抽空记录中,不研究内容prompt,目前在别人写的prompt下用不同工具调优。
目前的感觉是,场景物体细节越多的图,人物手和面容(眼睛、睫毛)的正常生成非常困难,即使有相关的Lora和negative prompt的进行加持,但基本上只在肢体离镜头比较近的时候才能正常work。既要保证场景内容丰富,又要保证肢体正常绘制,基本不可能一次正确生成,目前的策略是在喜欢的构图上进行肢体细节调优。
基于stable-diffusion-webui 1.6.0写的使用说明,版本更新时间是20230928。
预训练模型下载网站:
基本使用方法
项目安装
项目地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui
windows 环境下用 git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui 下载到本地,双击执行 webui-user.bat 以自动安装环境。
目录说明
1 | - modules // 网络定义 |
启动参数
webui-user.bat
1 | @echo off |
参数获取
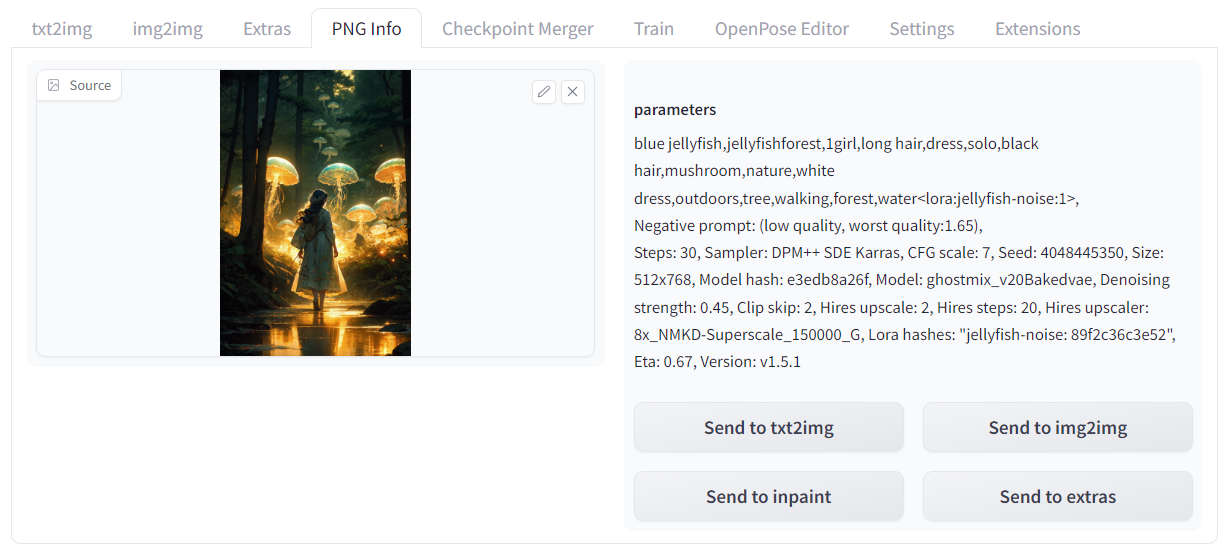
只需要在 PNG info 中拖入图片就可以获取生成时使用的相关参数,这看起来是因为SD-webui会将参数信息植入到图像中进行保存,如果 parameters 返回 None,则说明该图片可能不由SD-webui生成,或许是由 Midjourney 生成。
使用相关参数大概率可以复现出该图,但需要注意的是需要自己下载 positive prompt 中的 Lora 模型以及 negative prompt 中的 embedding,即便确保无误也无法完全复现,则证明该图是经过本人多次处理如Inpainting、Outpainting得到的结果。
插件安装
一般有两种安装方法,一种是在 Extensions/Avaliable 中从 https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui-extensions/master/index.json 读取可安装的插件列表,想安装什么插件就搜索关键字然后找到 stars 最多的那个;另外一种是从 Extensions/install from URL 中从 git repository 中下载。
Civitai Helper
该插件能扫描所有模型,从Civitai下载模型信息和预览图进行显示。
安装完成后,需要先在tag页面中进行扫描操作:
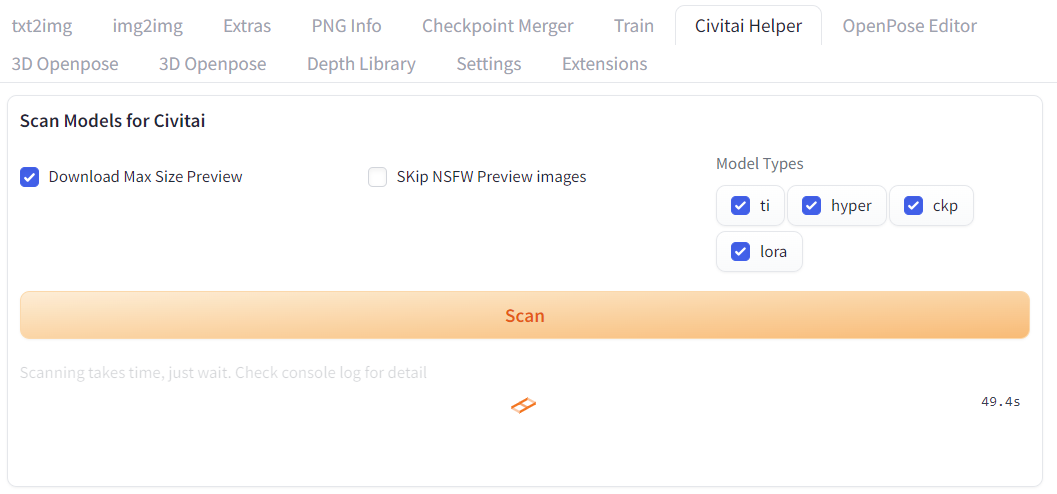
这个操作可以从civitai上下载匹配的模型对应的缩略图,需要等待一段时间(取决于下载模型的多少):
扫描完成后,点击图标:
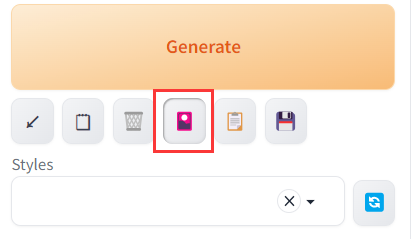
即可显示模型和对应的缩略图,更多使用方法请见 github:
注:没有缩略图显示部分需要在对应模型目录下补一个同名图片。
ADetailer
可以用yolo模型检测手和脸的位置,并为这些部位进行单独重绘。

提示词
a1111-sd-webui-tagcomplete
一个prompt自动补全插件。可以在youtube获取中文翻译。具体步骤如下:
- 在google drive中下载
danbooru-SC.csv简体中文翻译文件。 - 将
danbooru-SC.csv放在extensions\a1111-sd-webui-tagcomplete\tags中。 - 于stable-diffusion-webui的配置中,
Settings\Tag Autocomplete的Tag filename和Translation filename选项中分别设置danbooru-SC.csv
安装完成后可以在txt2img和img2img的prompt中看到相关选项:
sd-webui-prompt-all-in-one
sd-webui-prompt-all-in-one旨在提高提示词/反向提示词输入框的使用体验。它拥有更直观、强大的输入界面功能,它提供了自动翻译、历史记录和收藏等功能。可以结合a1111-sd-webui-tagcomplete使用。如果页面在sd-webui初次启动时没有正常显示该插件内容,可以 F5 刷新页面。
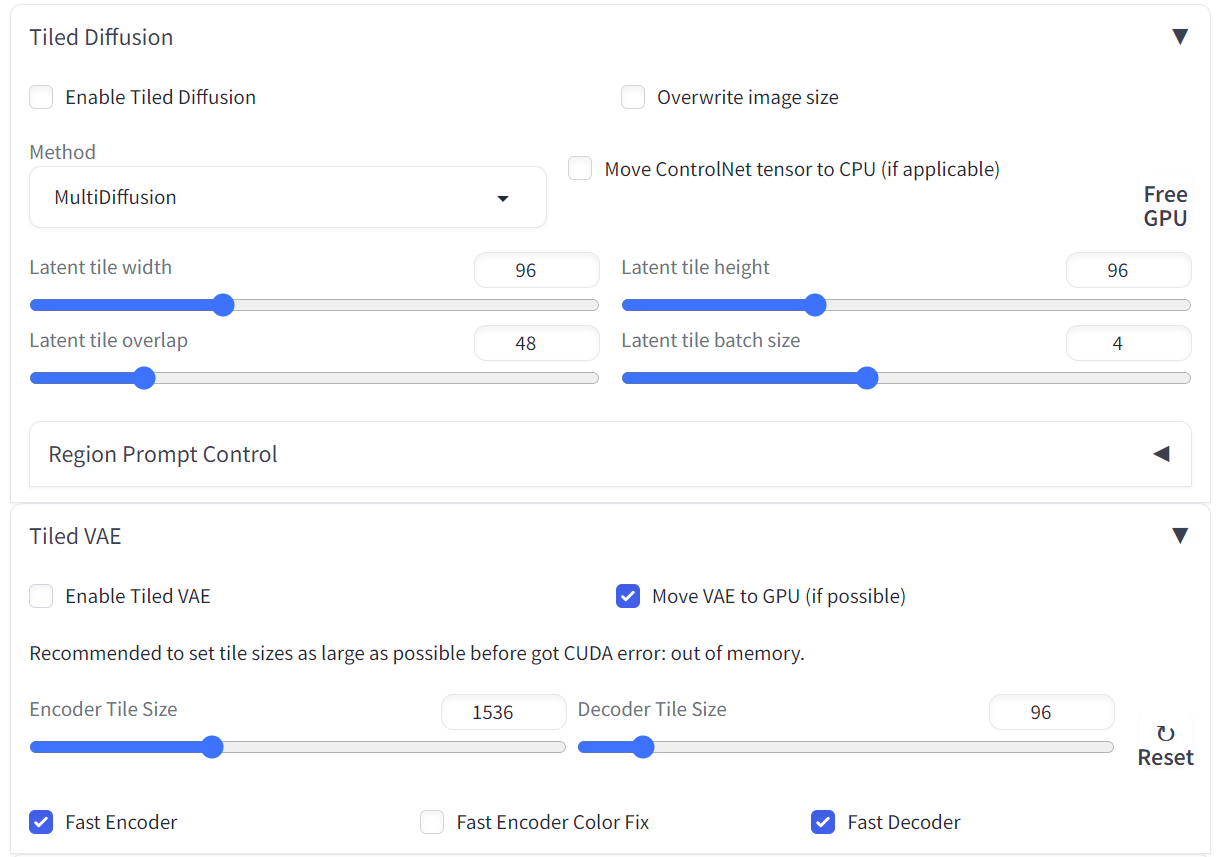
分块扩散
multidiffusion-upscaler-for-automatic1111
基于 Mixture of Diffusers 和 MultiDiffusion 的分块扩散模型。
感觉 Tile VAE 部分可以正常使用,但是 Tile Diffusion 在 size 比较大的图像上容易导致内容重复绘制。
安装完成后可以在txt2img和img2img的选项卡中看到相关选项:
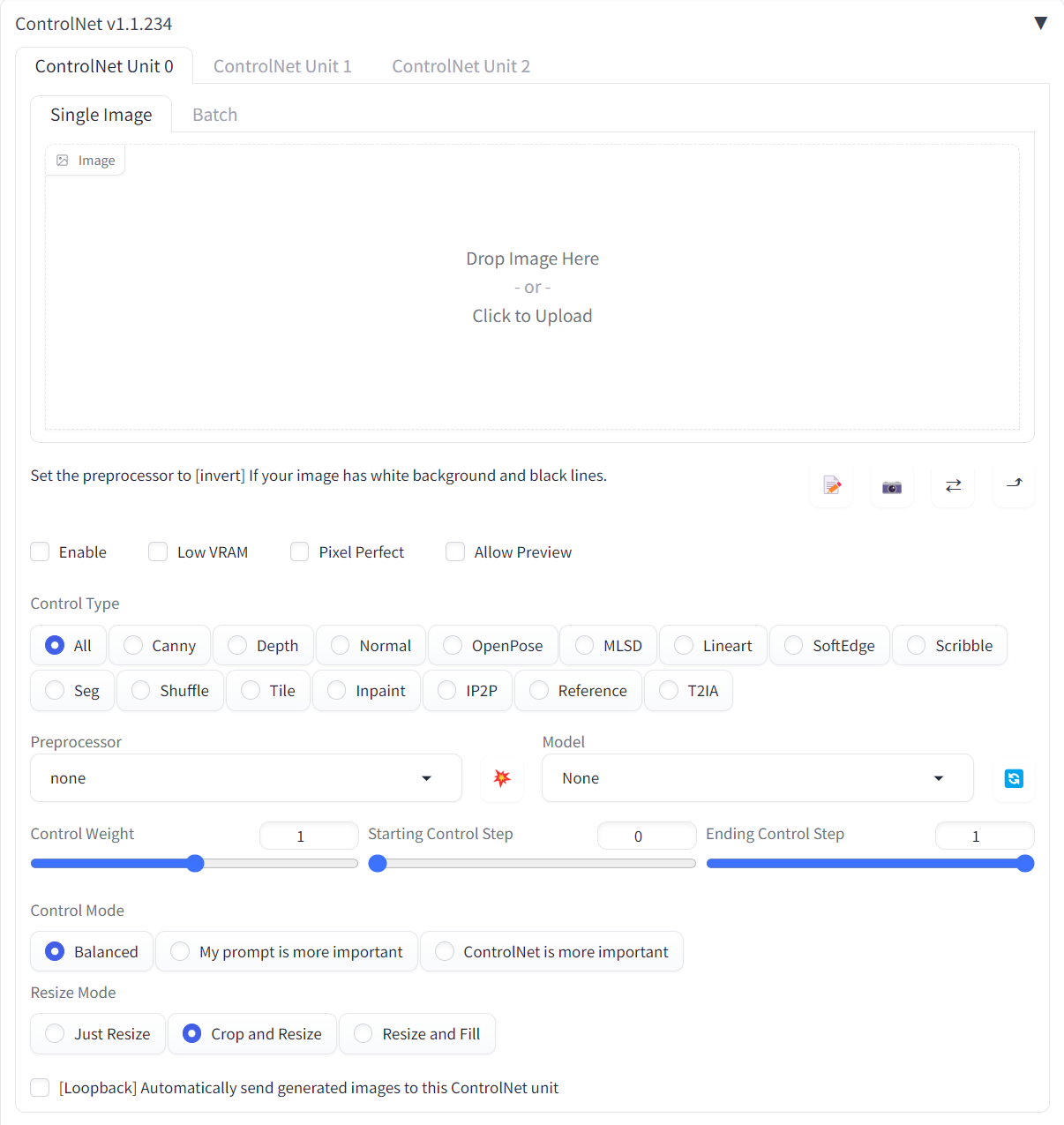
ControlNet相关
sd-webui-controlnet
基于 ControlNet 的条件扩散模型。
安装完成后可以在txt2img和img2img的选项卡中看到相关选项:
sd-webui-depth-lib
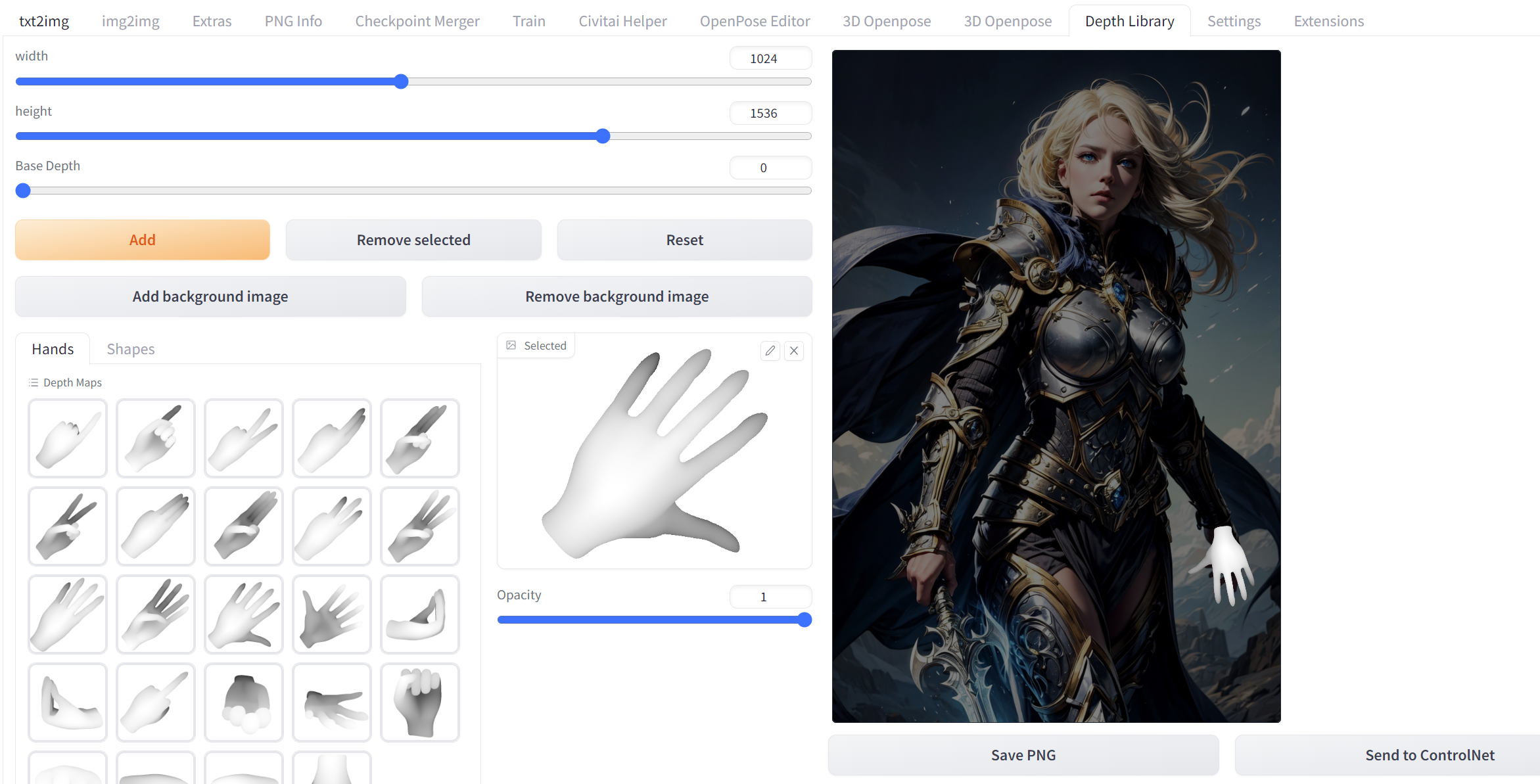
可以在对应位置摆上和调整手势深度图作为controlNet的输入。
在 900 Hands Library for Depth Library | ControlNet 网站上可以下载更多的不同手势的深度图。

下载后的 .zip 文件解压后里面的图片和 extensions/sd-webui-depth-lib/map 的深度图手势进行融合。
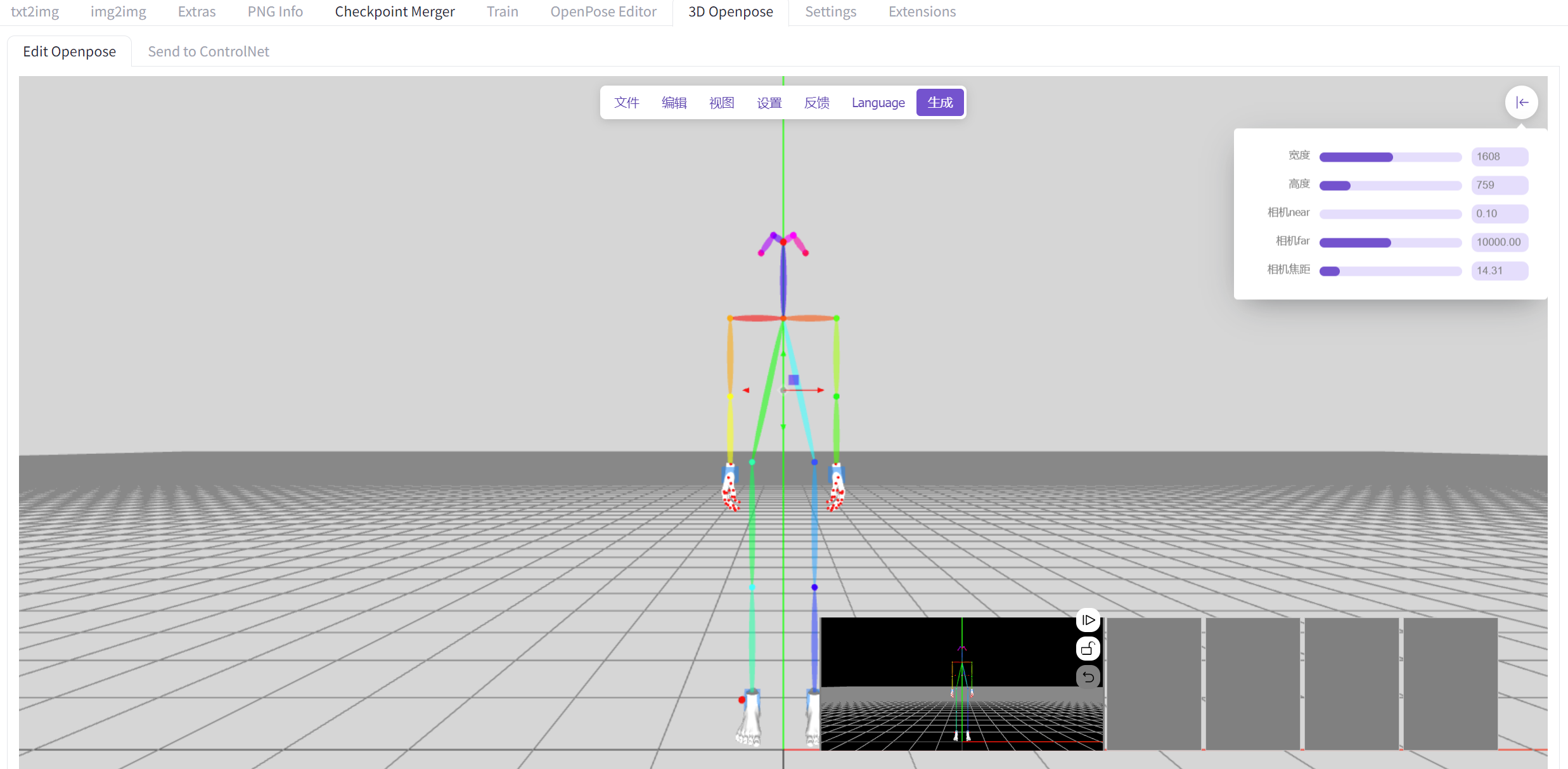
OpenPose Editor Tab
这个插件可以生成2D的openpose
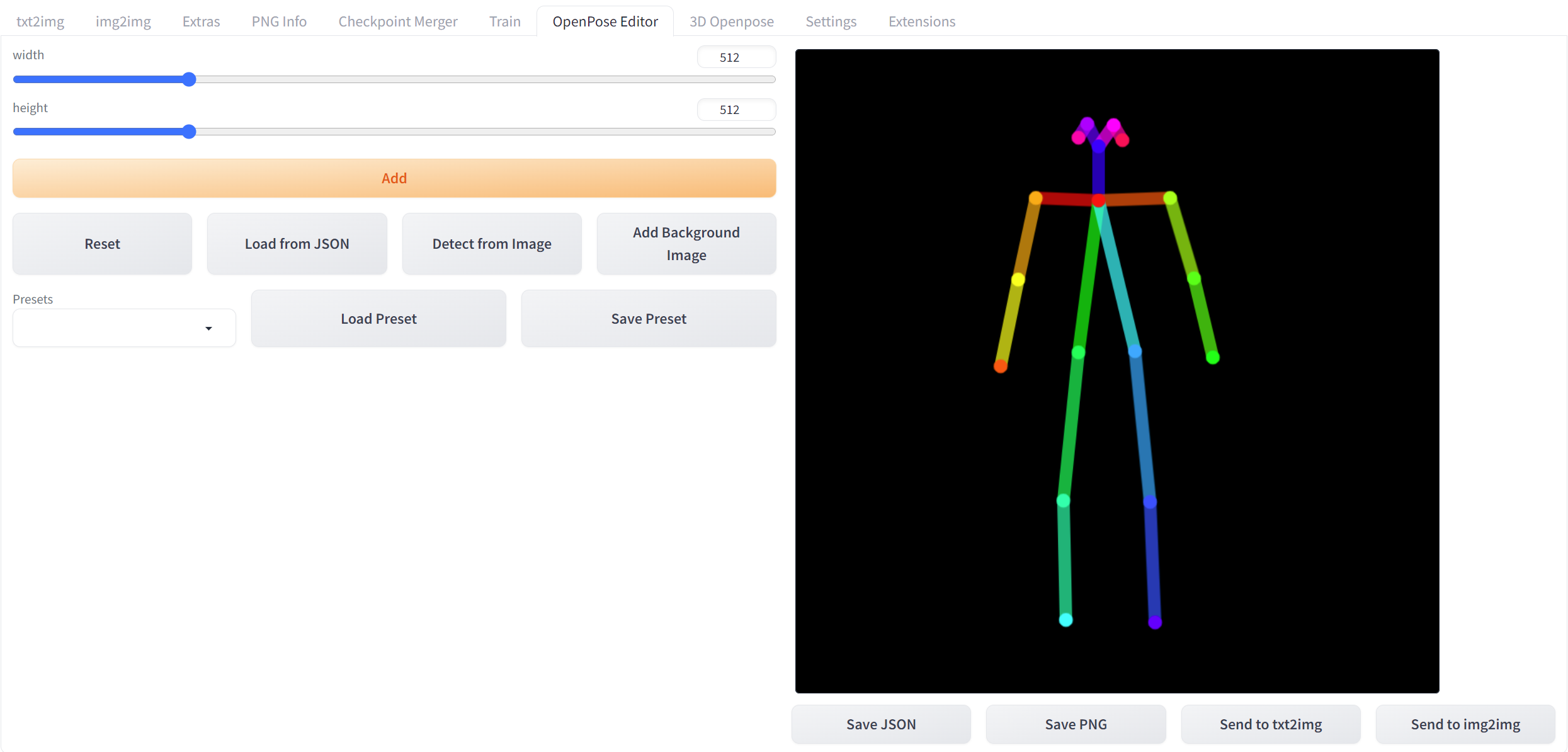
sd-webui-3d-open-pose-editor
基于SD的超分
sd-webui-stablesr
基于StableSR的图像超分模型。
因为工作内容相关,所以对这个模型理解比较深入。
安装完成后可以在img2img的Script的选项卡中选择以看到相关选项:
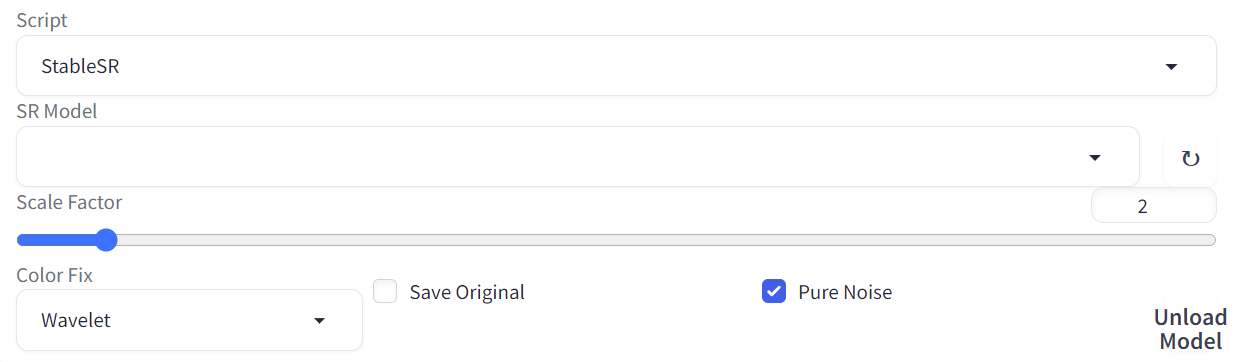
下载好的StableSR预训练模型需要放置在extensions\sd-webui-stablesr\models中
LyCORIS
“All its features have been integrated into the native LoRA extension
LyCORIS models can now be used as if there are regular LoRA models”
看起来后面的stable-diffusion-webui把这个功能集成了。
a1111-sd-webui-lycoris
安装插件后,需要在 model 的目录下创建一个文件名为 LyCoris 的文件夹,然后将模型保存其中,调用模型需在 prompt 中写入 <lyco:model:1>的形式。
界面设置
sd_vae显示
在Setting->Show all pages中找到Quicksetting list,在其中加上sd_vae,如下图所示:

随后点击Apply settings之后Reload UI,可以看到页面上出现VAE的选项:

Face Restoration
从1.5.0更新到1.6.0之后页面不再显示这个页面,需要到 Setting/Show all pages 中找到 Options in main UI,搜索 face_resotration 和face_restoration_mode 等都选上才能显示。

模型
Stable Diffusion
对于Stable Diffusion而言,1.99GB的一般是fp16的模型,更大的一般是fp32的模型。
SHMILY梦幻水彩,水彩风图像。
ghostmix_v20Bakedvae,类似攻壳机动队图像。
XXMix_9realistic,景深风格人像居多。
majicMIX系列,如:
Dark Sushi Mix 大颗寿司Mix,二次元画风。
VAE
- vae-ft-mse-840000-ema-pruned-vae.pt:该模型可以使生成的图片对比度更高,色彩更加丰富。
下面是例子:

LoRA
- add_detail,用以增加细节。
- more_detail,用来增加细节。
- Jellyfish-noise,用来生成水母森林。
- loong2-000015,用来生成中国龙。
- NijiExpressive_v2,用来生成忍者风格的人物。
epi_noiseoffset,提高暗场景下单的对比度。
iu_v35,画的是IU。
- BeautyNwsjMajic2-01,画的是娜乌斯嘉。
- sxz-death-knight,魔兽世界的骑士风格。
- hipoly_3dcg_v7-epoch,可以增加手部出图的稳定性。
- geometric_shapes,几何形状。
- Ink scenery,山水墨画。
- reference sheet-model,绘制参考图
- 焱落纱_v1.0,熔岩衣服
- Sun and Shadow(LAS),强烈的光影对比。
- FilmVelvia2, 胶片风。
- anxiang, 中国古风。
- circrex,机甲风
LyCORIS
- GoodHand,用来增加手部稳定出图概率。
embedding
大部分是在做手,一部分在做肢体。
上采样方法
- 4x-UltrSharp
- R-ESRGAN 4x+Anime6B
- 8x_NMKD-Superscale_150000_G
- StableSR
功能
Inpainting
尽量使用和 text2img 相同的 prompt、negative prompt 和 sampling method 等。
Outpainting
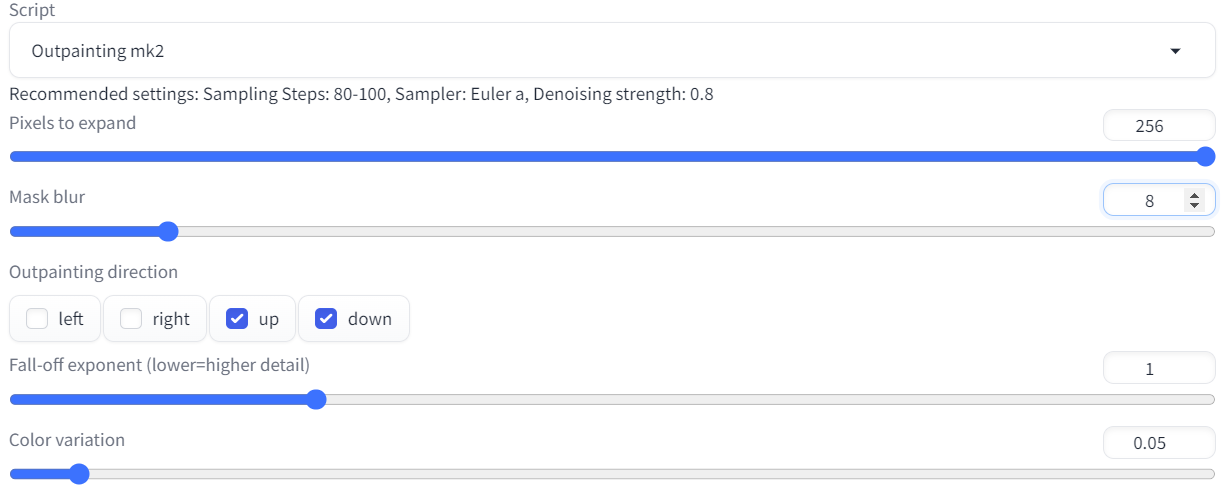
一种使用场景是当相同的prompt无法在指定图像长宽比例生成对应的内容时,如 1024X1024 产生正常内容,而相同的prompt在 1024x1536 中可能产生多个主体,此时可以使用Outpainting进行在 1024X1024 的大小进行外拓展,以在期望图像比例达到类似的效果。
一种方法是在 img2img 的 tab 中使用 script 的 Outpainting mk2,如下图设置将 1024X1024 的图片展成 1024X1536 的图片:
结果图如下,当然我对其中不合理的倒影部分进行了 Inpainting :

Gif效果展示:

Script
prompt matrix
貌似是使用在prompt中使用语法|prompt1 | prompt2 | prompt3,然后进行抽奖。
手部调整
参考:https://www.youtube.com/watch?v=f7zanMM2FEc
embedding(textural inversion)
有的是面向通用模型,有的只是针对特定模型,结合prompt matrix进行。
LyCORIS/LORA
基于LyCORIS或者LORA模型控制:
如:
- GoodHand系列