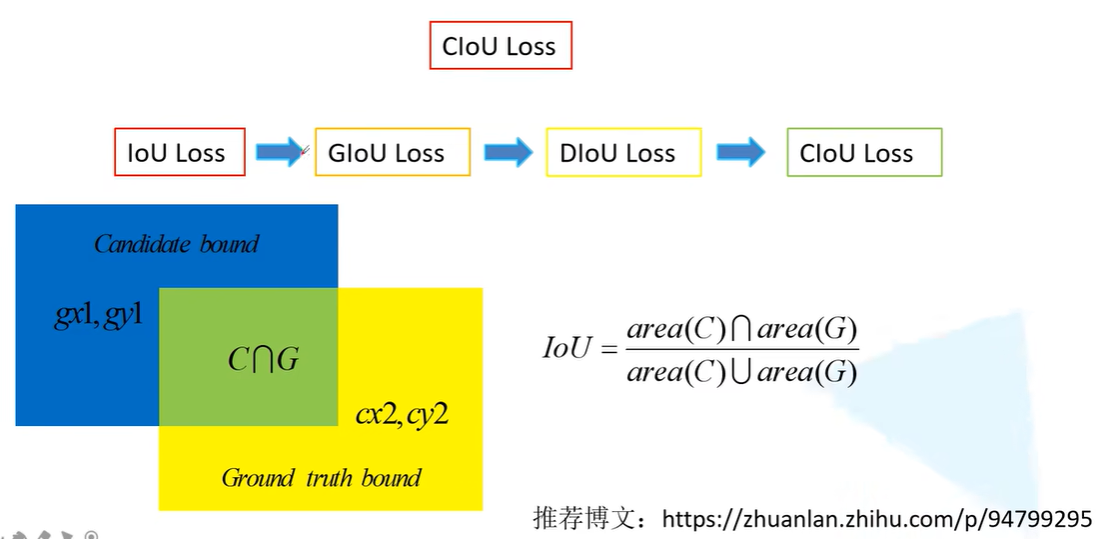
定位损失的演变:
GIoU:下图 表示中蓝筐的面积,$U$ 表示两个bounding box交集的面积;
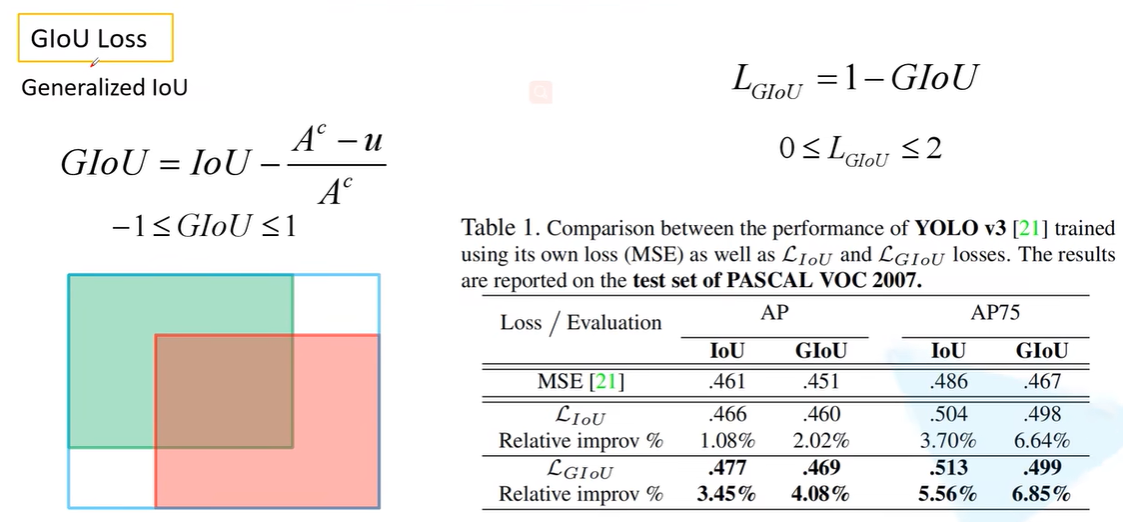
当目标框水平或者竖直平行的时候,GIoU Loss退化为IoU Loss

DIoU: 在下图的case中IoU Loss和GIoU Loss不能很好地区分三种不同的定位结果
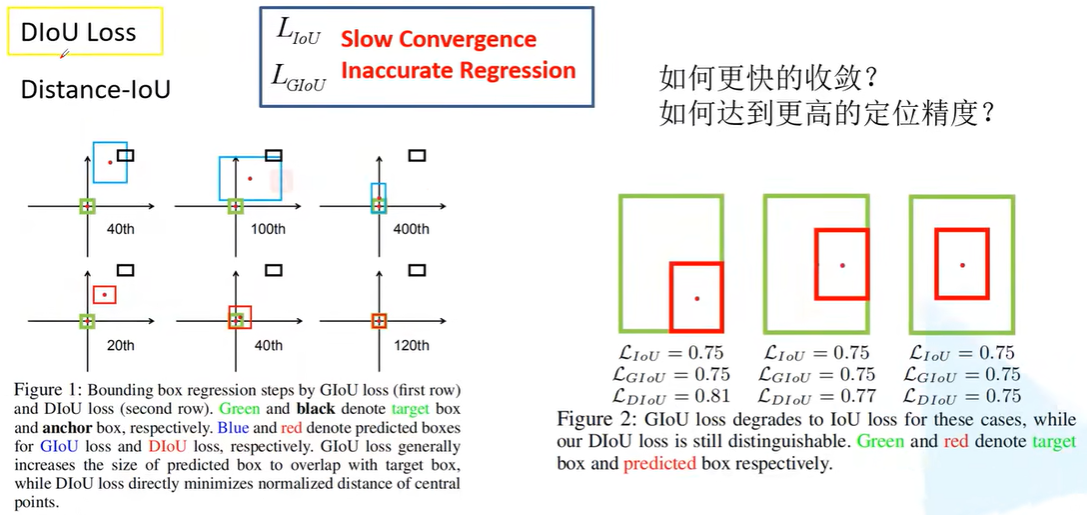
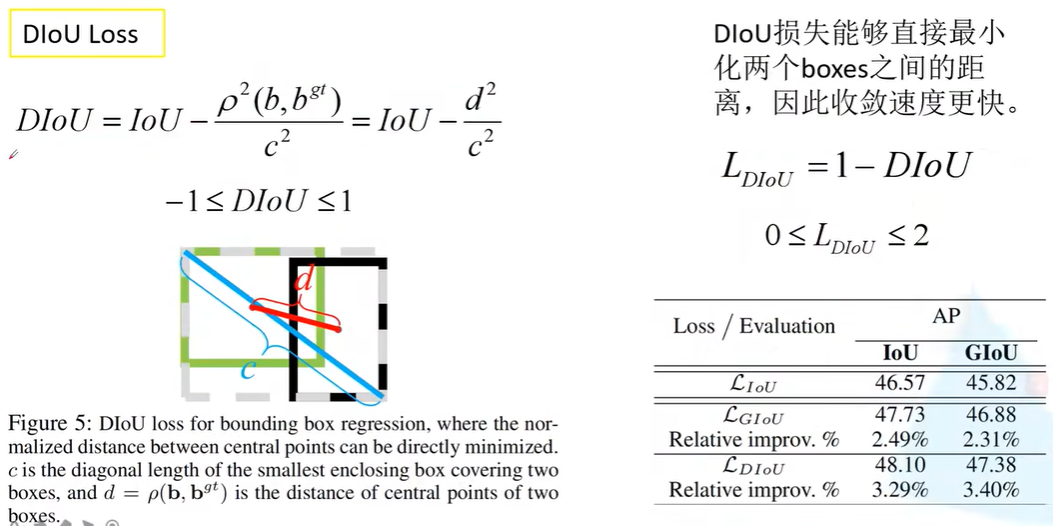
DIoU加上定位框的中心点的考虑,加快收敛速度。
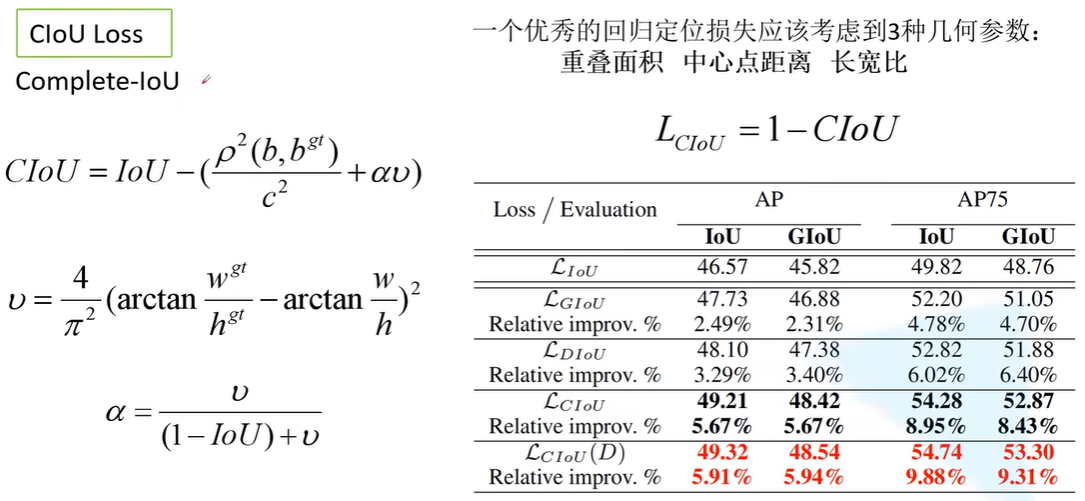
CIoU:提出一个优秀的回归定位损失应该考虑到3种几何参数:重叠面积(IoU)、中心店距离(第二项)、长宽比(第三项)。
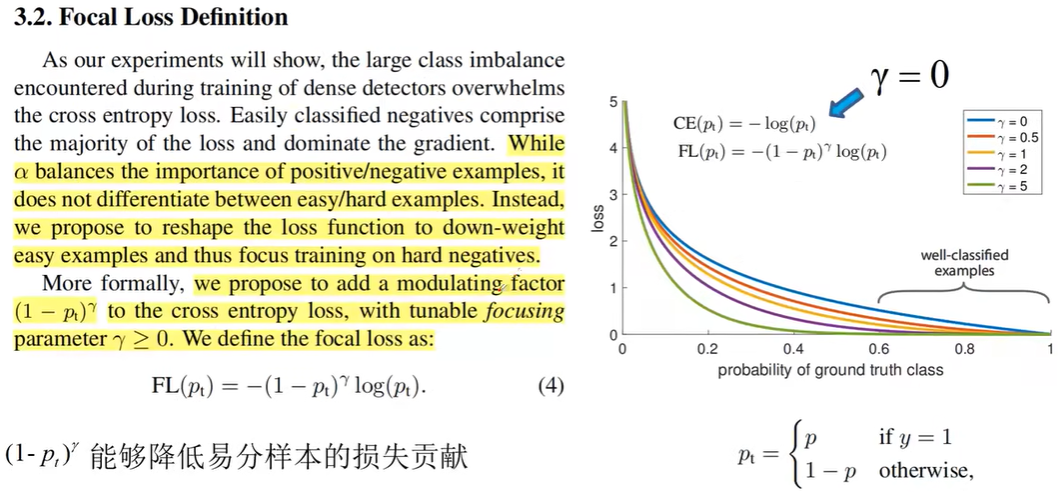
Focal Loss用来解决检测中,正负样本数量极度不平衡的问题,其中 是用来平衡正负样本权重的参数, 是用来平衡难易样本权重的参数,对难分的样本给予更大的权重。



Yolov4
核心修改:Eliminate grid sensititive,IoU threhold(match positive samples)
Yolov4 网络结构:1. CSPDarknet53作为backbone。 2. SPP,PAN的模块。3. YOLOv3的检测头。
网络结构:
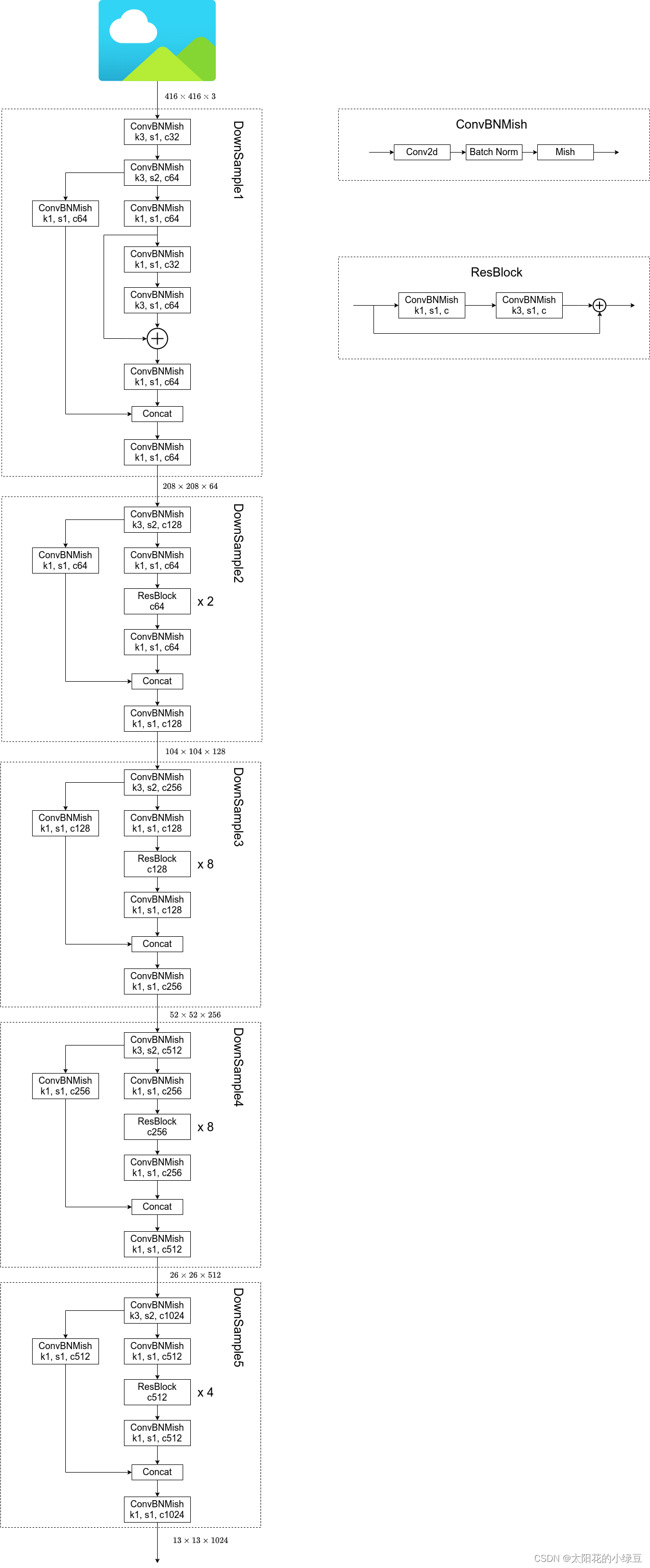
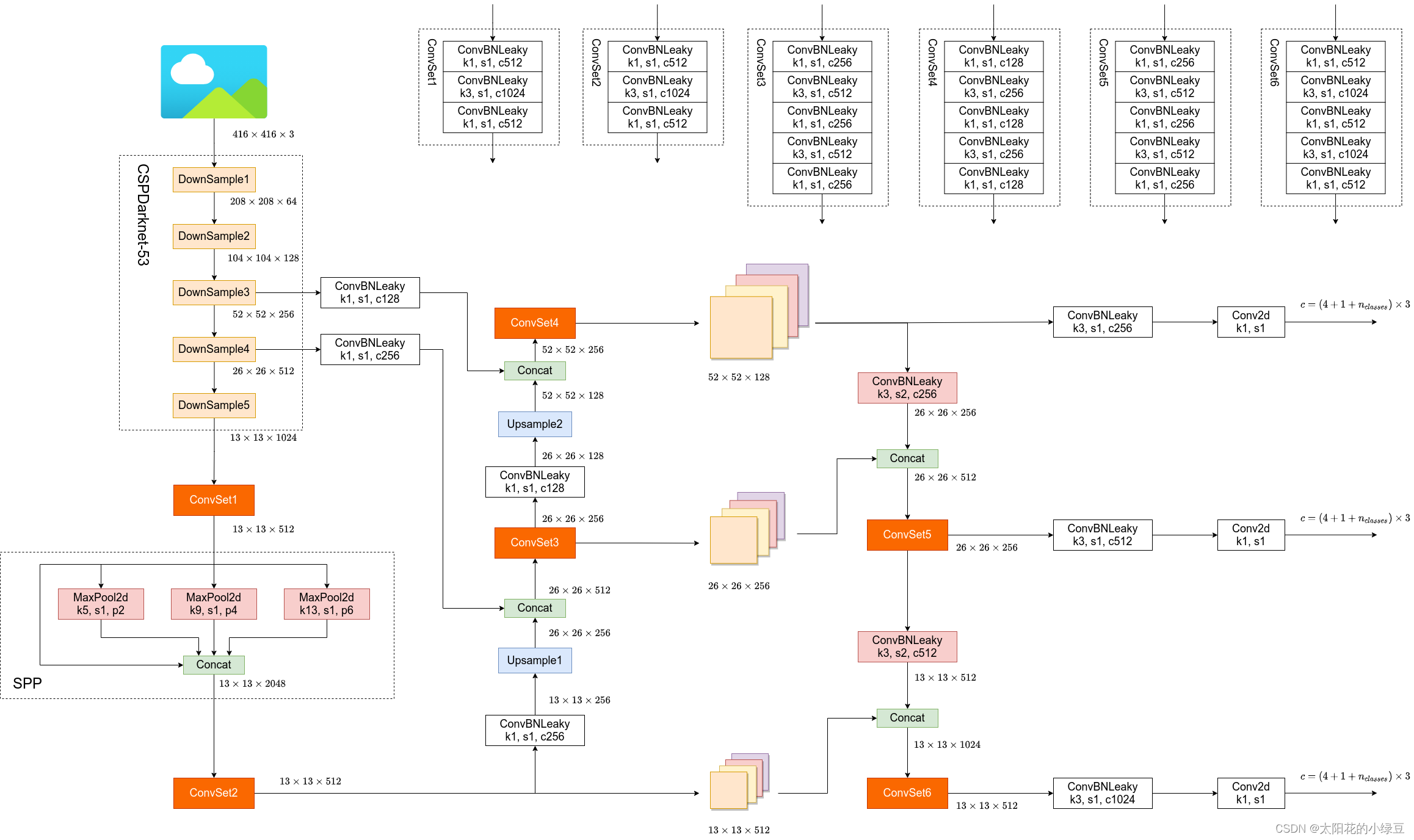
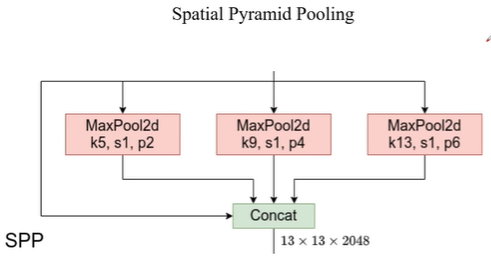
模块:SPP模块
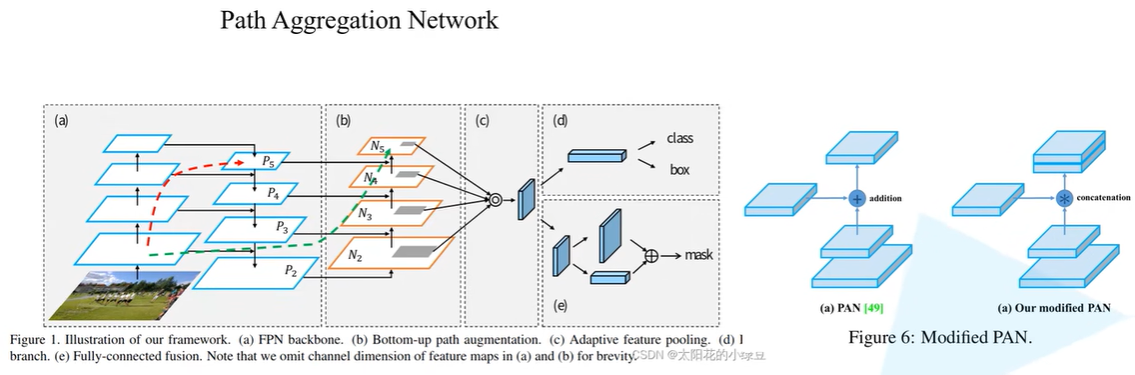
模块:Modified PAN模块,用concat融合
优化策略:Eliminate grid sensitivity
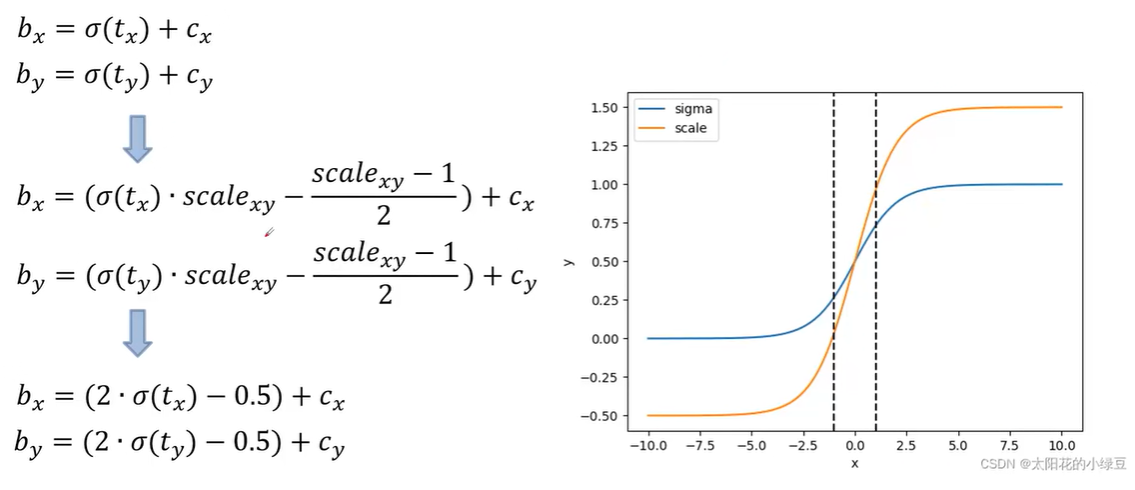
这个策略要解决的问题是,计算定位框中心点偏移的时候,通过sigmoid函数将偏移范围限定在sigmoid的值域的范围,但是对于边界情况,需要网络输出的 趋近于无穷才能使sigmoid后的输出趋近于1。
为了解决这个问题,加入缩放因子scale使sigmoid值域扩充为的范围
优化策略:IoU threhold(match positive samples)
原来grouth truth的定位框只会分配给其中心点所在的网络的anchor template进行预测,但是通过上述策略调整了偏移的值域之后,可以将ground truth分配给更多网格的anchor tenmplate进行预测。
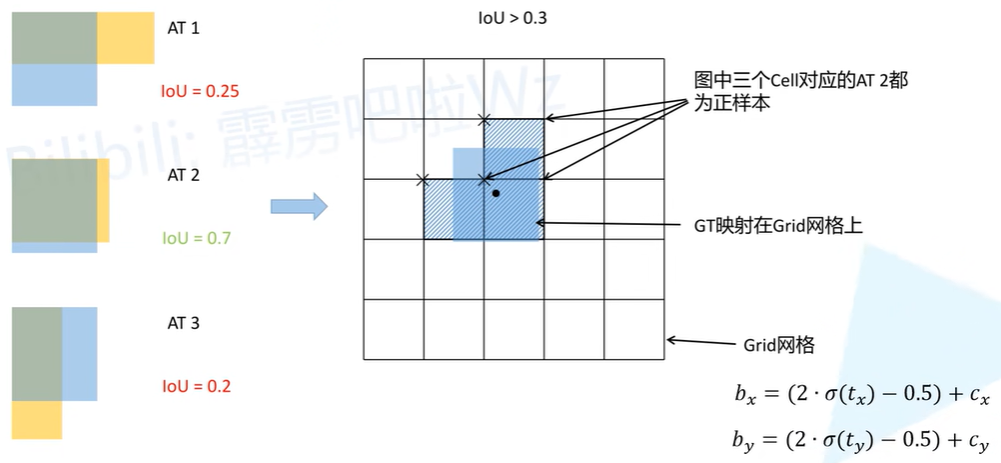
基于上这样的策略,可以将ground truth的定位框分配给更多网格的anchor来进行预测,以此增加更多的正样本。
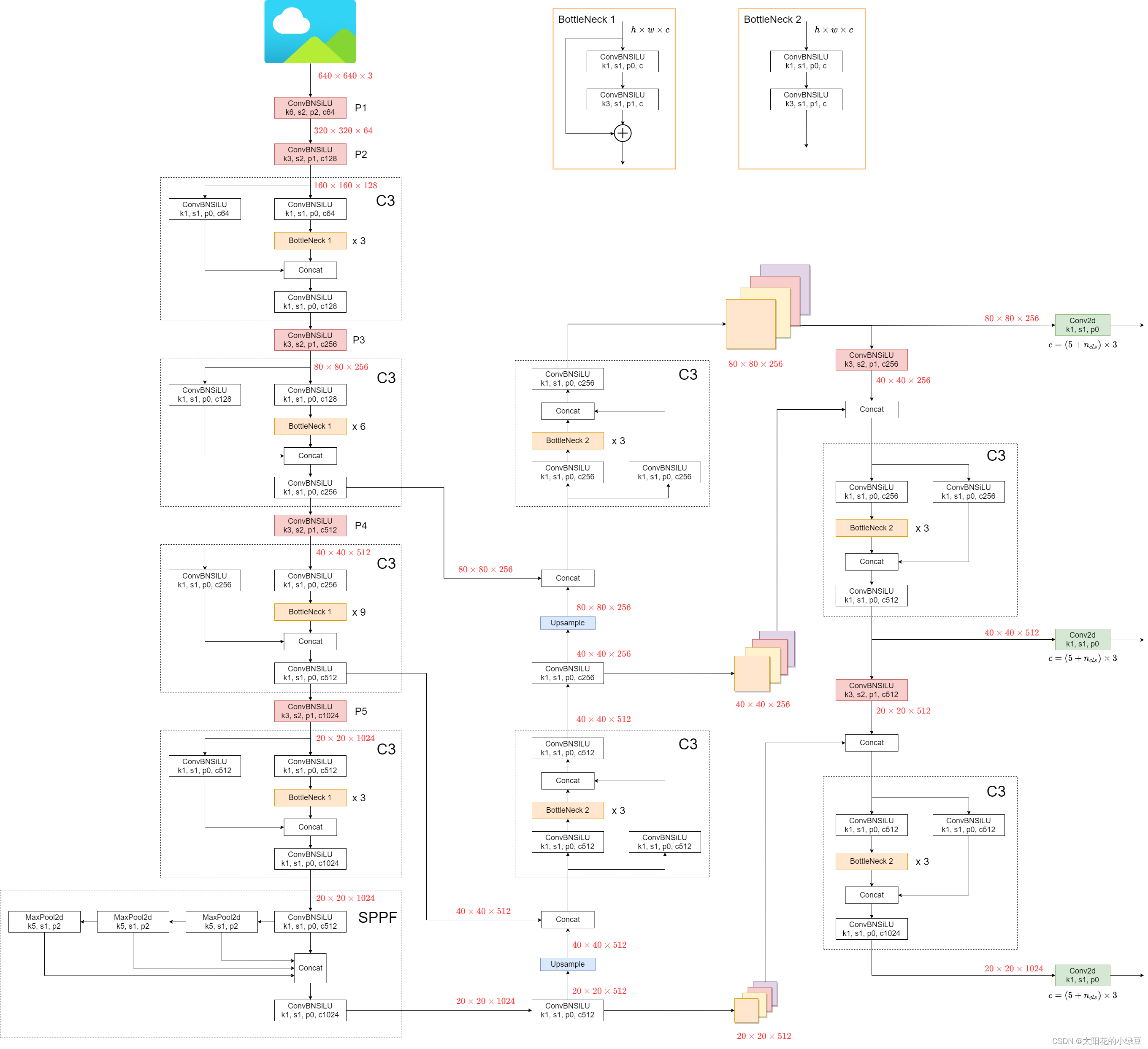
Yolov5
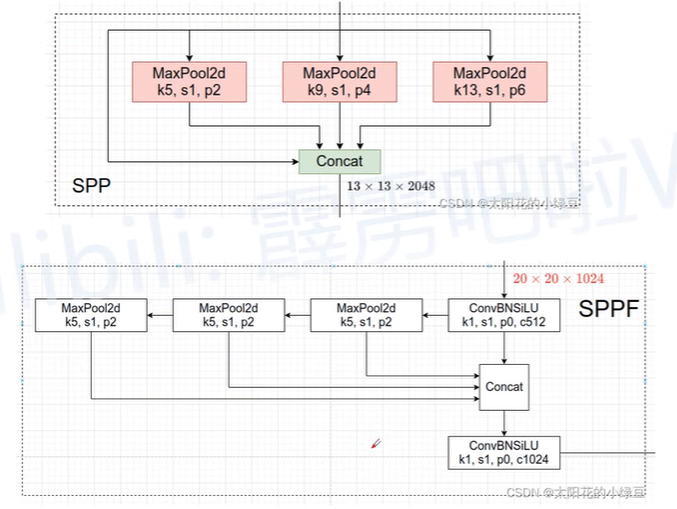
核心设计:模块SPP到SSPF的转变
网络结构:1. CSP-Darknet53作为backbone。2. SPPF,CSP-PAN作为框架。3. Yolov3的检测头
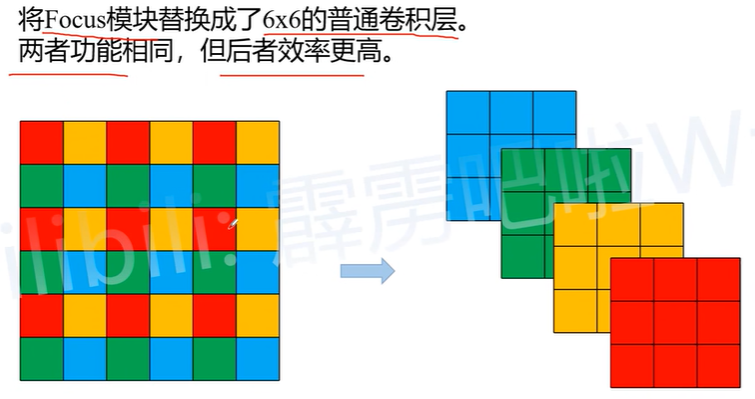
提速模块的设计:
将模块SPP修改为SSPF:
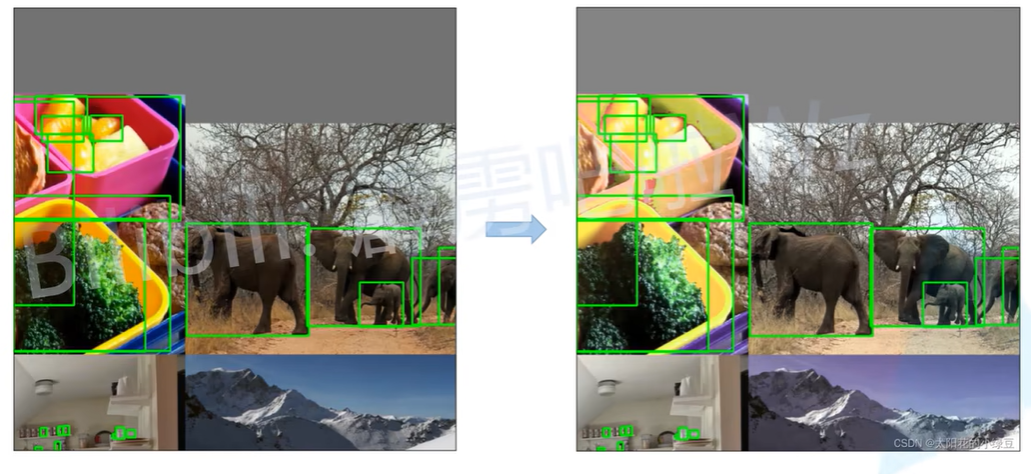
除了Mosaic数据增强还有Copy-paste数据增强策略:

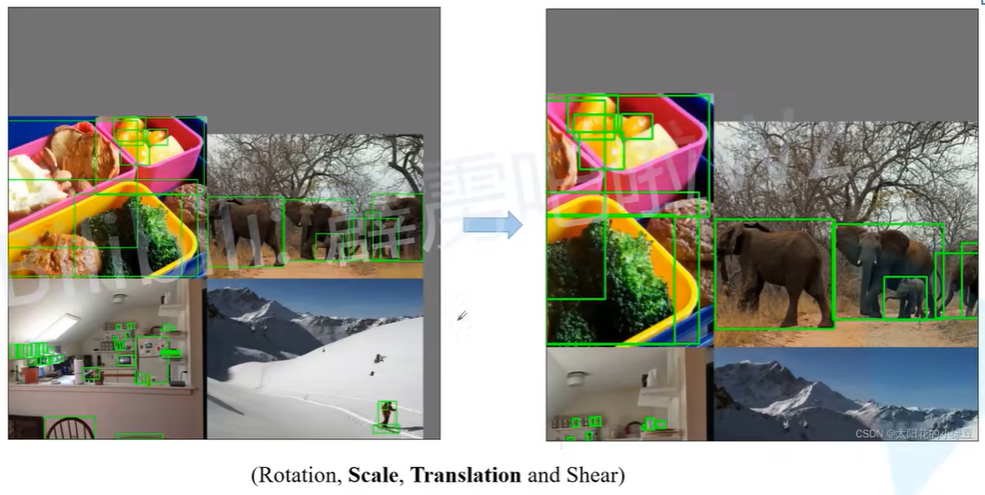
随机仿射变换Random affine(旋转、平移、错切):
Mixup,将两幅图按照不同透明度合并
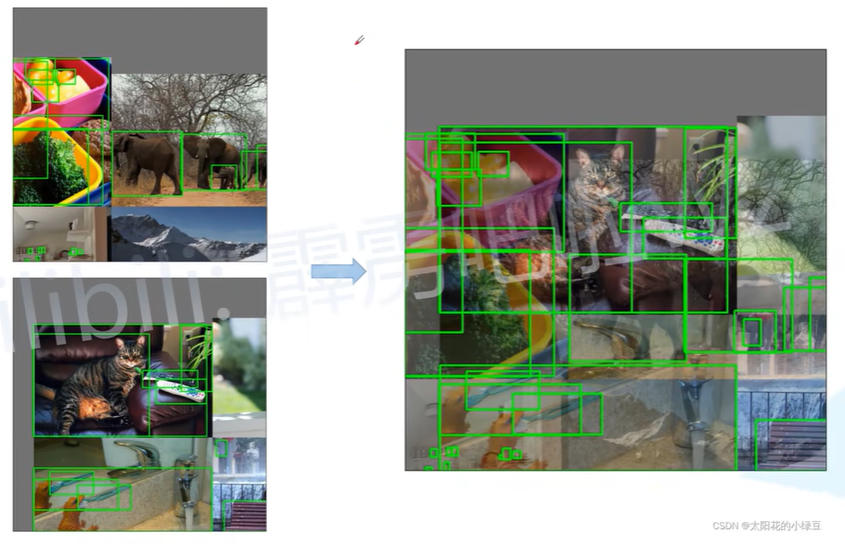
Albumentations:通过滤波、直方图均衡化以及改变图像质量等等
Augment HSV(Hue, Saturation, value):色度、饱和度、对比度
随机水平翻转 Random horizontal flip

训练策略:
- Multi-scale training(0.5x-1.5x) 多尺度训练
- AutoAnchor(For trainining custom data) 重新聚类得到新的anchor template
- Warmup and Cosine LR scheduler
- EMA(Exponential Moving Average)
- Mixed precision 混合精度训练,加速和压缩
- Evolve hyper-parameter
损失函数

平衡不同尺度损失

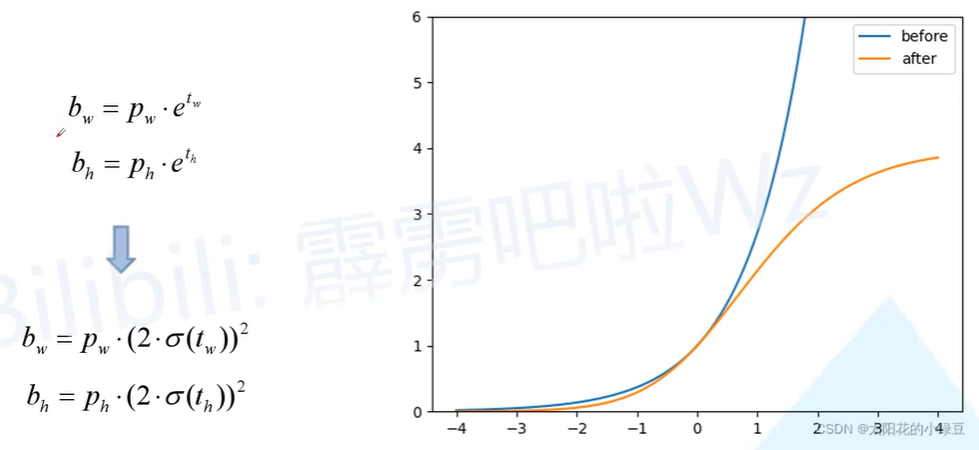
消除Grid敏感度
将激活函数转为sigmoid,防止 值域过大造成数值爆炸带来的损失危难、训练不稳定的问题。
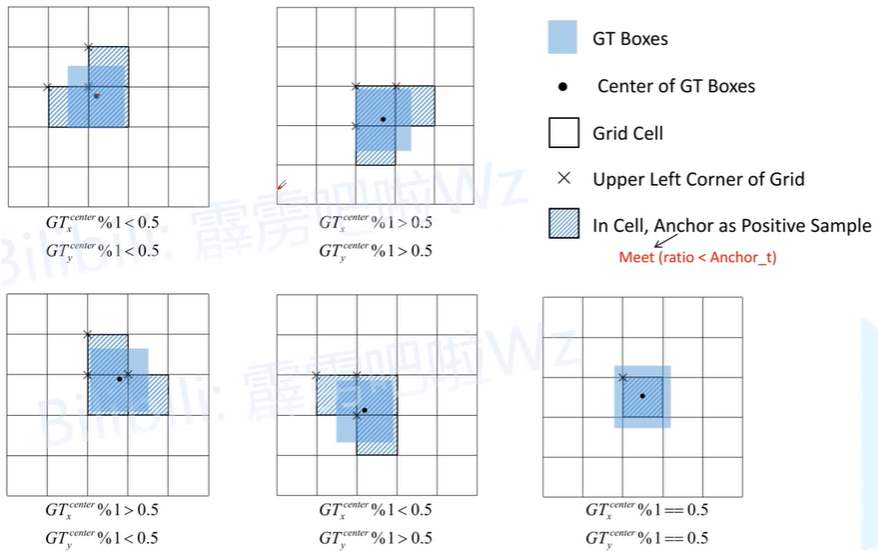
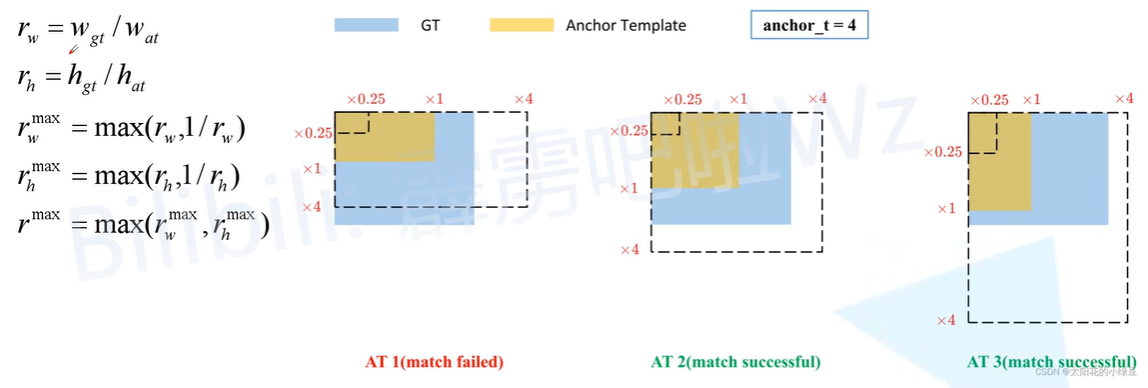
匹配正样本
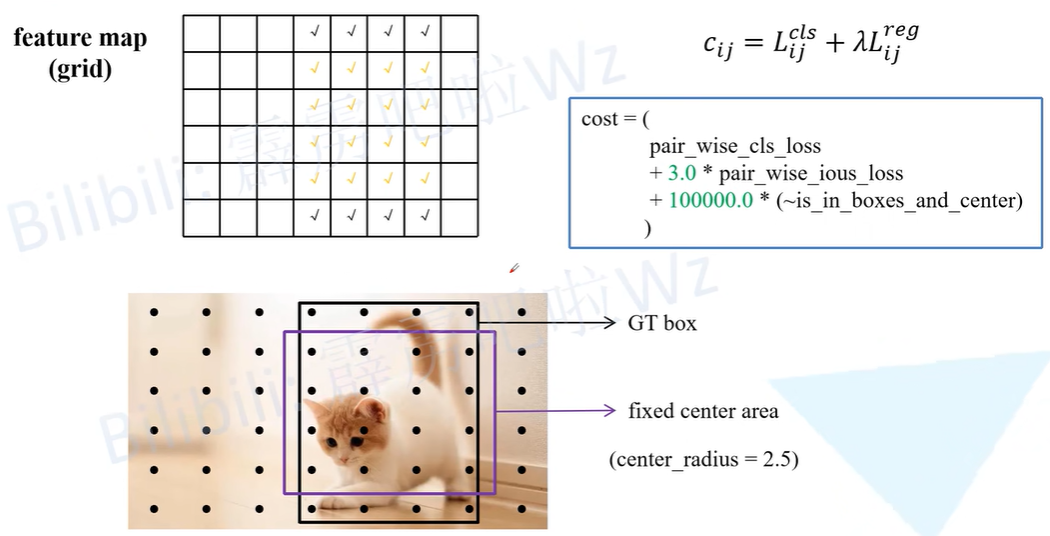
如果,则匹配成功;否则匹配失败(如下图蓝框超过虚线)
YoloX
核心修改:Anchor free
网络结构:
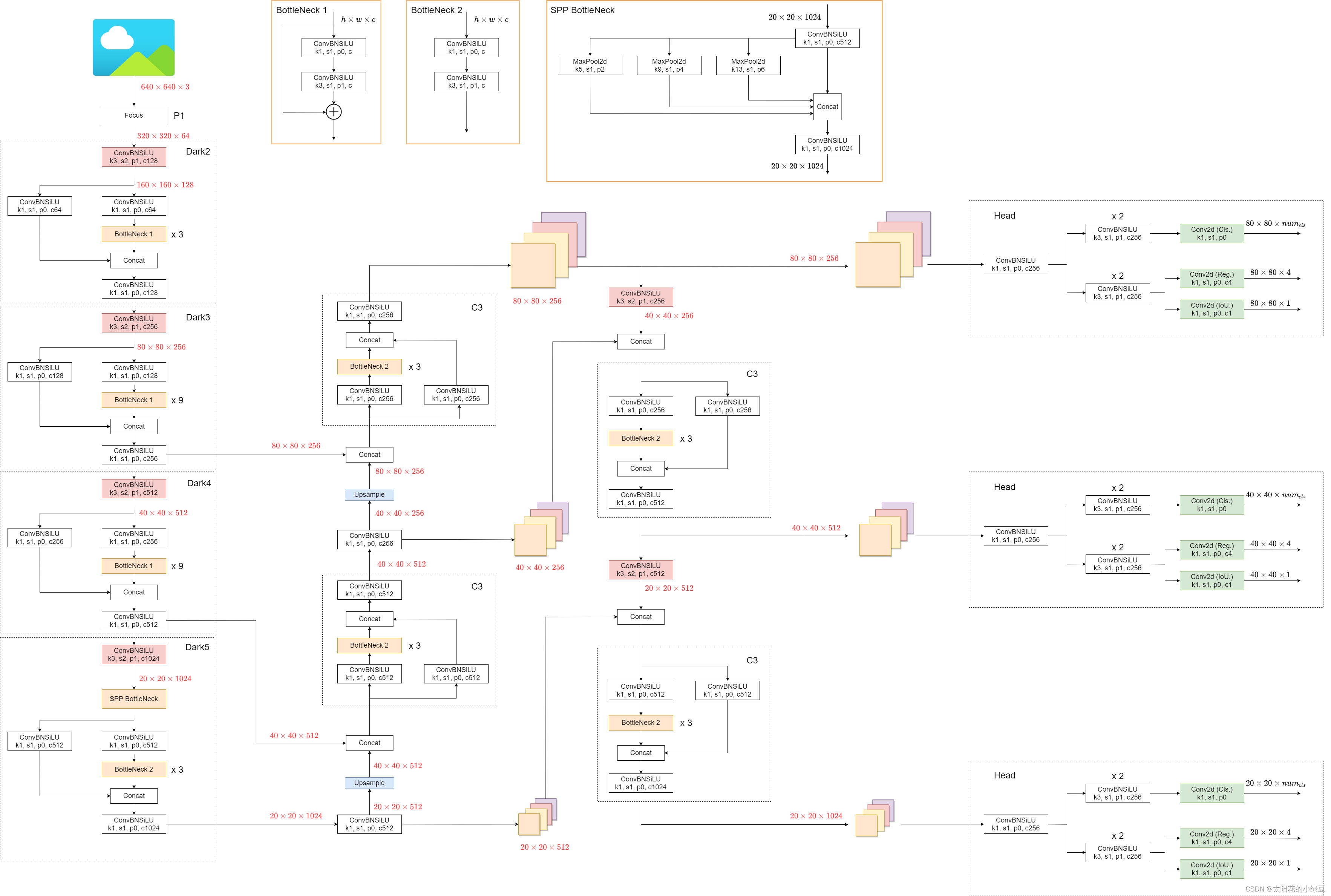
decoupled detection head
加速收敛,提升AP,参数不共享。所谓的解耦是指将检测头中定位、定位置信度和分类的功能进行解耦。
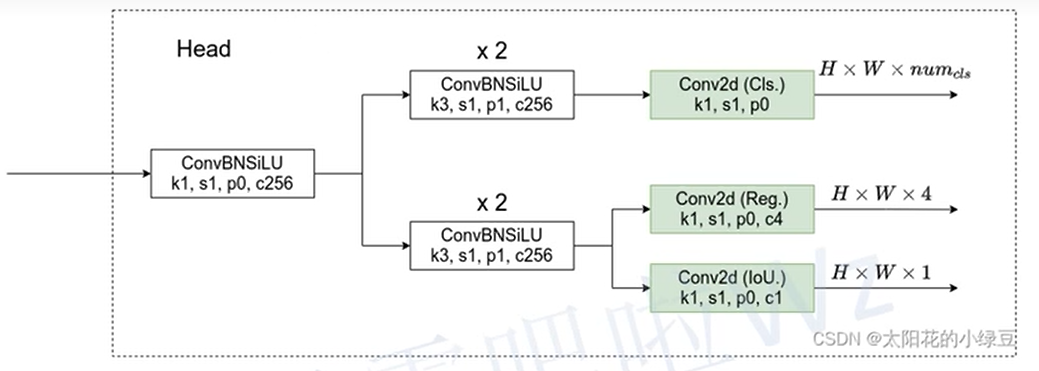
Anchor-Free
每个网格设置几个锚点(没有template),每个锚点对定位框进行预测
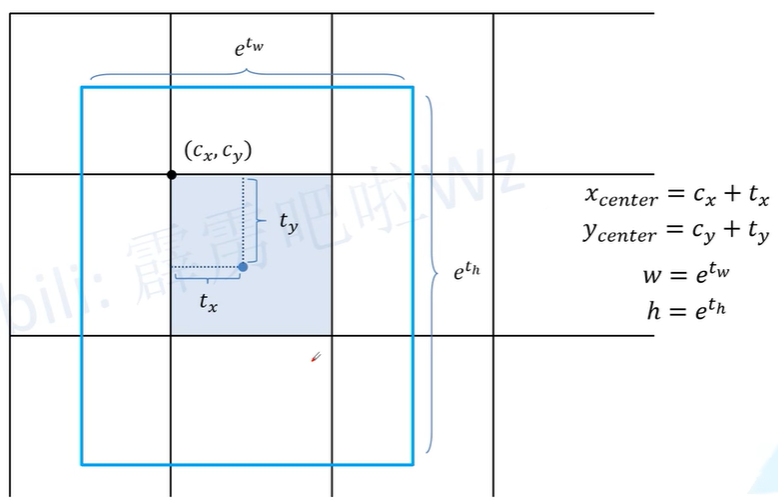
损失函数:

正负样本匹配SimOTA《Optimal transport assignment for object detection》,目的是将匹配正负样本的过程看成一个最优传输问题。