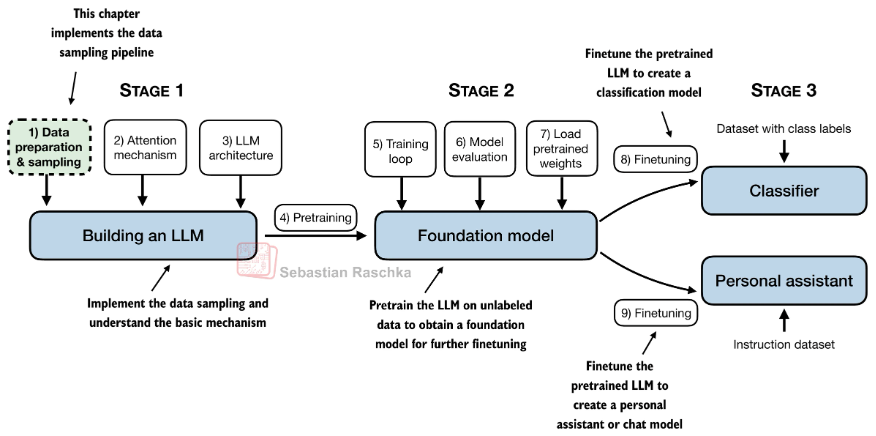
Stage 1
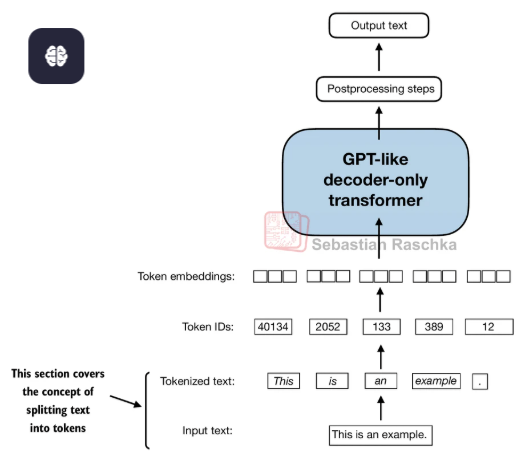
创建词表
联系:
- 输入的文本需要被转化成Token
- 每个Token会对应词表的一个Token ID
- 这个ID可以用nn.Paramater(),这个本质上就是一个可以训练的矩阵,矩阵的行是词表的数量,矩阵的宽是Token embeddings(嵌入)的特征维度。
- 用nn.Parameter()实现的话好处就是直接通过Token ID来访问矩阵的第ID行特征,速度快,nn.Parameter()一般是用高斯分布进行初始化。
- 也可以使用nn.Linear()来实现Token embeddings,除了有bias之外,使用nn.Linear的好处是有更好的初始化,比如Xavier初始化或者Kaiming初始化。
- Xavier 初始化(适用于 tanh/sigmoid 激活),核心是让输入和输出的方差尽可能一致。
- Kaiming 初始化(适用于 ReLU/LeakyReLU 激活),核心是针对 ReLU 类激活函数的「死神经元」问题优化。
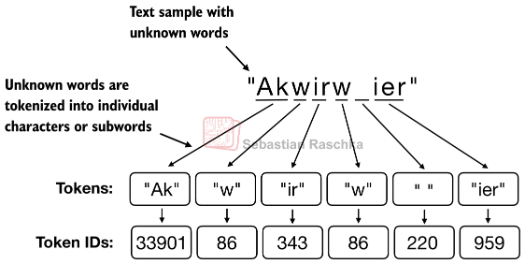
一些换行,或者结尾,以及没见过的会进行特殊编码,举例如下:

这些特殊编码会被add到Token Id的最后:

BytePair encoding(BPE编码)
实际中,这些token Id并不是简单的对单词进行one-hot编码,而是将单词进行拆分,然后根据字符结合的频次进行编码,这个技术叫做BPE编码:
- 先把所有词拆成单个字符。
- 统计所有相邻字符对的出现频次。
- 把频次最高的那一对,合并成一个新符号。
- 重复步骤 2–3,直到达到你想要的词表大小。
至于和字节的关系则是因为,他把单词拆成字节的基础单元,也就是将通过字节编码(UTF-8/ASCII)映射字符串,无论是中文还是英文。合并高频字符串的本质就是合并高频字节对。
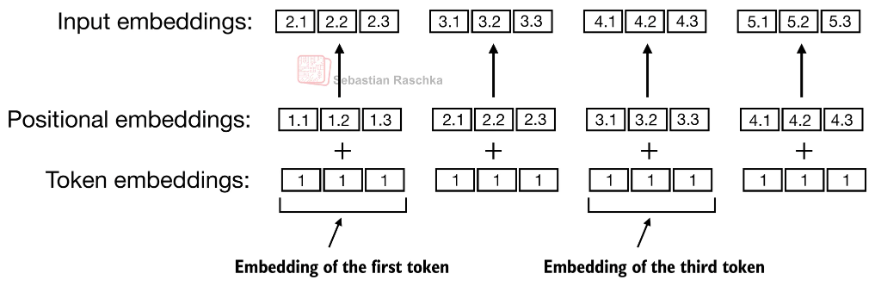
位置编码
另外这些token embedding还需要有一个位置编码信息才会被送进网络:
如果训练是一个文本预测任务,所以dataloader可以使用滑动窗口来采样训练数据:

Stage 2
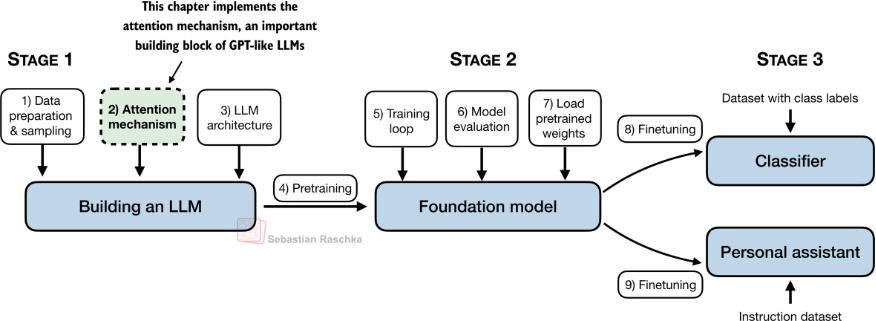
Self-Attention
每个token embedding通过不同的可学习的权重矩阵分别计算得到QKV,然后QK得到一个注意力矩阵,再和V进行相乘得到V。
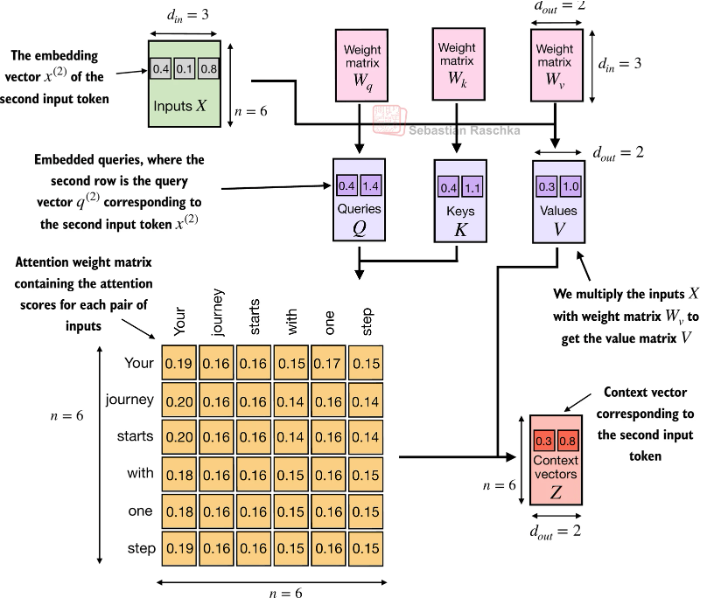
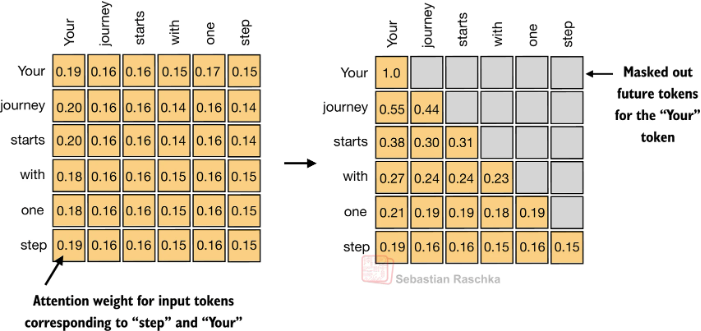
Causal self-attention(因果注意力)
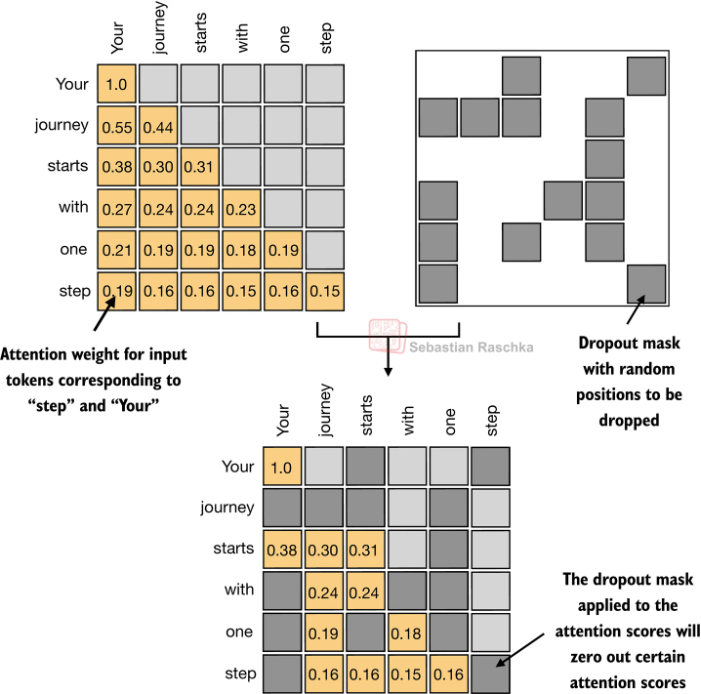
构建一个上三角掩码矩阵(下三角可见、上三角不可见),遮挡掉当前 token 对「未来位置」的注意力计算;计算注意力权重时,被掩码的位置权重会被设为极小值(如 -1e9),经过 Softmax 后几乎为 0,相当于 “看不见” 未来信息。
Dropout
在实际操作中还可以通过Dropout来减少过拟和。
实现1(CausalAttention)
1 | class CausalAttention(nn.Module): |
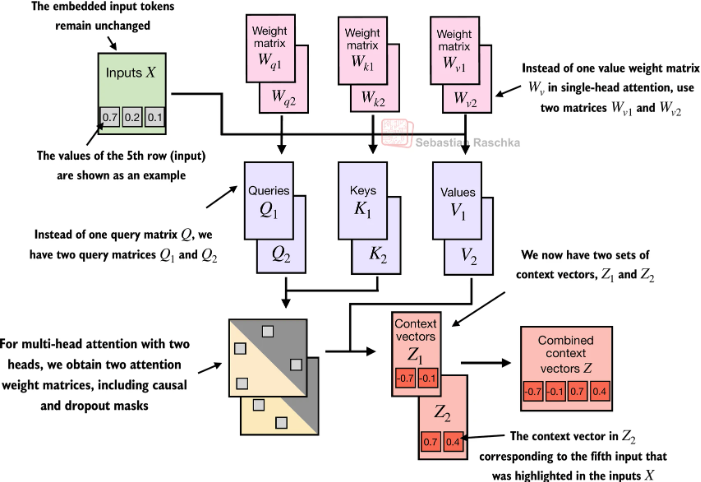
多头注意力
把注意力分成多组,让模型同时从不同角度、不同子空间去理解语义。实现上就是通过多组的Wq,Wk, Wv来实现不同子空间的映射。
实现2(stack多个头)
1 | class Ch03_MHA(nn.Module): |
实现3(Combined Weight)
1 | class MultiHeadAttentionCombinedQKV(nn.Module): |
实现4(einsum)
1 | class MHAEinsum(nn.Module): |
实现5(flash-Attention接口)
1 | class MHAPyTorchScaledDotProduct(nn.Module): |
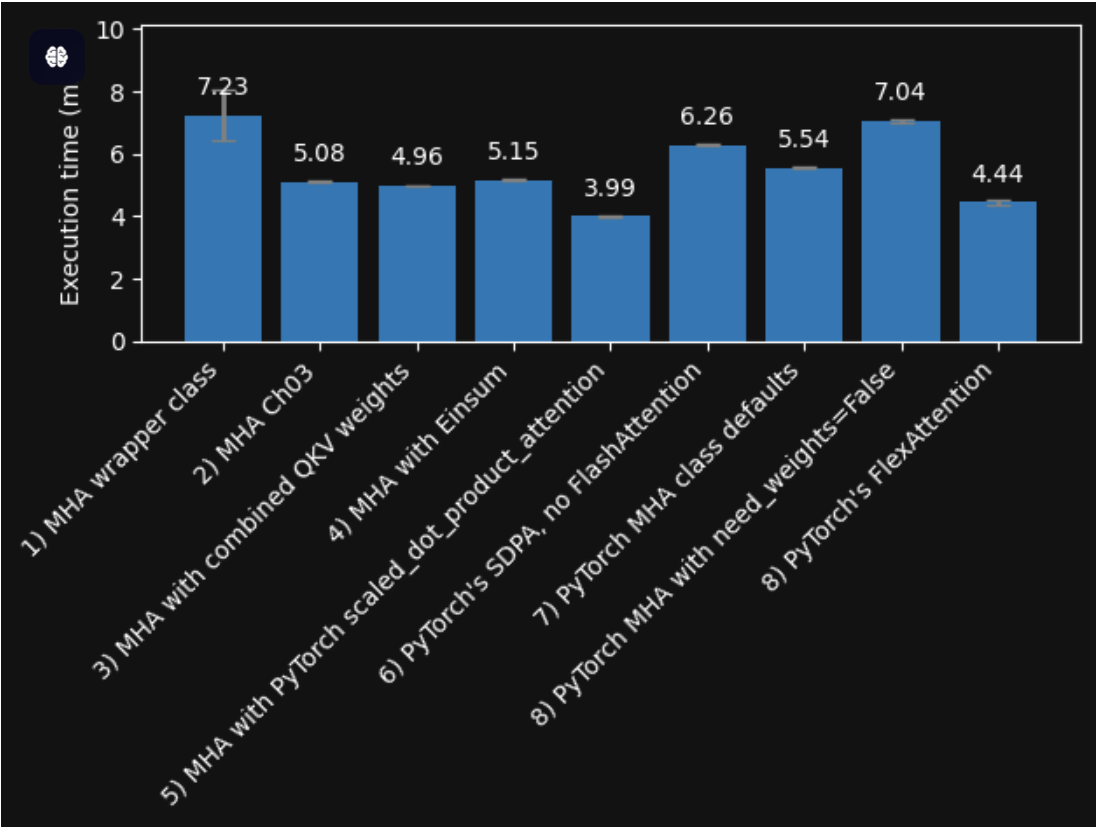
性能对比
Speed comparison (Nvidia A100 GPU) with warmup and compilation (forward and backward pass)
compilation(编译) 指的是「将 PyTorch 等框架的动态图代码,编译为 GPU 可直接执行的优化机器码」的过程,是实现 FlashAttention 这类高性能算子加速的核心步骤。